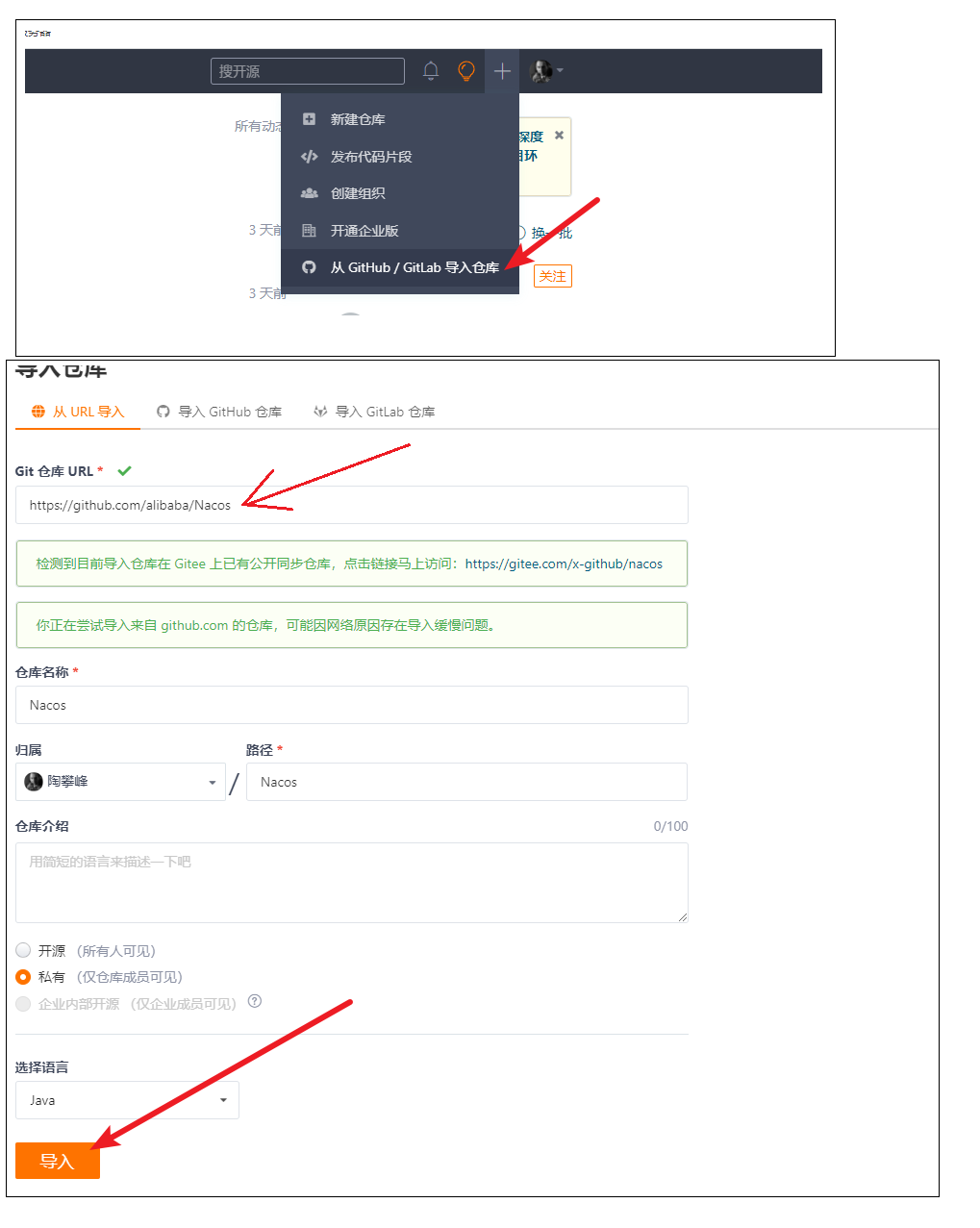
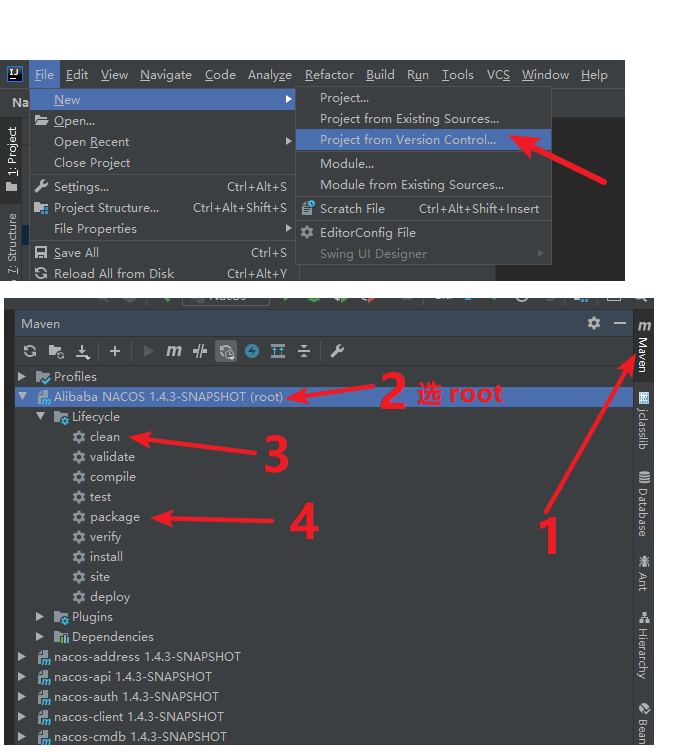
Nacos 源码下载,编译
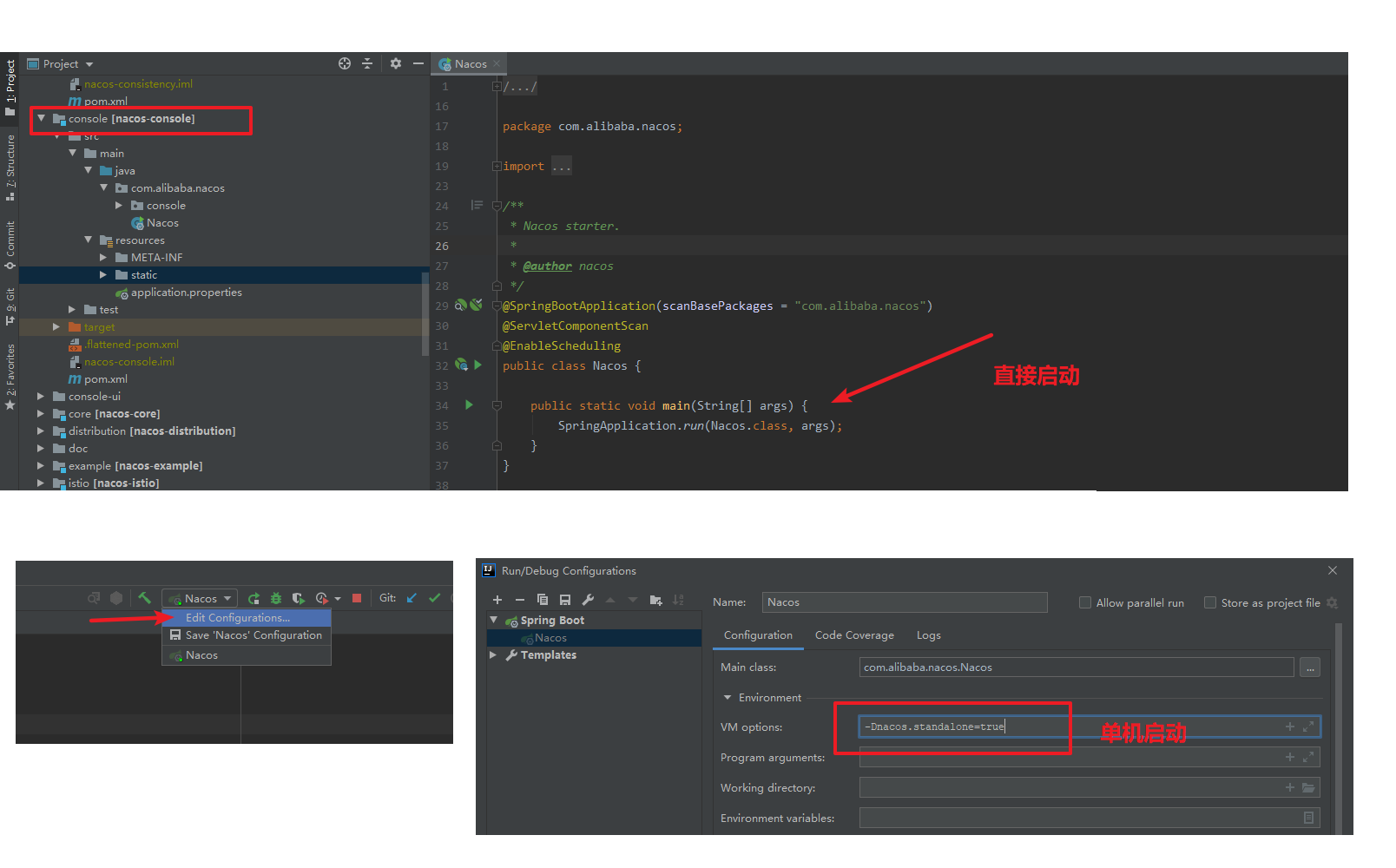
运行Server,并登录

Nacos 注册与服务发现
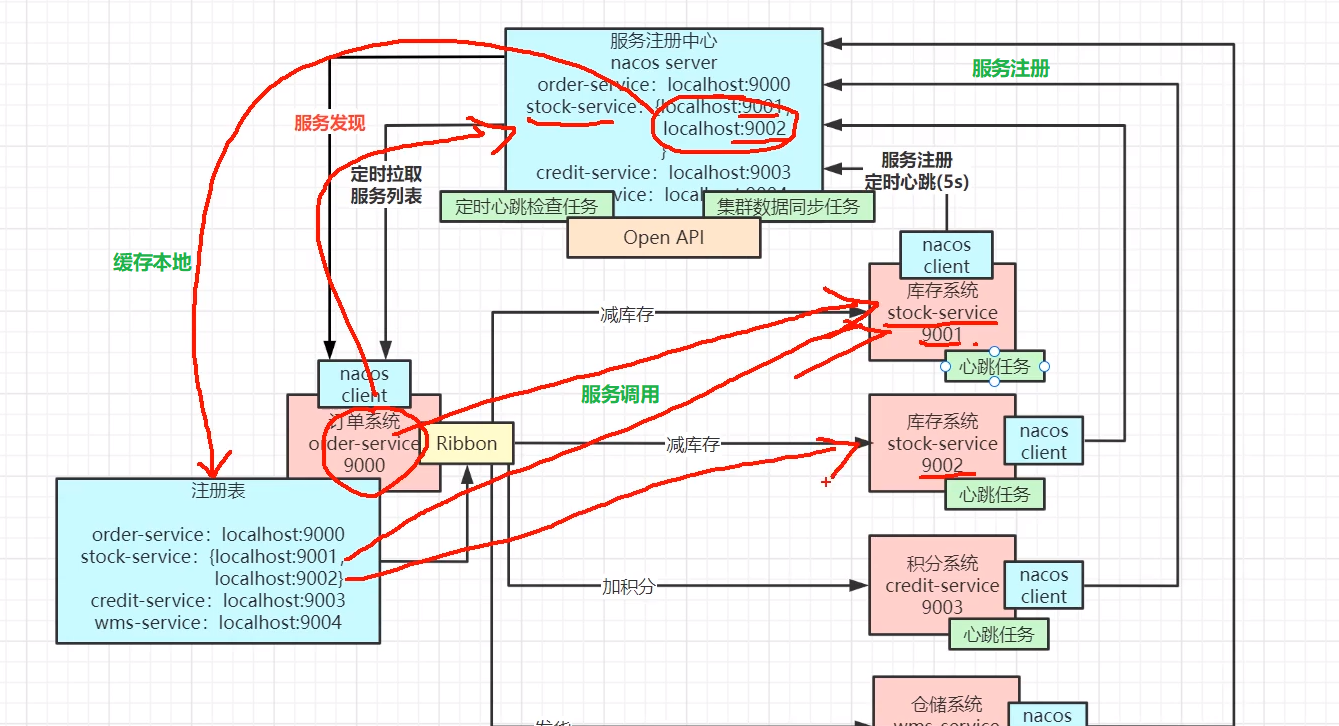
定时拉取服务列表
- 增加服务
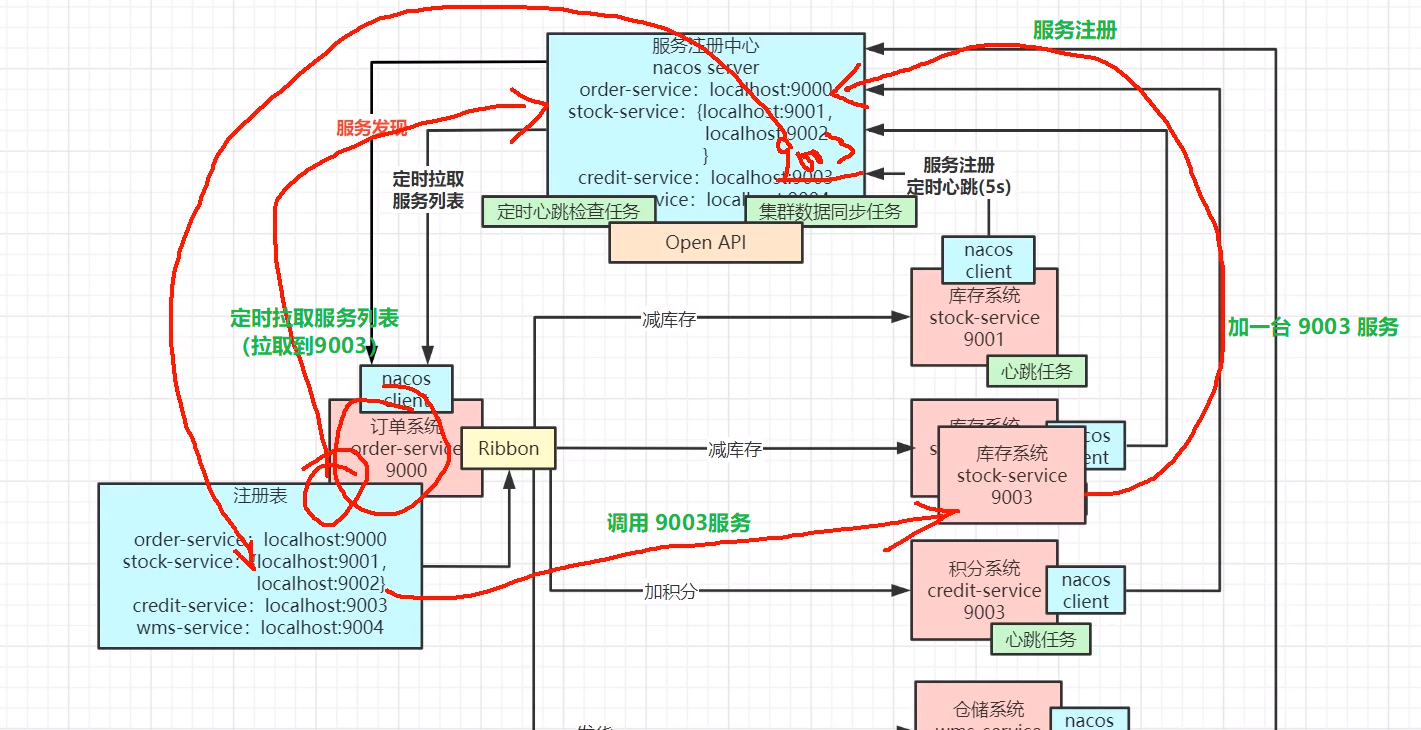
- 减少服务

测试服务上下线
1、启动 Nacos server(查看 Nacos 服务列表)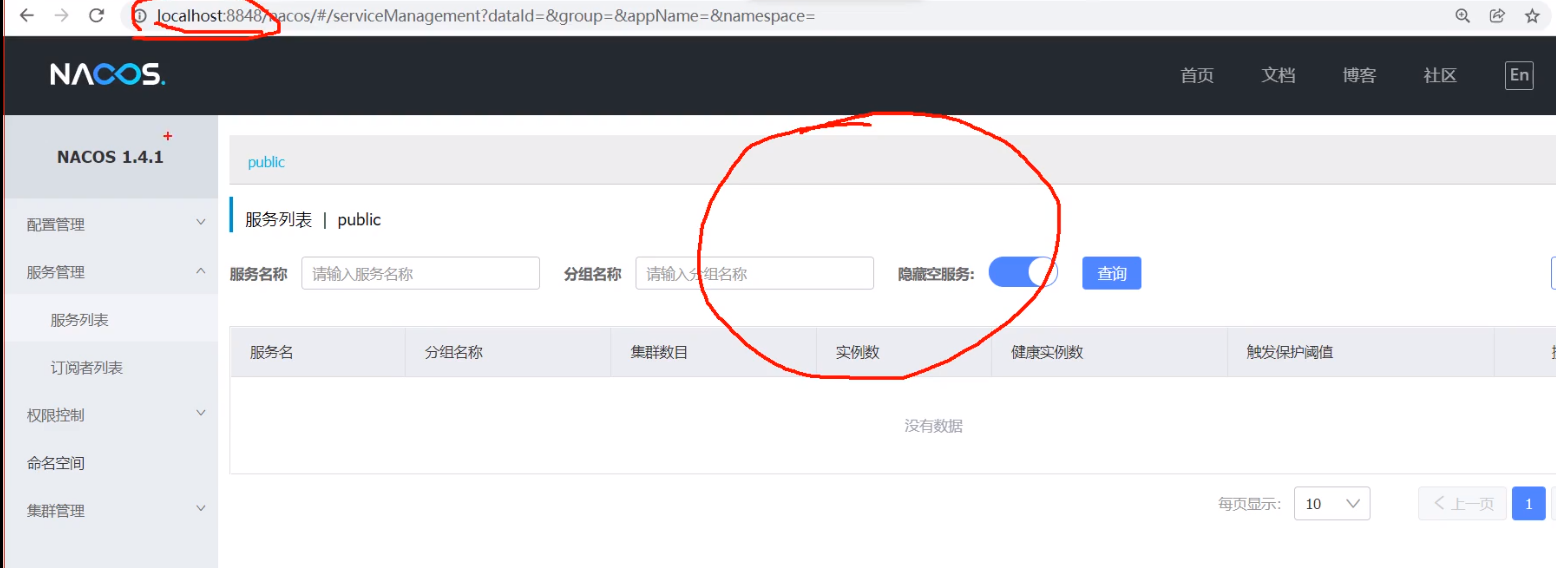
2、启动 9001 服务(查看 Nacos 服务列表)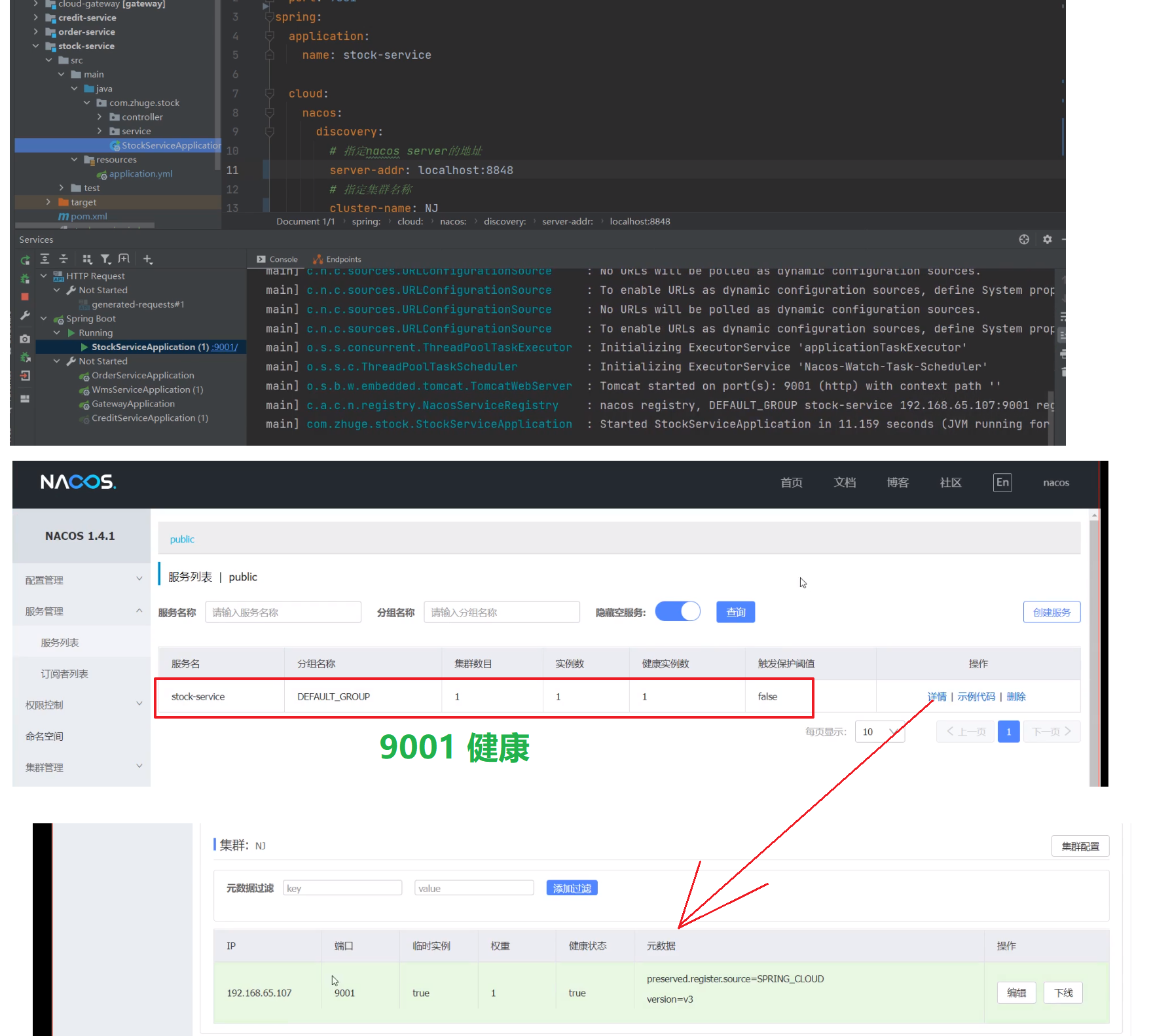
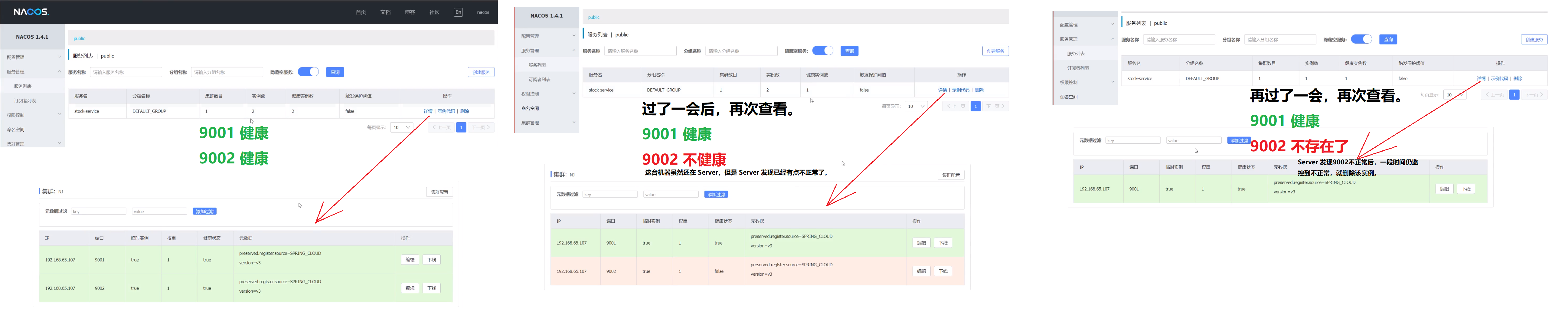
3、再启动一台9002(查看 Nacos 服务列表)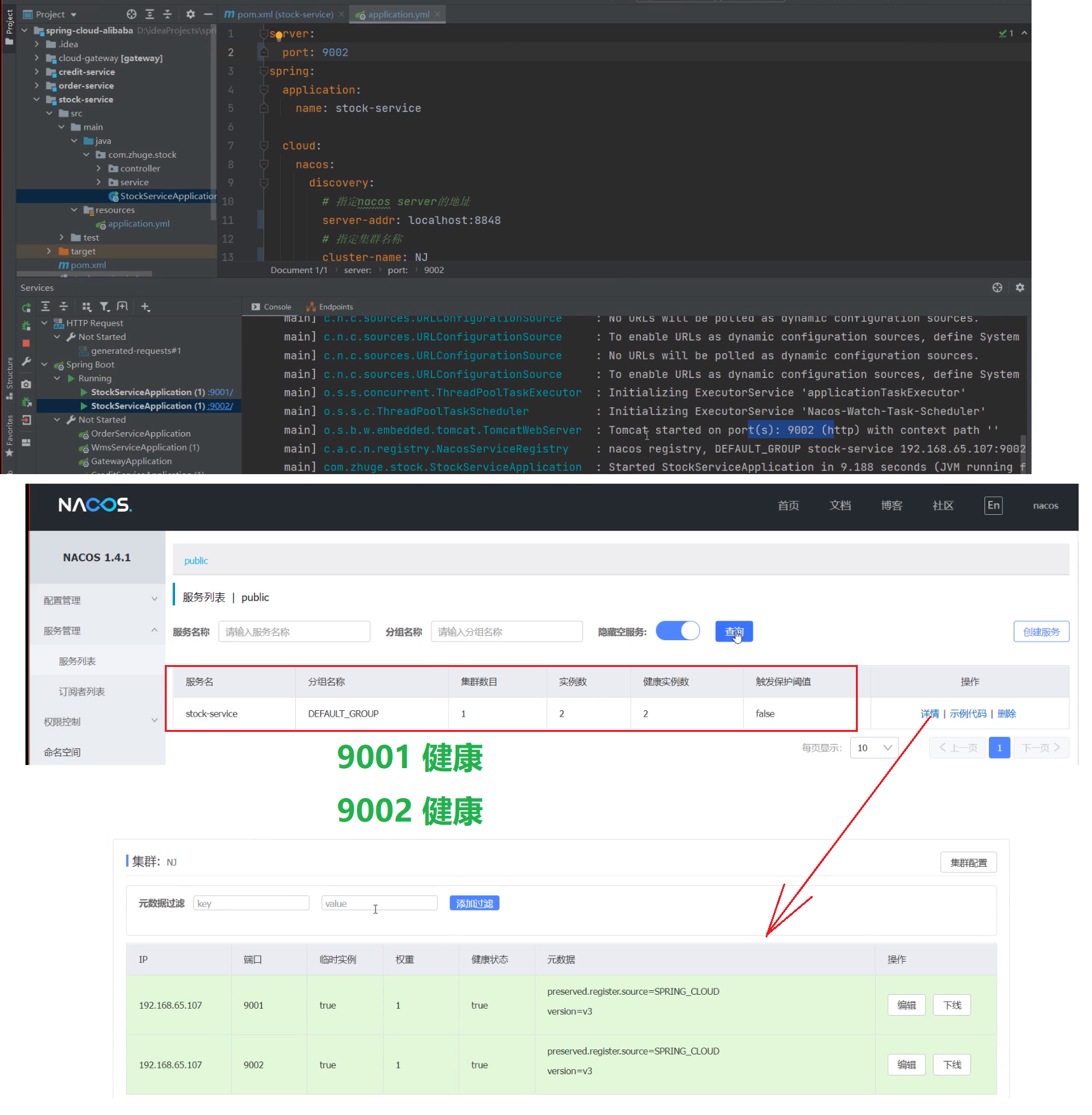
4、关闭 9002(查看 Nacos 服务列表)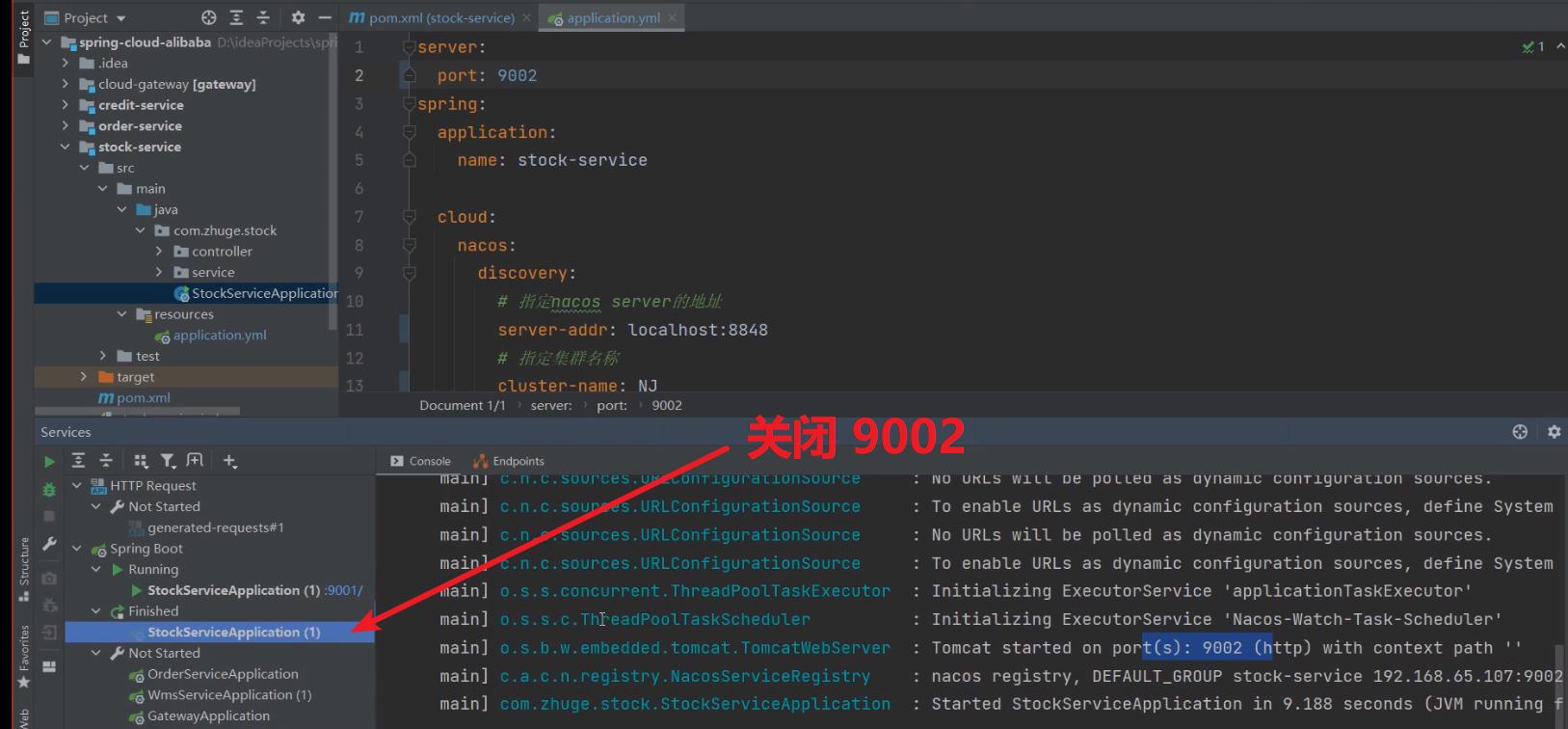
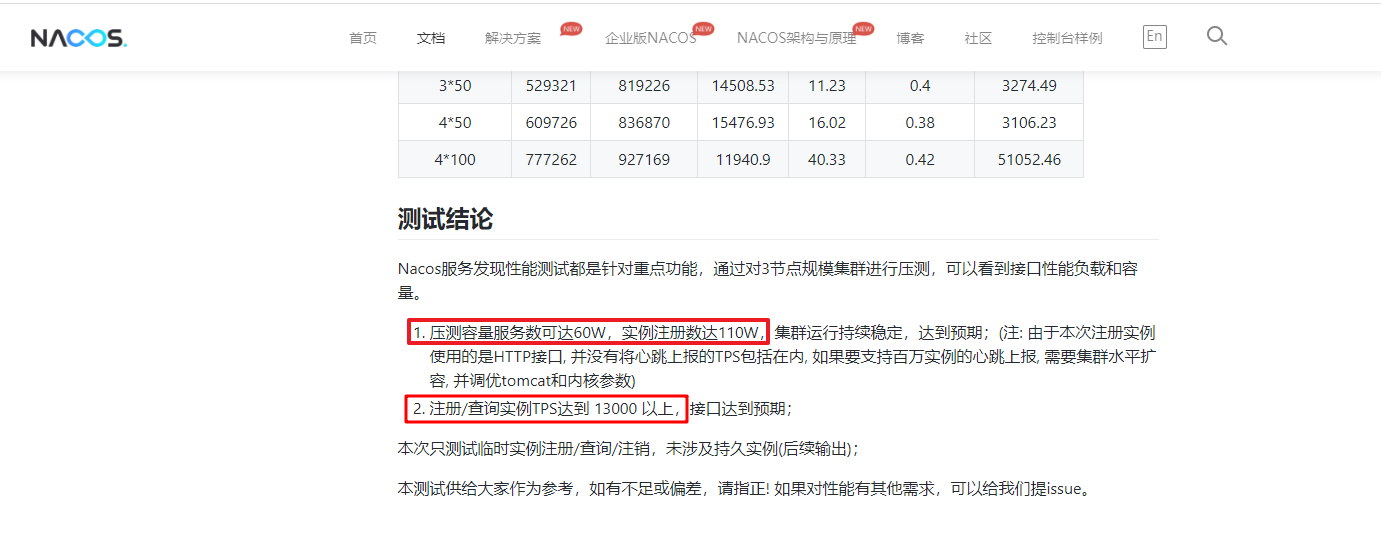
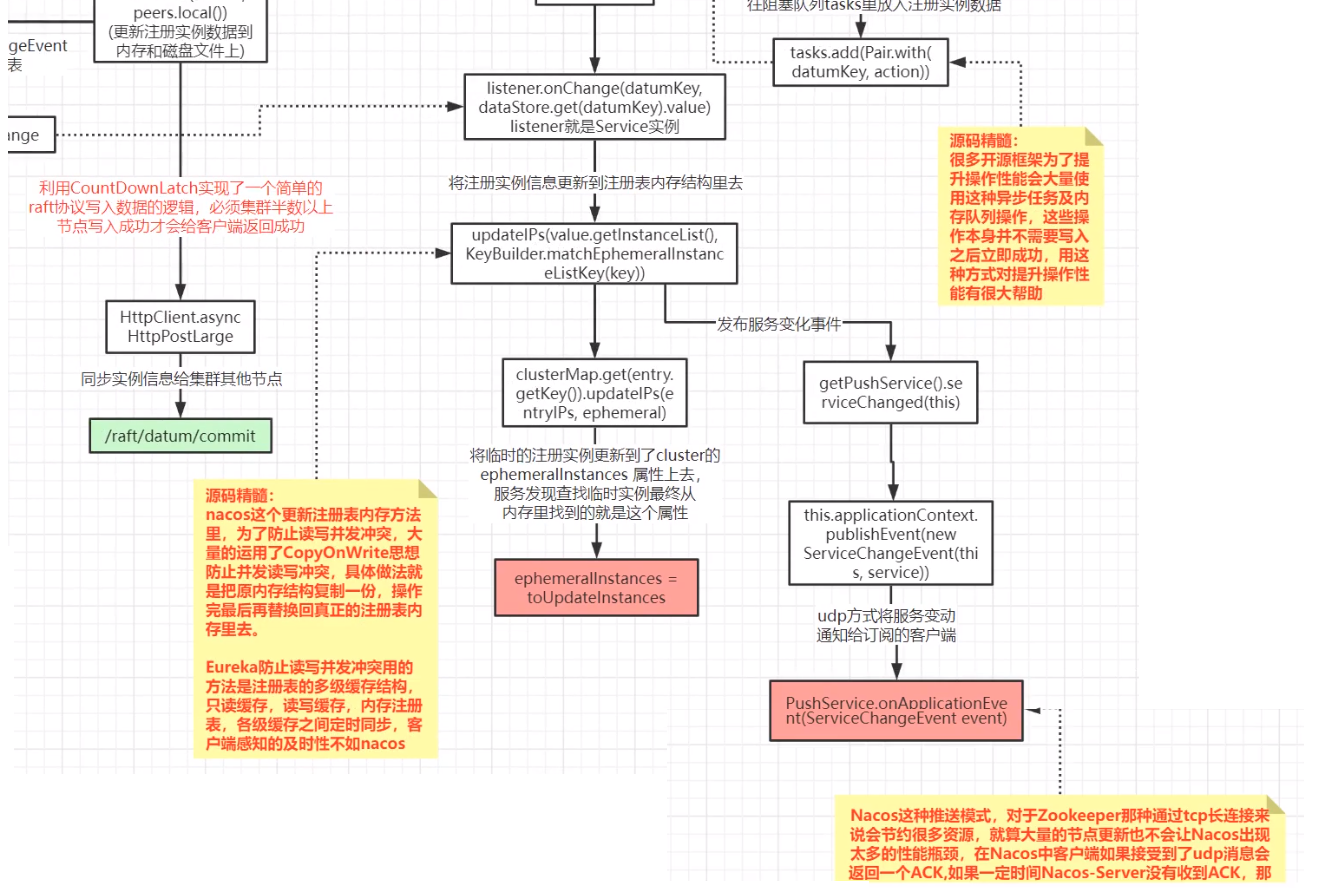
Nacos性能
例如:9003服务启动,要写到注册表中。此时,还没写完,就被订单系统给读取到了,那就是脏数据了。
读和写同一份数据就会有冲突问题,为了避免脏数据就只能加锁,写完之后释放锁再允许去读,但是这样去做,能抗高并发吗?不可能。
因为这样的话,读和写是排队执行,太慢了。
所以,阿里的底层并没有采用锁的机制,那么它怎么不影响脏数据的情况下,又能做到高并发呢?
读写冲突,使用了 “写时复制” 的机制COW。
写的时候,从注册表复制一份,在副本里面写,写完之后立马同步给注册表。
本质上,读和写数据上的分离。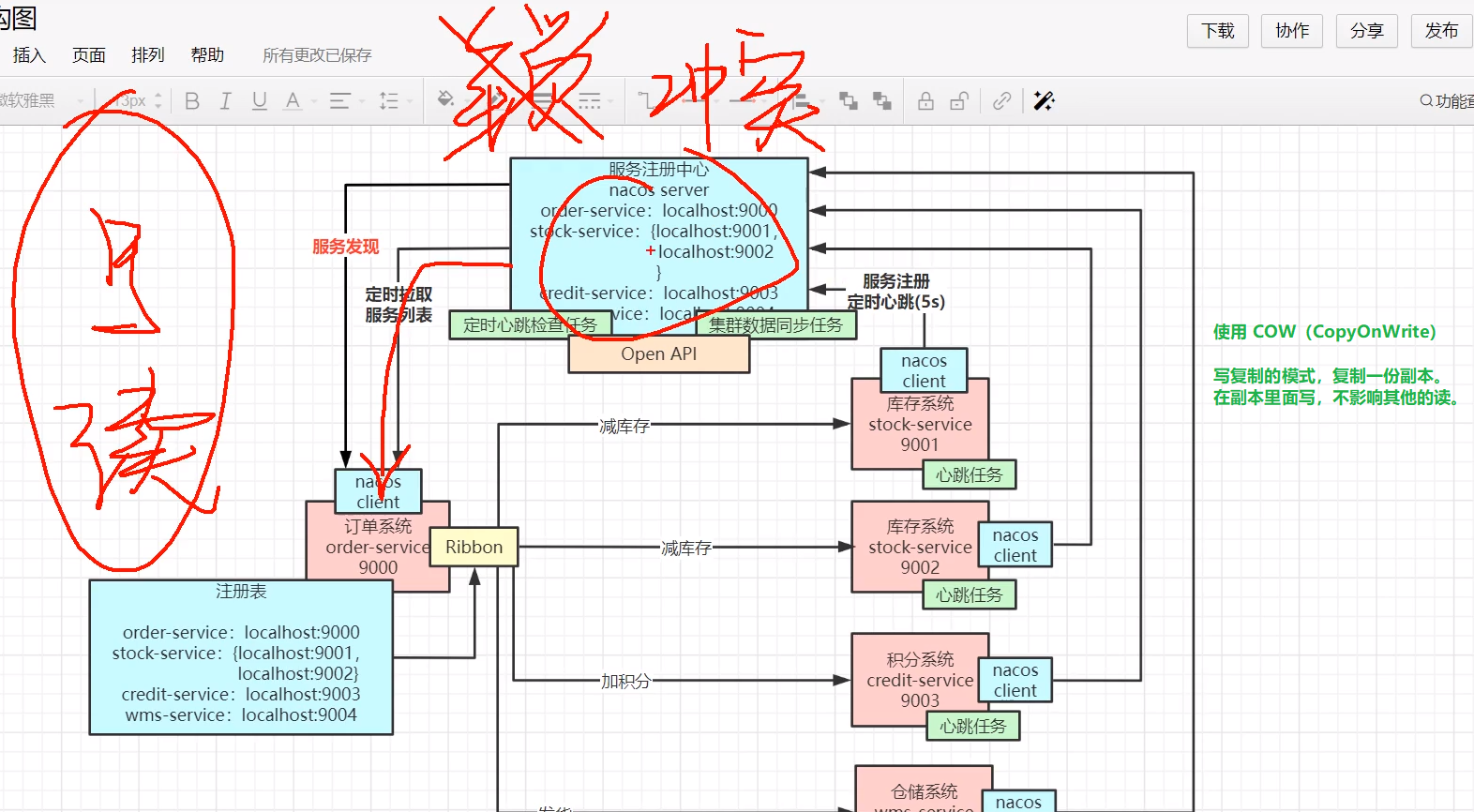
读源码小技巧
2022-01-20 08:51:13
看源码要看主线,说白了,就是要看你要看的东西,不要在看源码的时候,看到这个方法就想点进去看看,看到那个方法也点进去看看。
先把整体脉络了解清楚,再去看里面的具体实现。
.
还有一个重要的思路就是要看参数,跟参数有关的方法我们可以看,跟方法无关的方法,我们就不要追进去细看。
大致脉络了解清楚之后,后面有时候再去细看。
比如创建服务实例:Instance 主要就是看这个变量在哪里用到的,怎么创建的,怎么传参的。无关这个参数的,后面再细看。
例如:下面这张图,红色的就后续再看,第一次看这个方法,只要看绿色的部分,然后再进去方法细看。
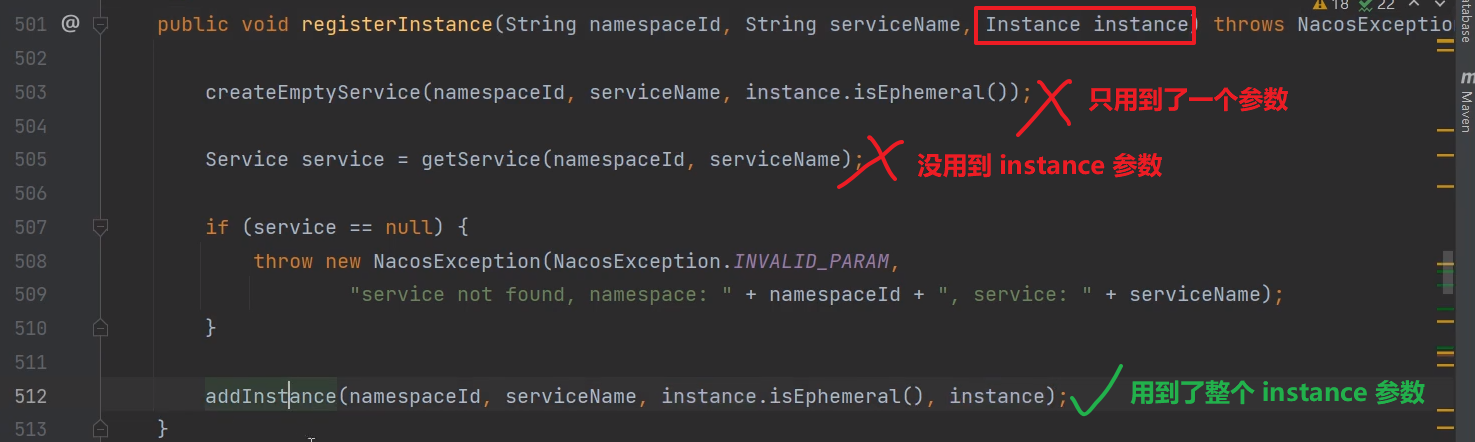
还有一点,就是看源码要去猜,先大致猜这个方法是干什么的,后续再慢慢去看。
例如:上面红色的部分,我们就可以去猜测了。然后主看绿色的部分。绿色看完后,再慢慢细看红色部分。
.
可以先静态把源码过一遍,然后再进行 debug 调试。
.
如果一个变量有多个实现不知道看哪个类,可以自己进行看这个类的初始化在哪里。
或者可以后续 debug 进行验证是哪个类。
.
可以第一次看源码的时候看主线代码,一个方法中的关于 return 的判断,一般都是非主线逻辑,可以直接跳过。
.
关于实现 Runnable 接口的类,二话不说,先把它的 run() 方法给看一遍。这个一定有他的核心逻辑。
为什么用异步?
1、快啊~
2、一个服务引入多个中间件。如果同步等所有中间件启动完成,我们再去启动,那么就会很慢了。所以,中间件要考虑到人家使用方(Client)的问题。要有对设计中间件的思考。
队列积压
用到队列,就有可能有积压。
我直接丢到队列中去了,队列消费慢的情况下,就会有积压。
有积压就会产生:服务提供方已经注册到注册中心上,并返回成功了。但是做为服务消费方依然感知不到。
或者说,注册失败怎么办?(这个后续再说)
提供方服务注册成功,队列有积压,只能等队列消费完成,服务消费方才能感知到,这个应该怎么办?
1、用过 eureka 的同学应该都知道,可能 eureka 一分钟才能注册上去,消费者才能感知得到。这个 Nacos 慢了几秒钟,也是可以的呀。
为了做异步注册,对Client 更友好一些,这种权衡也是可以的。
2、而且,这种场景出现的多吗,而且这种场景几乎不存在。除非我一瞬间发布几百台机器,几千台机器,甚至说几万台机器才可能导致队列积压。我们生产场景下,没有人这样干吧,一次性发布那么多台的机器。一般运维都是一两台发布一次,没事的话,再四五台发布一次,做灰度发布。(所以,出现这种积压的概率很低)
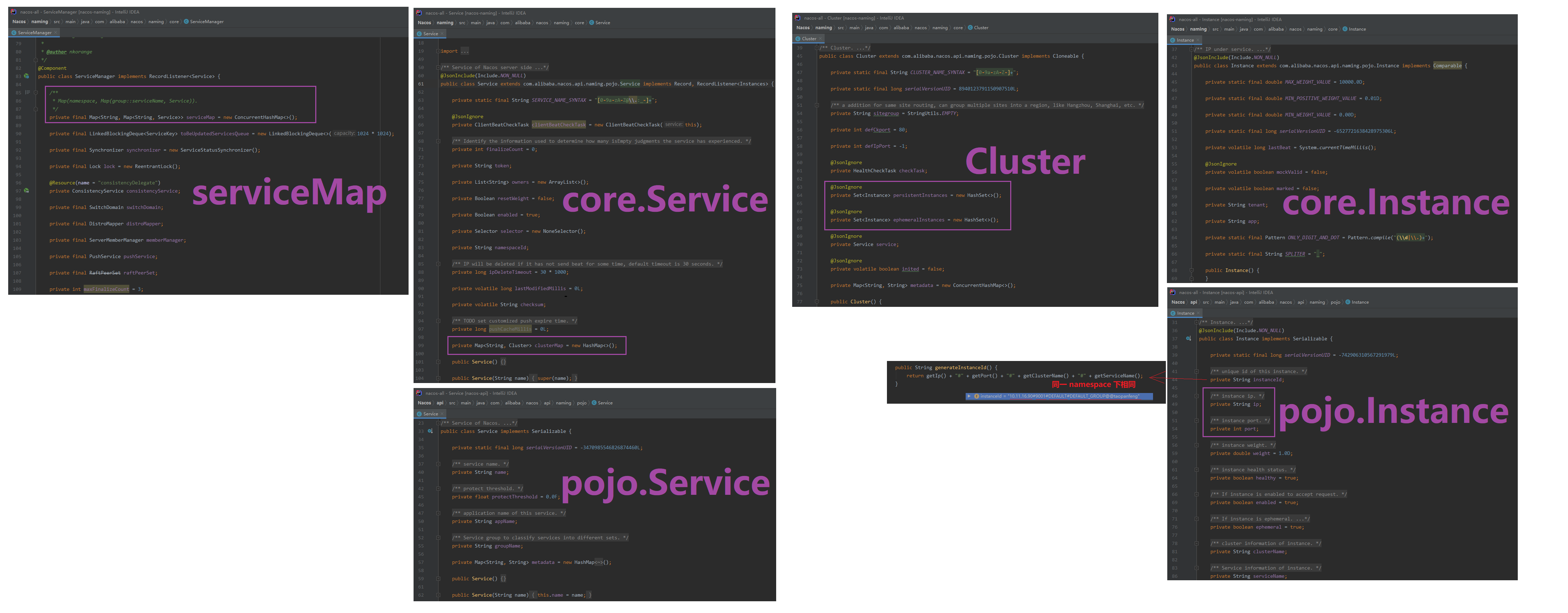
注册表结构
namespace:可以用于区分环境:local,dev(默认 public)
group:不同的服务(默认 DEFAULT)
service:服务名(GROUP_NAME@@SERVICE_NAME)
cluster:NJ 南京机房,BJ:北京机房部署。(默认 DEFAULT)
Instance:ip:port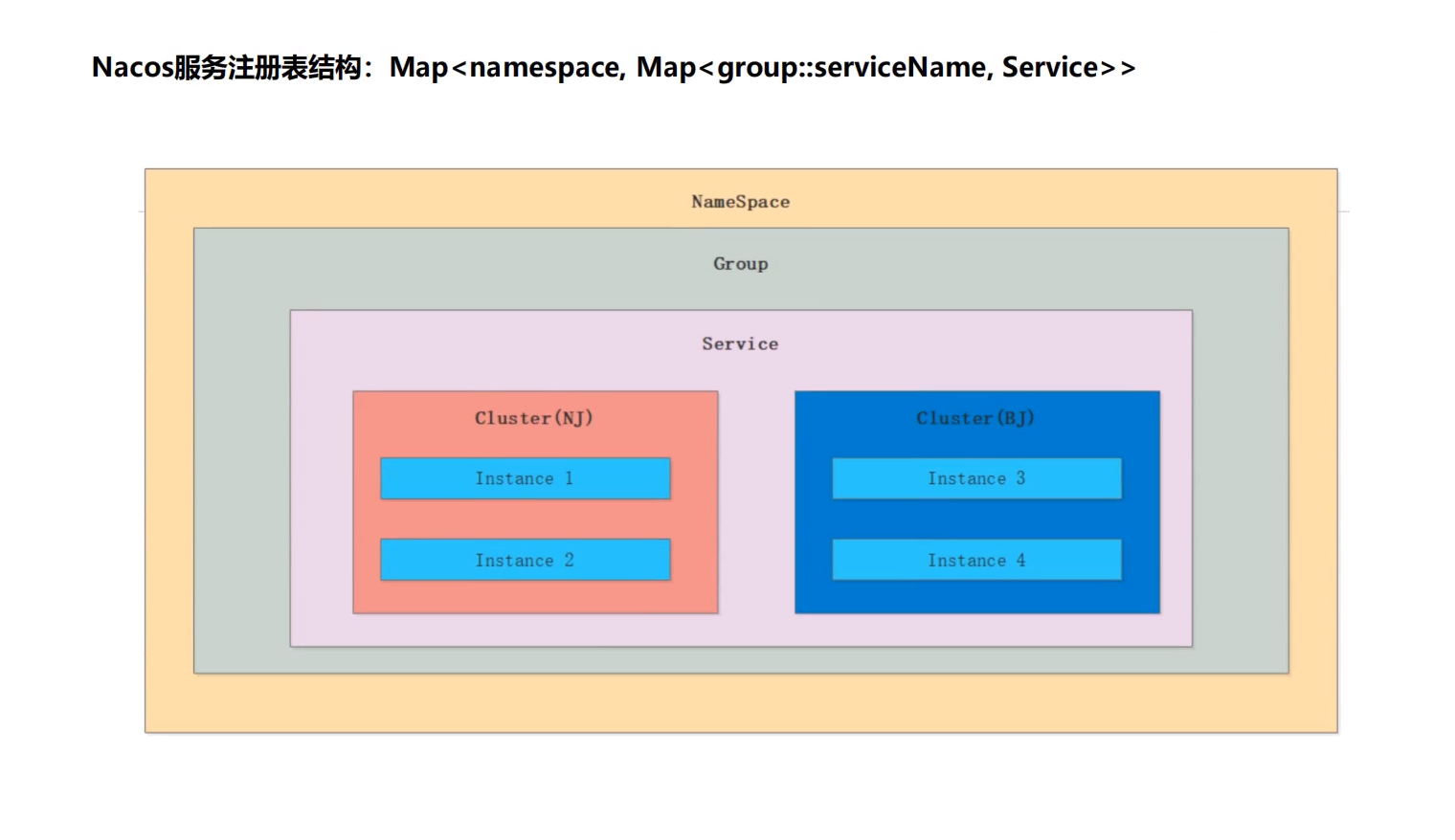
2022-01-25 08:34:02 补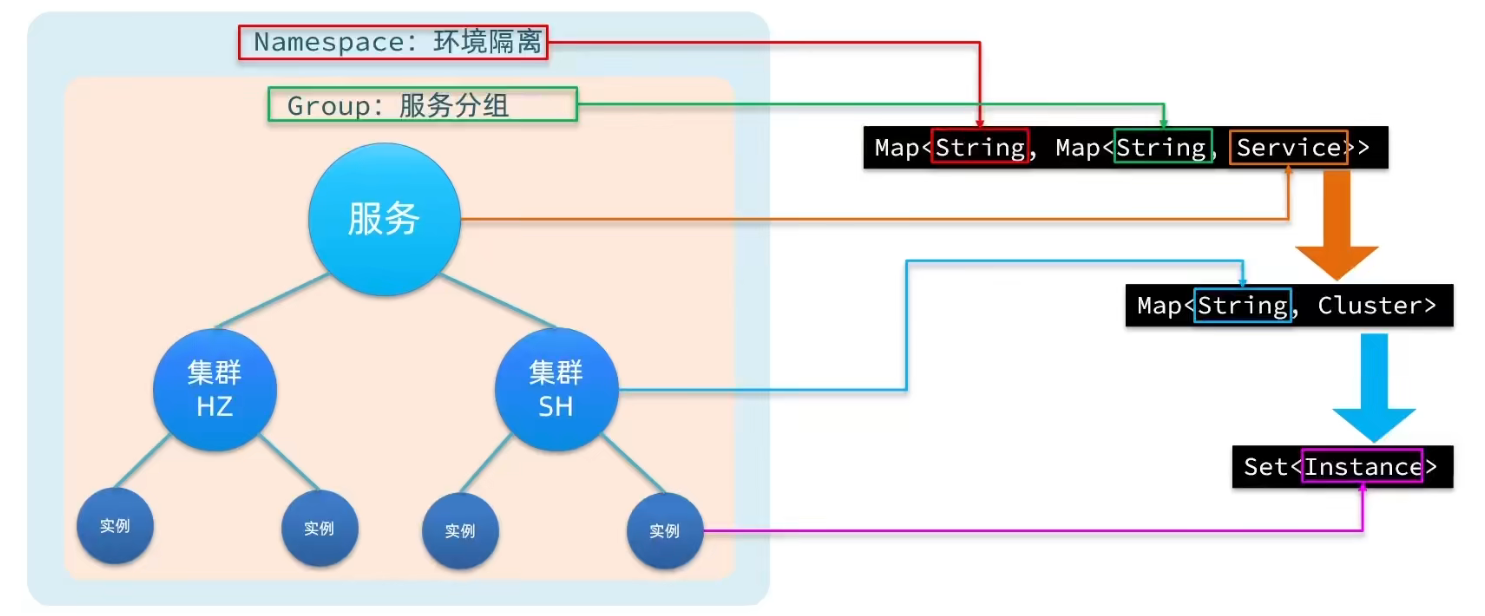
冰山的一角
其实看的东西还好,只是惊叹里面的设计,我的深度远不及。
包括里面的多线程:定时任务的使用Runnable,阻塞队列的使用,这些做异步的处理方式让我摸不着头脑,再保证几层抽象,就很难看懂了。做的人肯定是一眼就明了,这个还是需要以后细细的品。下面还要看 Spring Cloud / Alibaba 其他组件。每一样都可以让你看很久。