官网截图
sharding JDBC 3.0 => shardingsphere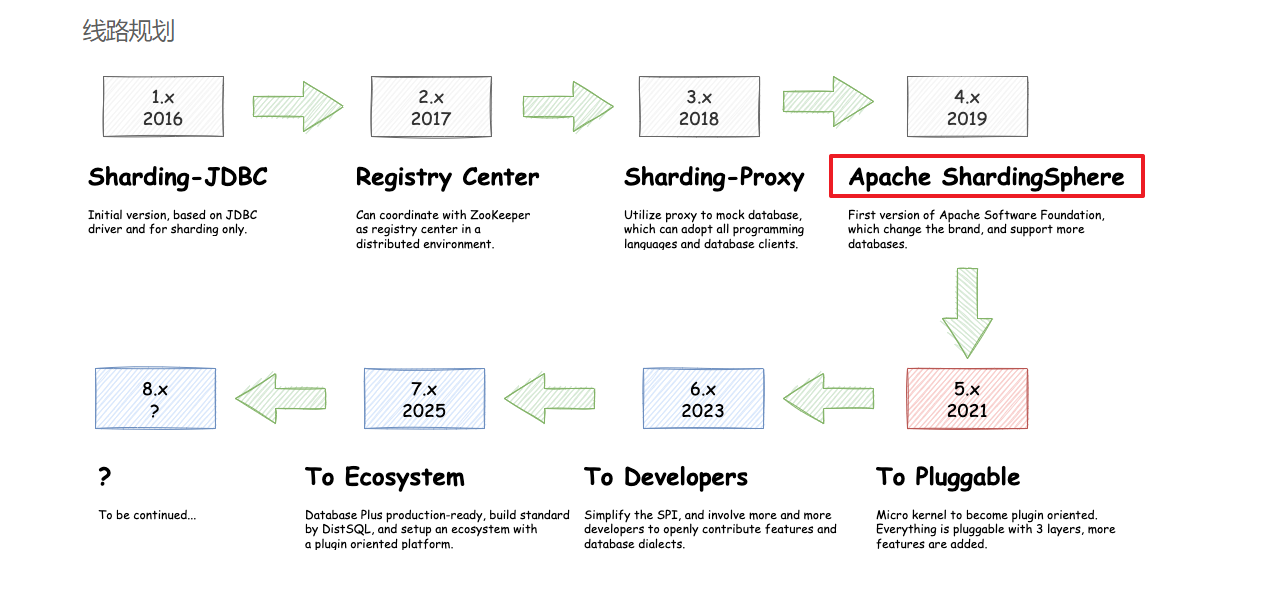
shardingJDBC应用融合
mycat 是独立于应用之外的。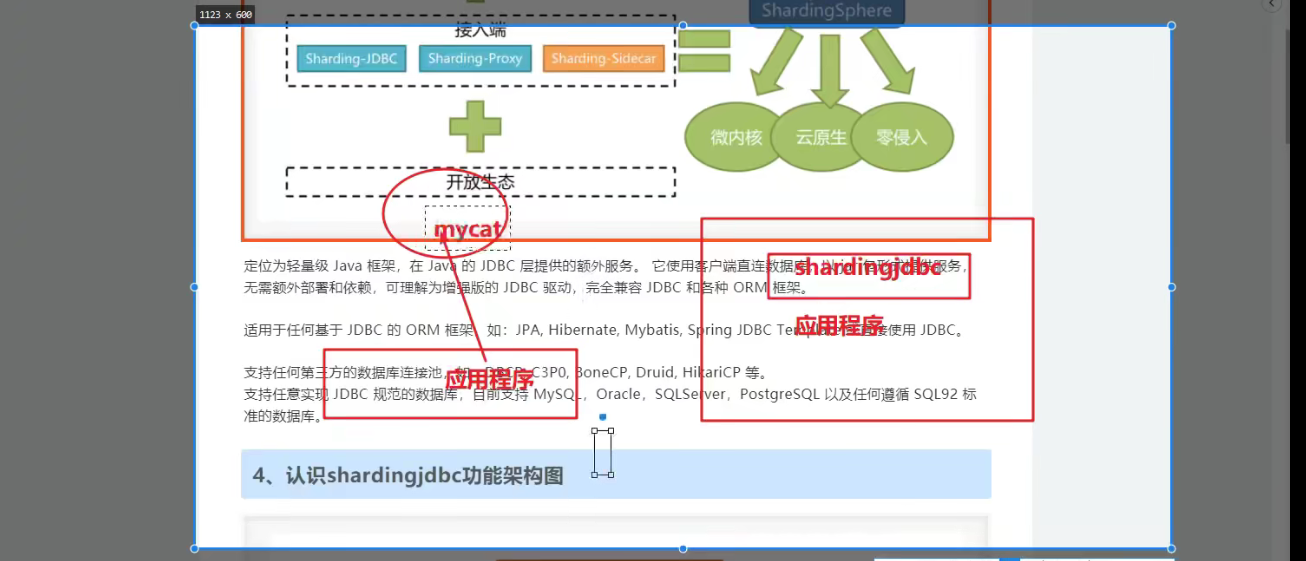
连接池
不需要开辟tcp,mycat 独立于应用之外,需要开辟tcp连接,会耗性能的。
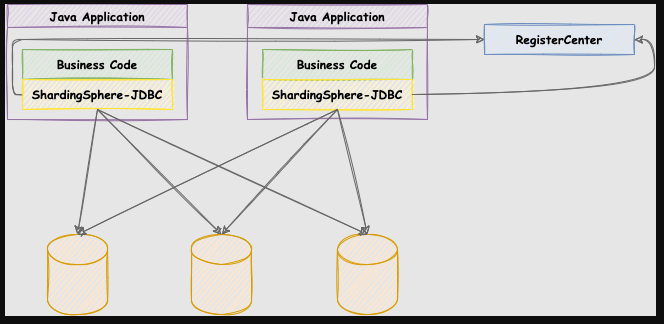
shardingJDBC 有连接池管理连接。shardingJDBC 底层管理这些连接,拿到 sql 进行取余啊,匹配到哪个连接。
(通过名称也可以理解,就是 JDBC 的连接分片。)
配置中心的概念
这些 JDBC 的连接,都会注册到 注册中心里面去。达到共享连接的作用。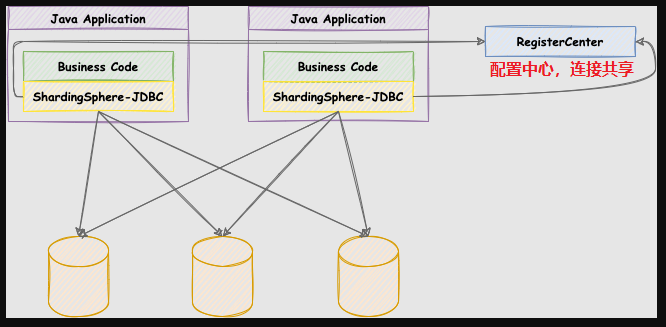
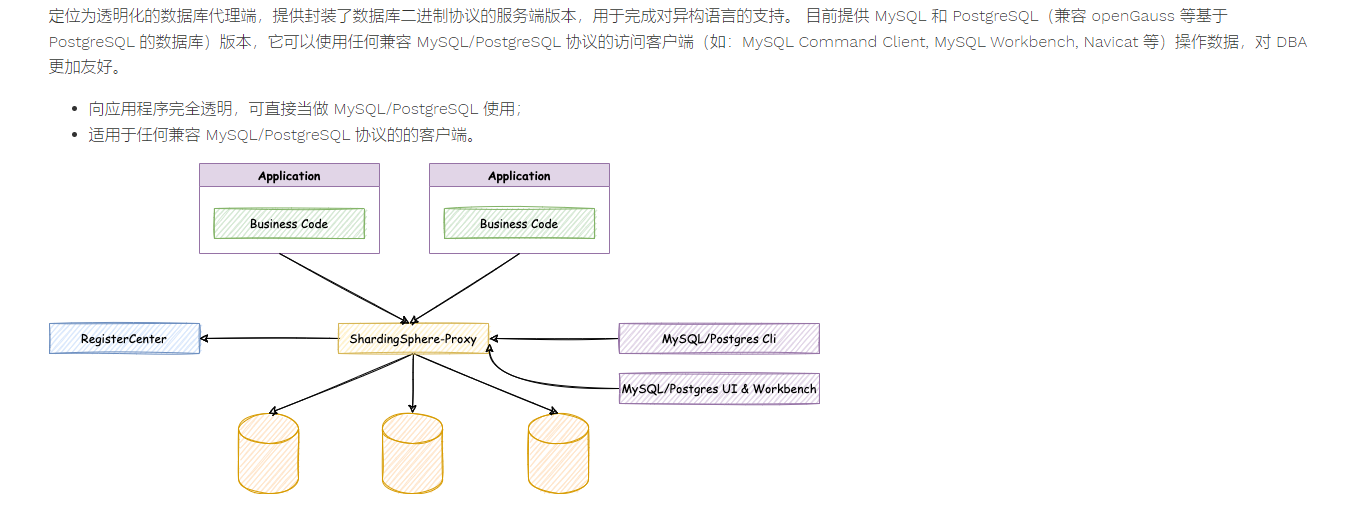
sharding Proxy
类似于 Mycat 作为中间件,来托管一下连接。
sharding proxy,也可以注册到 注册中心去。底层来连接 MySQL。
(sharding proxy 相当于对 sharding JDBC 的一层代理。)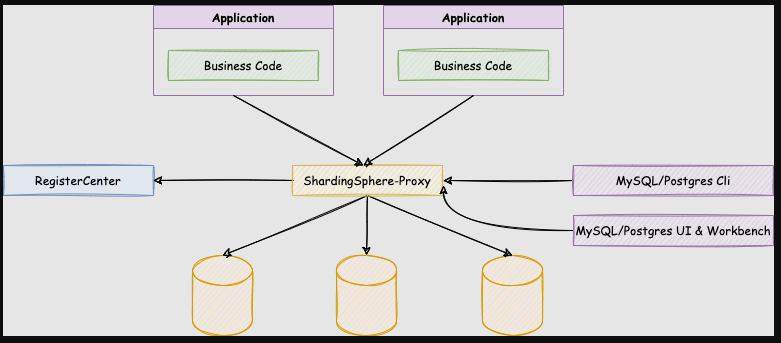
三个组件
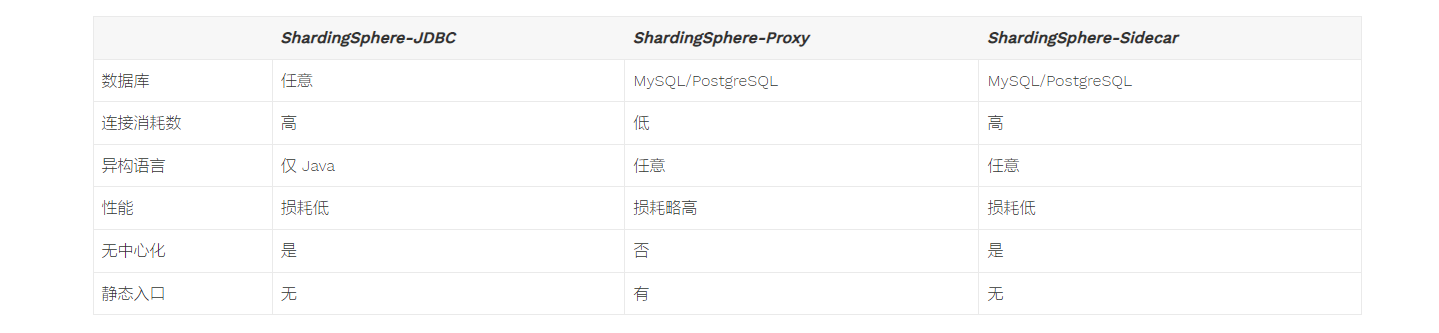
sharding-sidecar 相当于做:分布式治理(可视化链路追踪),监控连接的健康状况。
proxy:损耗高,因为网络。
jdbc:每个应用都要有连接池,proxy 就是维护很多应用的连接池。做到复用(这个很重要,所以所 jdbc、和 proxy 融合为 shardingsphere)。
混合架构: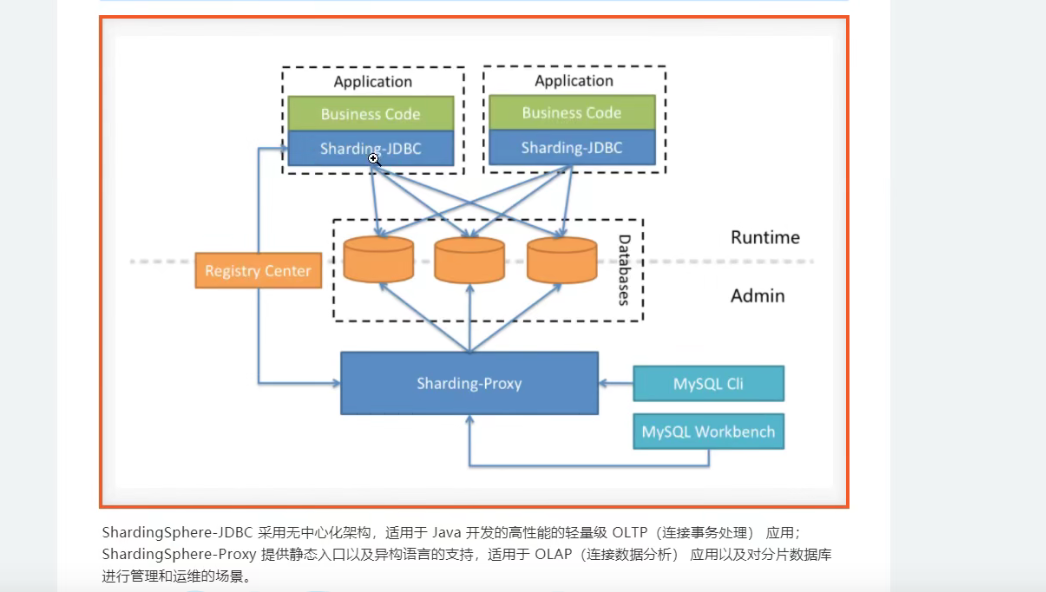
shardingsphere 底层执行流程
可参考官网的核心概念:ShardingSphere > Features 特点> Sharding 分片 > Core Concept 核心概念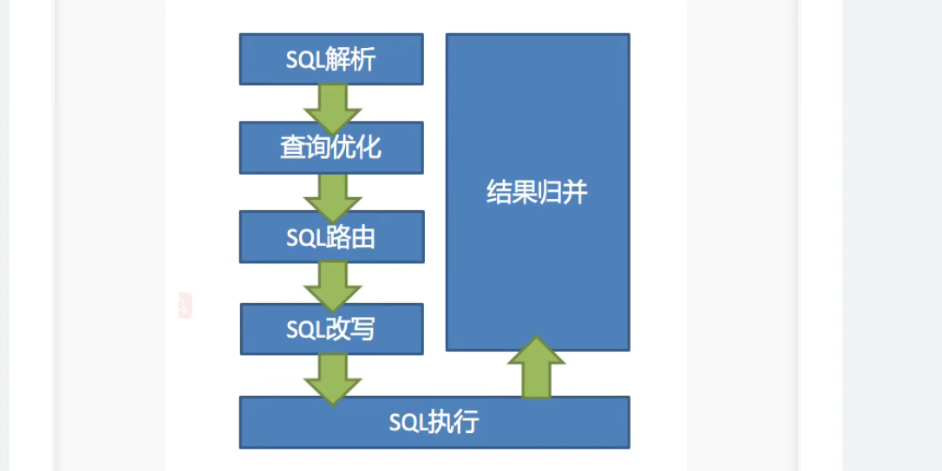
主从复制,读写分离
1、实现读写分离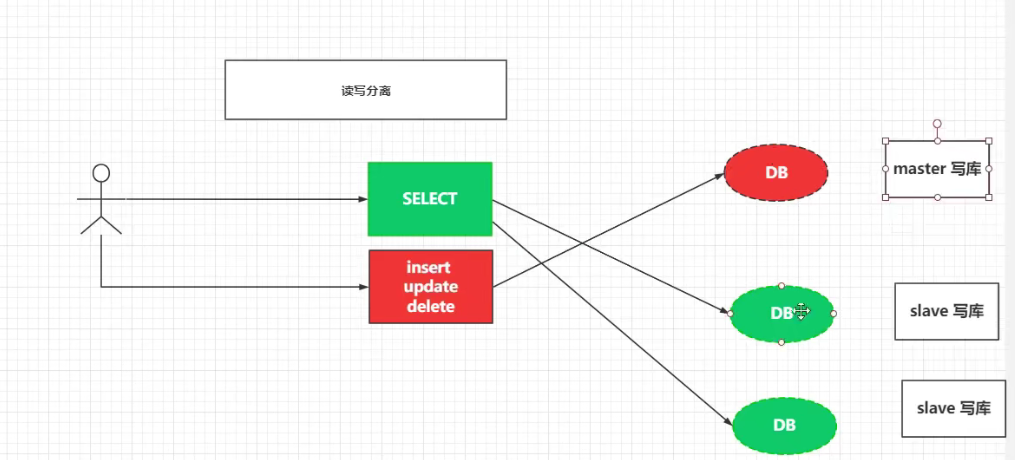
2、上面的图片会存在一个问题,那就是数据不一致的问题。master 写了,但是你读取到的 slave 库上面还是旧的数据。
所以,这里就是需要主从复制。(为了保证数据的一致性问题。)
主从复制:数据层面的东西。
读写分离:业务层面的东西。
所以,这里用读写分离,就要用到主从复制,来保证数据的一致性。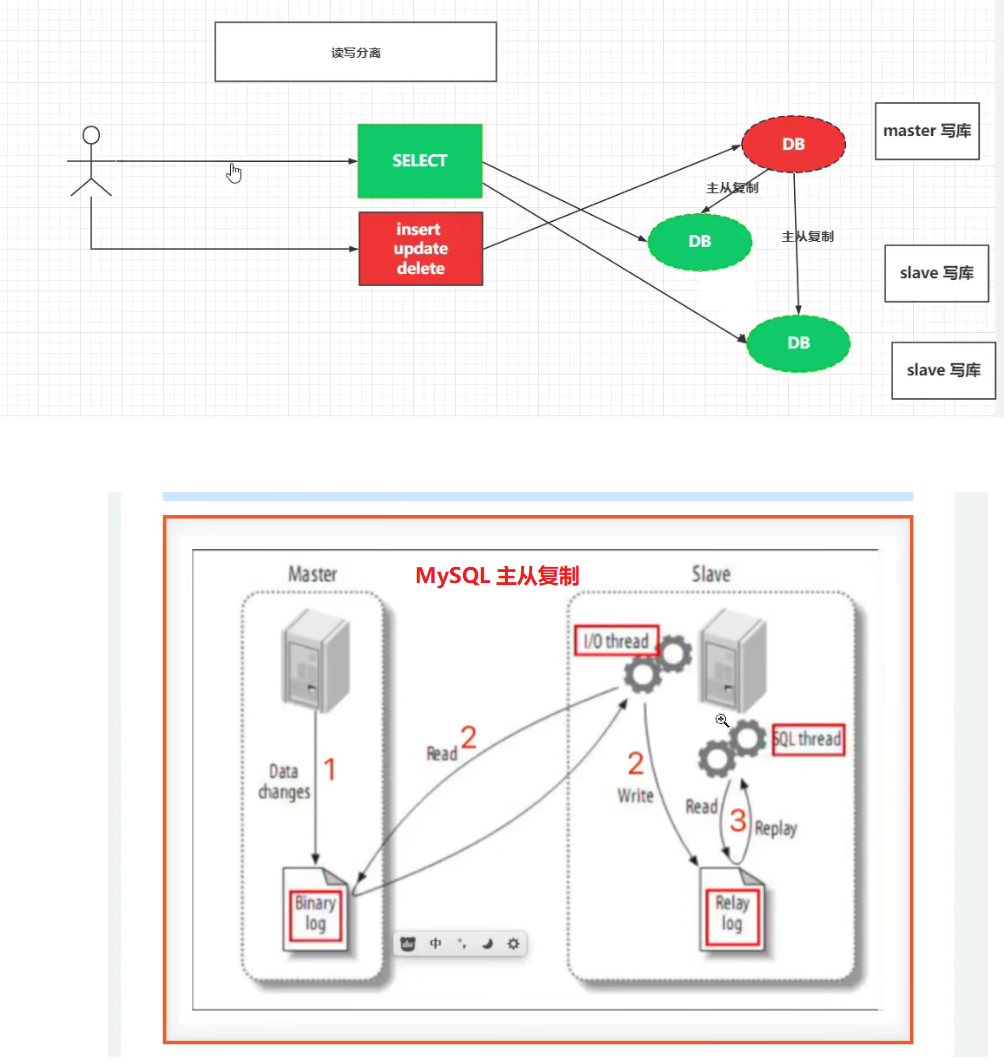
3、为什么要读写分离呢?
一个网站可能存在 80%的读,20%的写。这些读呢,可能就是看一下,如果都使用一个库,可能造成压力过大。
一台服务器的性能是有物理极限的(QPS、连接数),无法提供连接就会超时,超时会导致整个网站就瘫痪了。
基于上面的原因,就只能进行减压,一旦减压就是把读库和写库分开(读写分离),一旦分开,就需要数据一致性,从而需要主从复制。
4、所以,sharding jdbc 就是做读写分离的。
注意:sharding jdbc 不能完成主从复制,它是用来做读写分离的。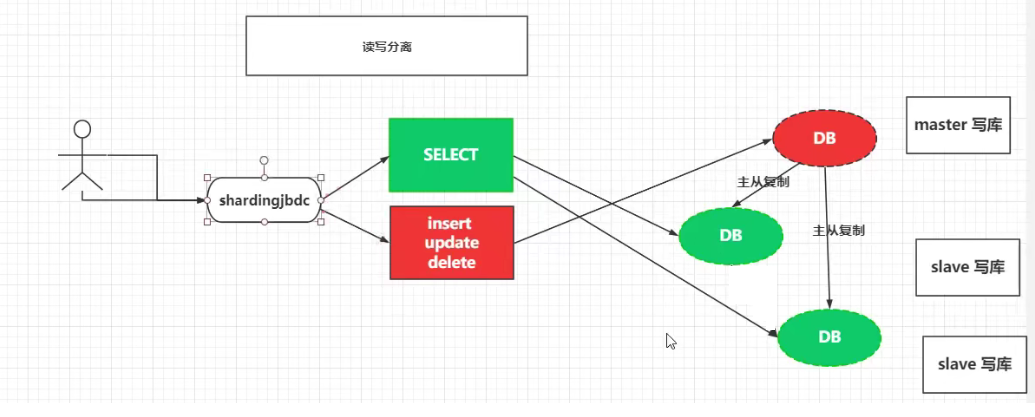
(2022-01-24 12:14:36 今天我发现,我现在看视频,梳理截图,更为友好,比看一个视频过去更好。
这样我可以写出来我看到的重点,避免了繁琐冗余的内容,又梳理了我自己认为更好的东西。方便自己来翻阅。
重点还能写一些自己的看法,做一些自己的感受,并且自己能够截图,借助 Windows 画图工具,来做出自己更方便查看和理解的图片。)
主从分离测试

为什么分库分表
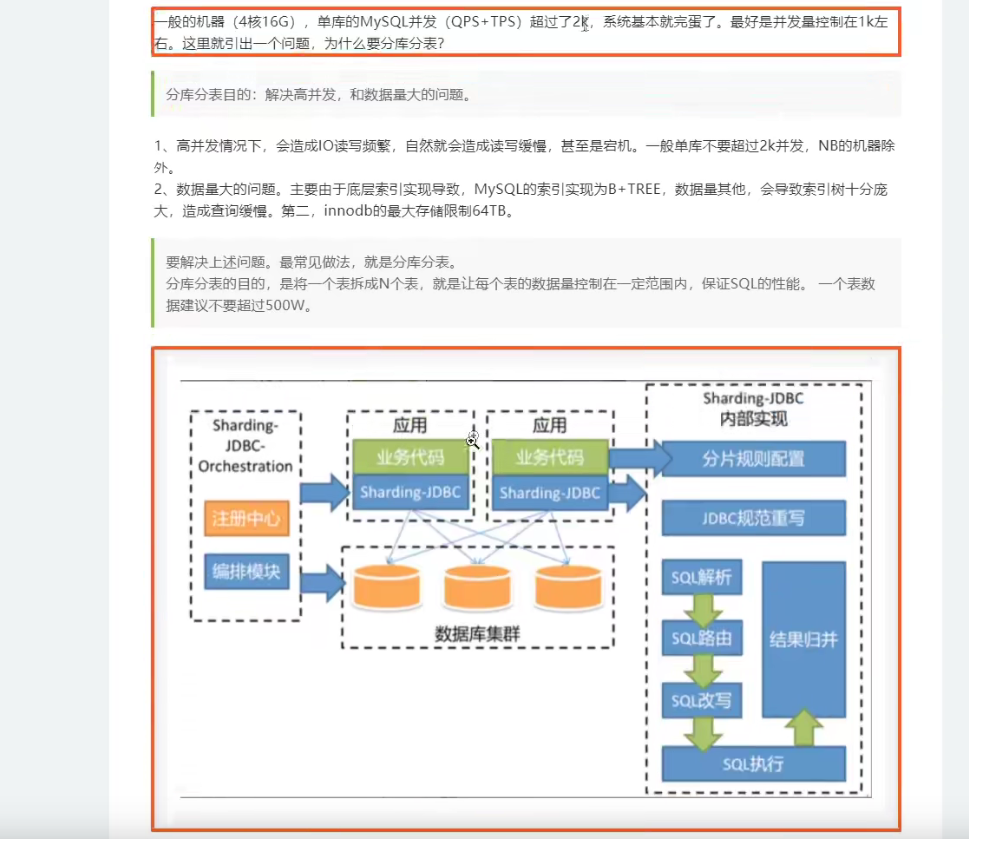
水平拆分,垂直拆分
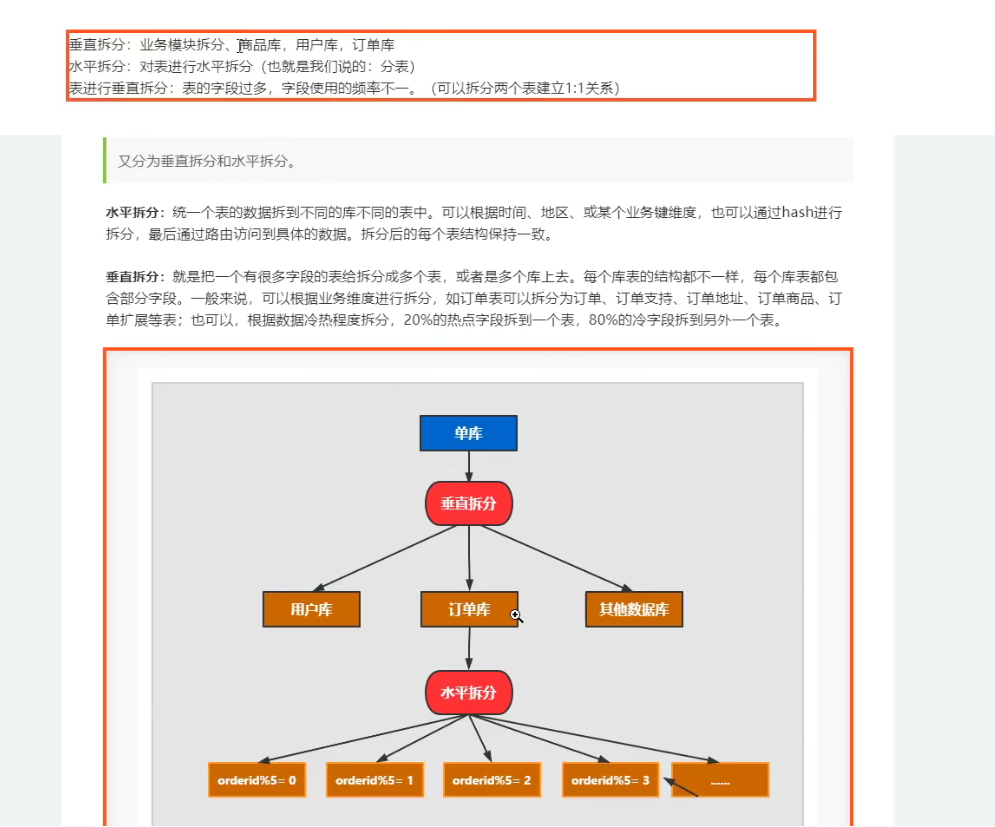
逻辑表&数据分布
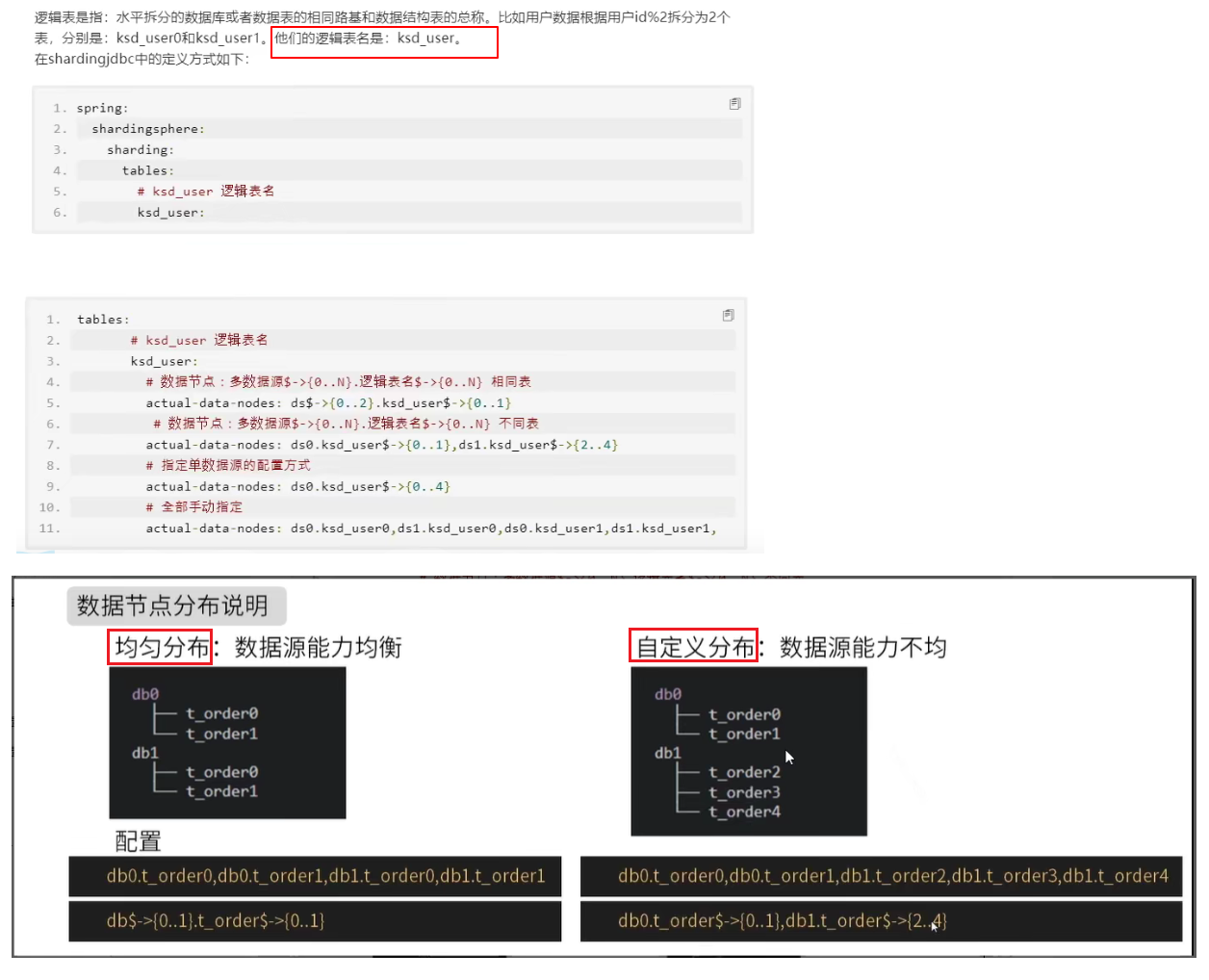
命中流程
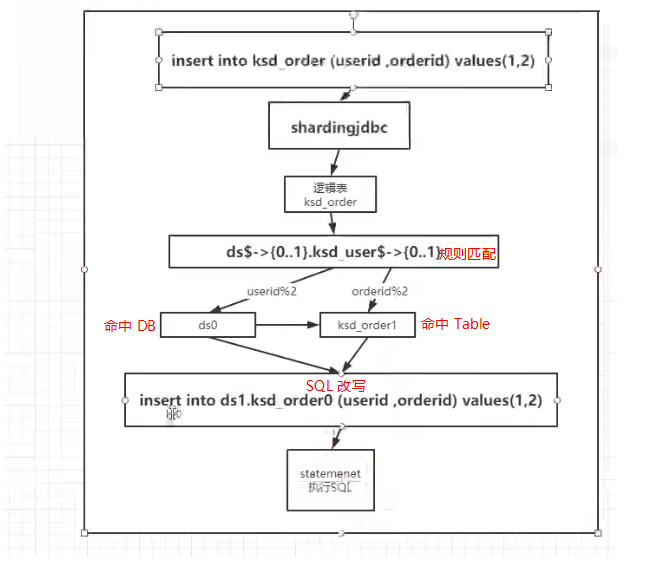
例如:下面这个虎眼石根据 user_id 分库,order_id分表。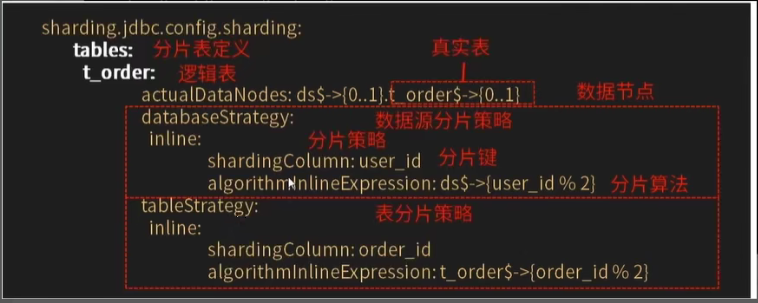
inline 分库分表
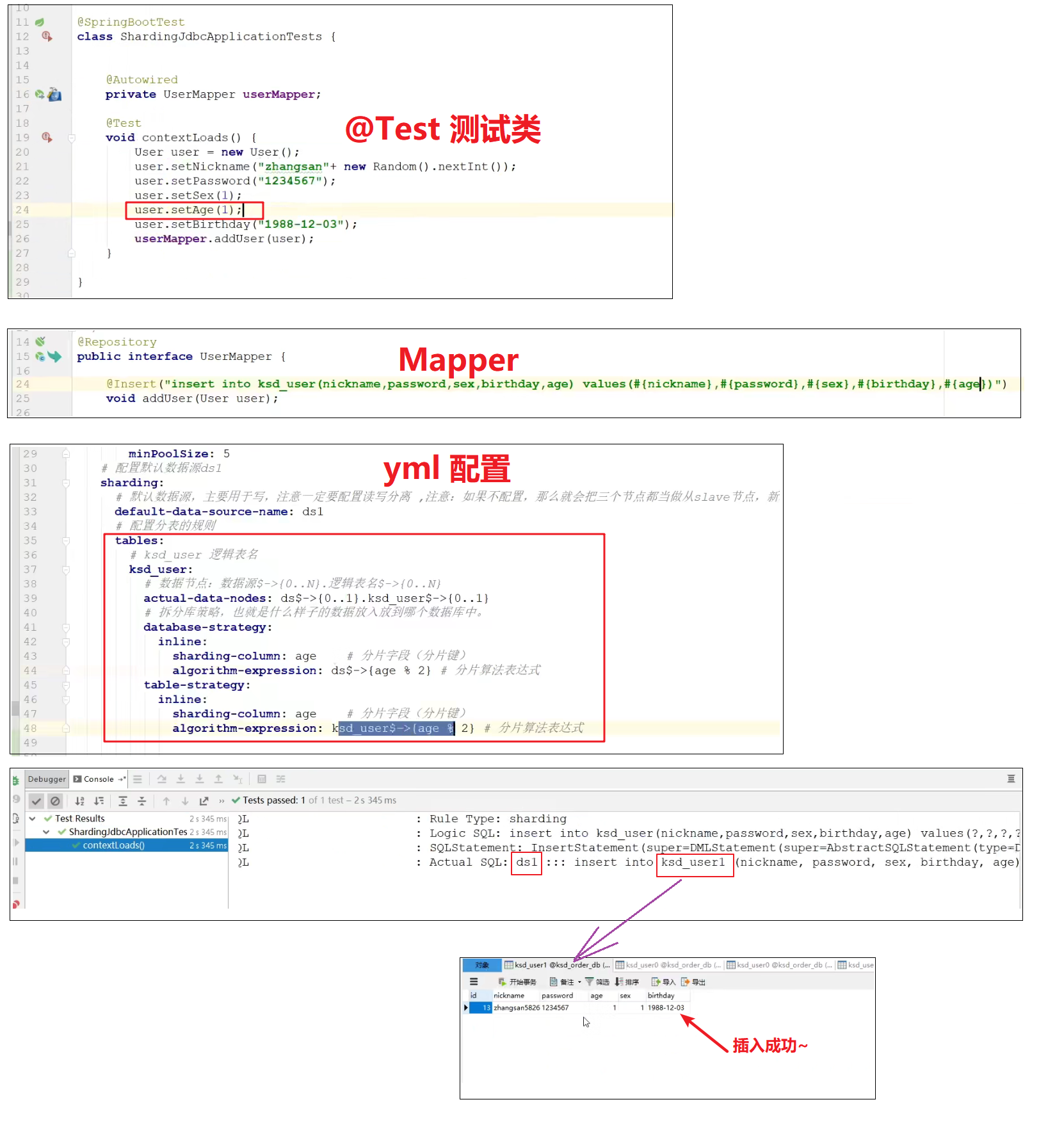

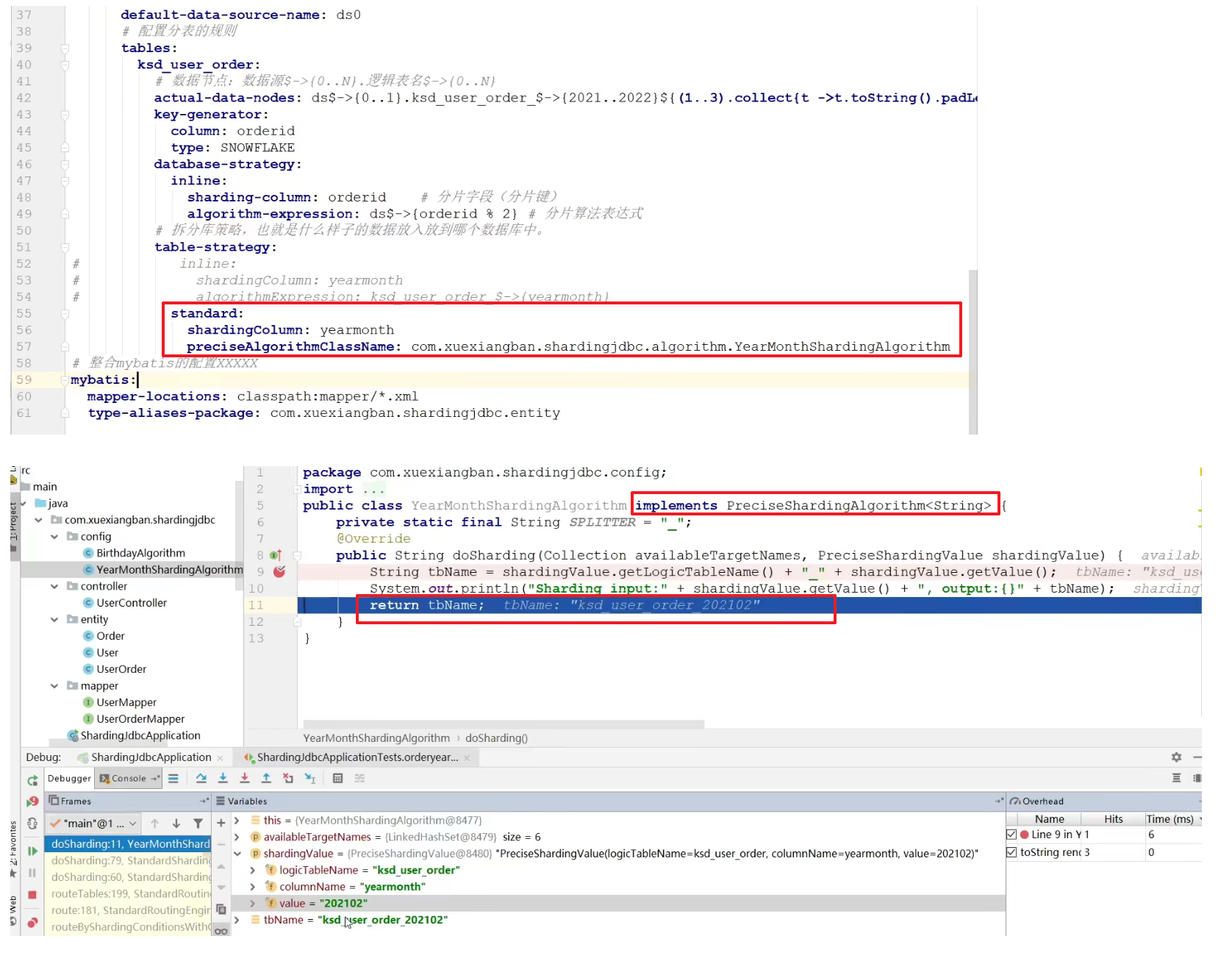
standard 自定义实现
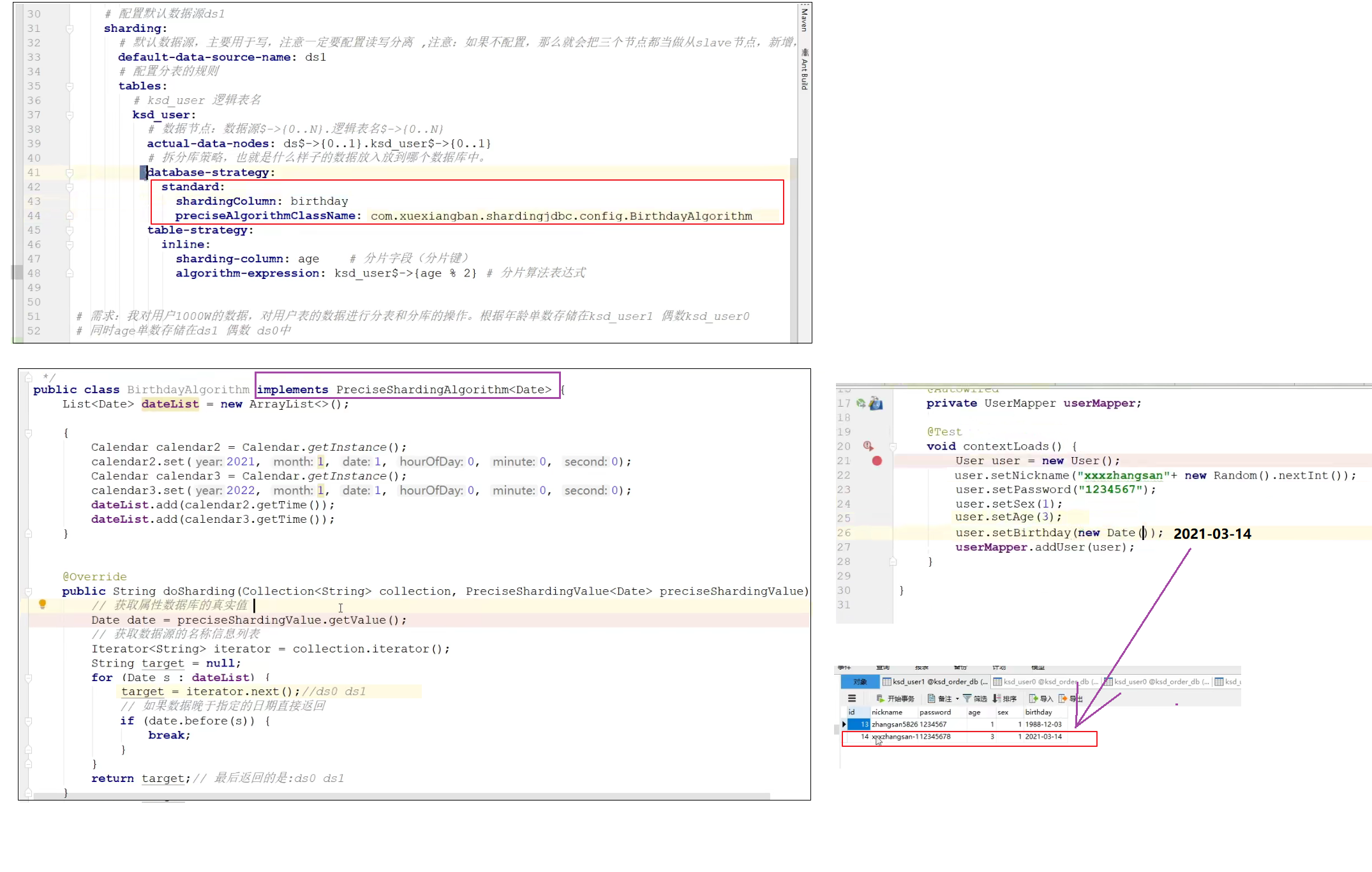
分布式主键
基于上面,我们可能会发生不同表存在主键重复的问题。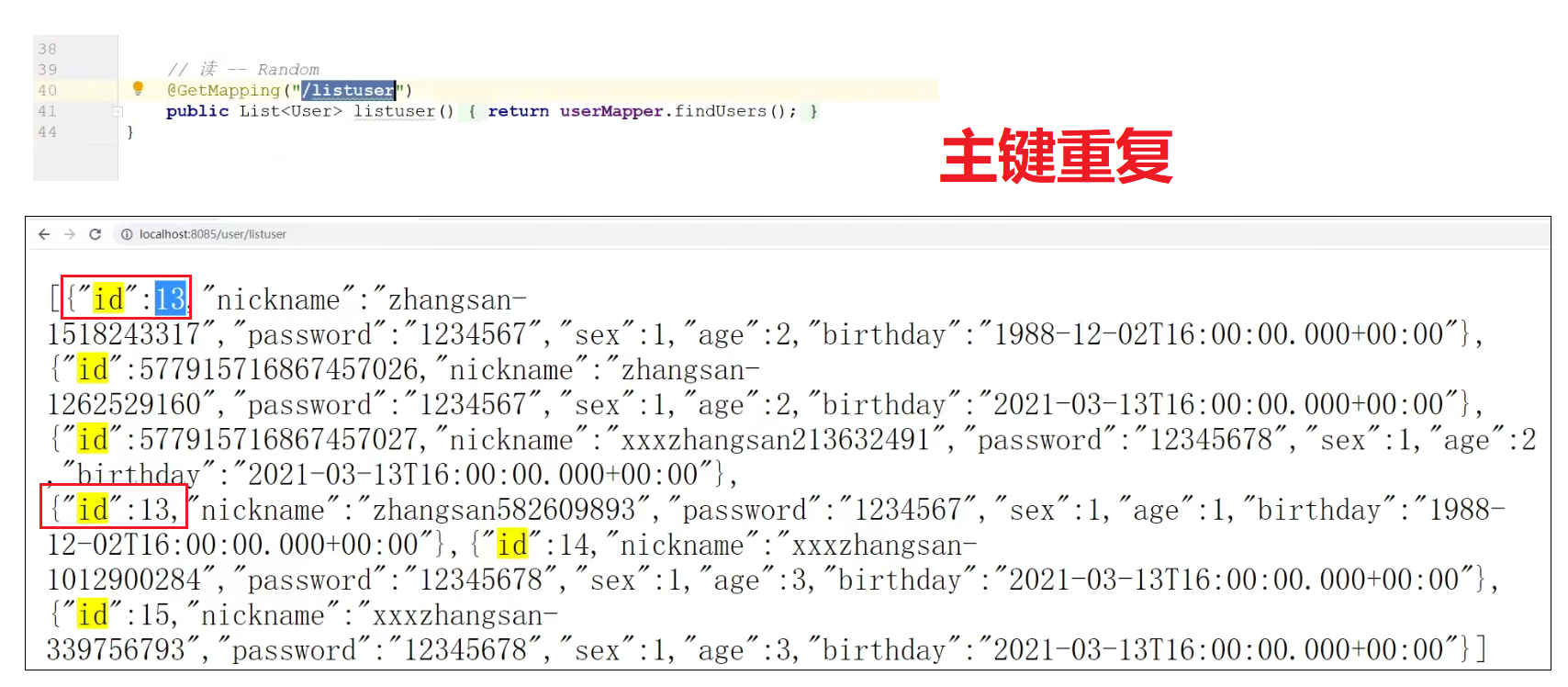
配置雪花ID生成
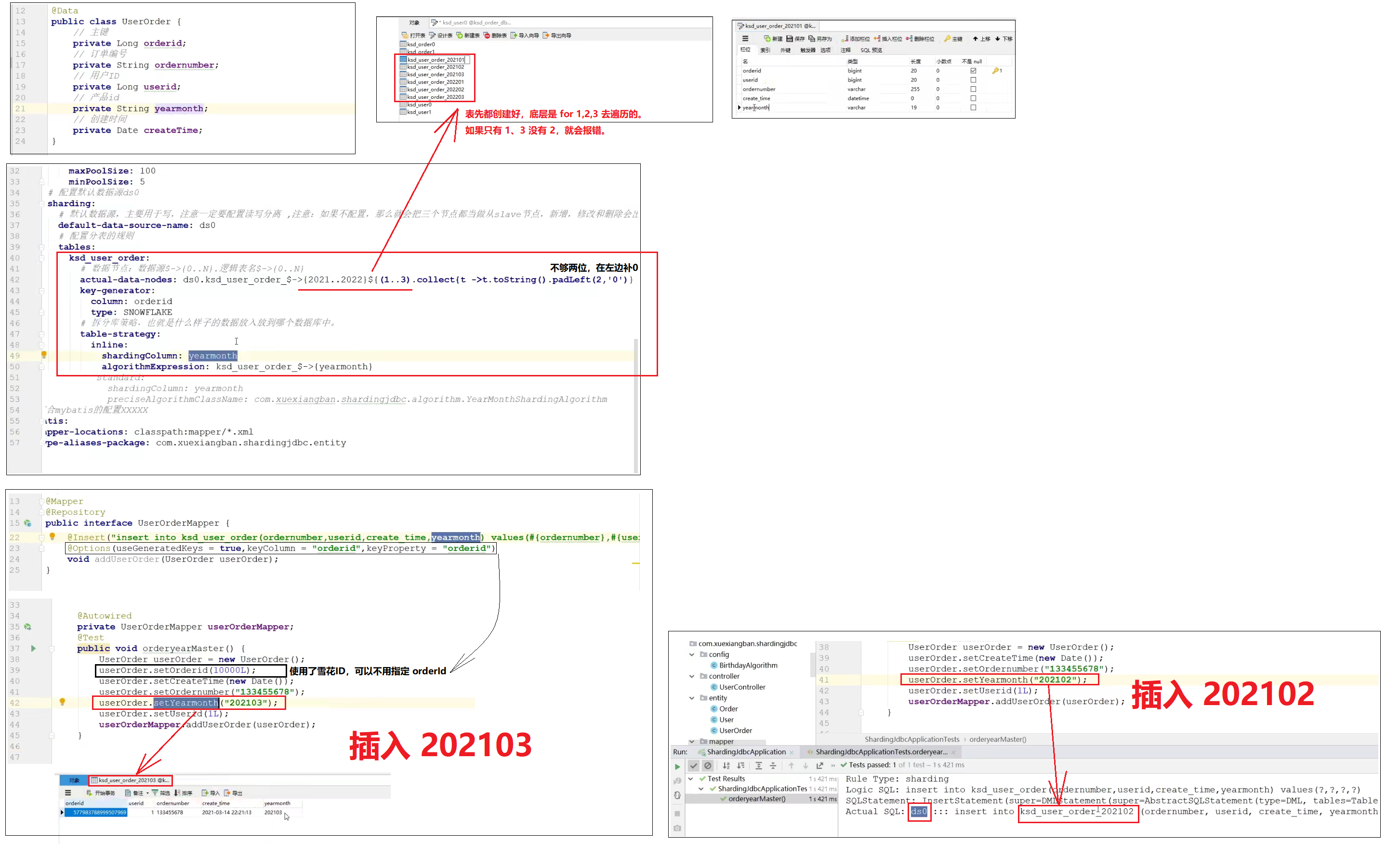
年月分库分表
下面的列子只说 123月,正常应该是 1~12 都有的。
- inline 模式
- standard
数据库规范

表的垂直拆分
拆分不一定快,有的公司一个表甚至几百个列也不进行拆分。单表永远比联表查询快n倍。
拆分可能导致不能够很好的使用到索引。
有的表,可能列是 text 类型,占用内存很多,可以进行拆分成 1对1的关系表。
如何平滑添加字段
1:项目早起可以使用,后面量大的时候就不适用了。
5:不会造成空间和性能上的浪费。