Raft算法
Raft算法是一个共识的算法,在集群的分布式状态中,保证每个节点都处于一致的状态。
Raft算法主要可以分为两个子问题:
- 领导人选举
- 日志复制
我接下来会从这两个角度进行讲解。
Raft算法中的服务器节点只有3种状态,领导者,候选人,追随者。
领导者负责管理集群中的日志复制(稍后会讲什么是日志复制),在大多数时候候选人这个状态是不存在的,只有当集群中没有领导者(可能由于领导者宕机之类的原因,至于集群中的其他节点怎么知道领导者挂机了,稍后也会说明)的时候才会产生候选人(谁会变为候选人后面也会说明),然后候选人会要求其他节点进行投票(多个候选人怎么办诸如此类的问题,后面都会讲解,会给你讲透,所以大家请放心观看,接下来就不在出现提示啦!),获得大多数票数的节点就变为新的领导者,其他所有节点的状态变为追随者。
当客户端有请求进来,负责接收和处理的是领导者,并且也只有领导者有资格进行这种操作,每一个服务器节点都在维护一个日志。假设客户端发送过来的是一个add请求,往服务器添加了一个数据,领导者会更新它的日志,然后通过AppendEntries(添加条目)消息(只是个名字,大家不用太在意,实质就是让追随者们去同步这个更新),领导者会记录追随者们返回成功的数目,如果超过半数的节点都成功了(比如有5台服务器,1个领导者和4个追随者,只需要2个追随者都返回成功就可以,因为加上领导者就是3个人占据大多数了),领导者这时候会告诉客户端已经成功add了,并且领导者会进行日志提交的操作,并且让其他的服务器节点也进行提交(更新和提交的区别稍后会讲解)。
这是大概的一个流程,但是其中其实有非常多的问题可以探讨,我们来一一进行深挖讲解。
领导人选举
首先对领导人选举的过程进行详细的介绍:
假设我们现在有3个节点,起始状态都为追随者。
每个节点会维护一个Term值,即为当前是第几任领导,现在是第0任,每个节点都会随机给一个TIMEOUT值,一般在150ms到300ms之间。当TIMEOUT值到达后,还没有收到领导者的心跳检测。(就像是许多人在开视频会议,但是主持人还没有上线,大家都在等待,但是存在一部分人等不及想要选举新的主持人)首先变成候选人的是TIMEOUT值先结束的节点,假设为A(TIMEOUT值是随机的),然后变成候选人后它首先会先让自己的Term + 1,并且先给自己投一票即自荐,然后向其他节点发送信息,要求他们进行投票(先到先得的思想,但不是绝对的,后面会讲)。
投票的数量占据所有节点总数一半以上即变为领导者,如果A节点成功变为了领导者,那么它会向其他节点按一定频率发送心跳检测,如果其他节点发现发送心跳检测的A节点的Term是大于或者等于当前它节点维护的Term的,他就会更新Term并且成为A的追随者。
再看看另一个特殊的情况:如果为5个节点:A,B,C,D,E。A为领导者Term为1,A宕机了,B和C的TIMEOUT同时到了,都给自己 Term + 1 = 2,给自己投了一票,然后B向CDE发送投票请求,C向BDE发送投票请求,D先回了B,E先回了C,那么B和C同时都有2票,达不到巨大多数的票数,那么它们会怎么办呢?
Raft算法设计的时候也考虑到这种问题,Raft算法通过重新随机它们的TIMEOUT值来达到解决这个问题的目的,如果还是相同票数则继续重试(重新生成随机 TIMEOUT 值)直到一个候选人拿到多数票为止。
日志复制
同时还会牵扯到候选人日志完整性问题,候选人只有日志足够完整才能当选,这个牵扯到第二个子问题:日志复制问题,我们来详细的探讨下哈。
我们先来解释一下日志更新和日志提交的区别:
日志会维护任期号和日志下标两个值,日志更新相当于是把操作已经添加到日志中了,但是下标还没有更新,只有当日志进行提交的时候才会去添加下标(为什么要这么搞?后面会讲)。
- 日志更新:添加日志,未更新下标
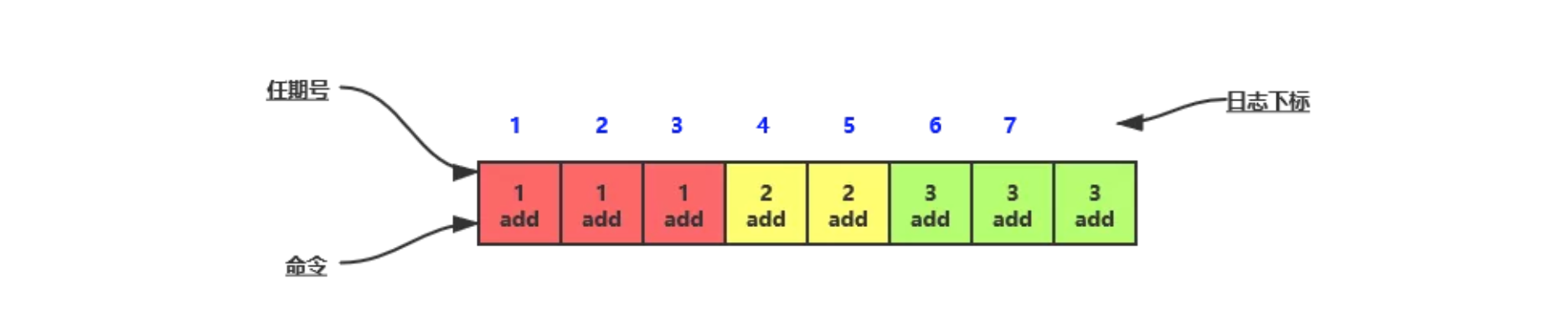
- 日志提交:更新下标

正常来说客户端一个请求过来,领导者接收,更新日志嘛,然后通知其他节点进行更新,接收到大多数成功的信息后,就告诉客户端OK咯,提交日志,让其他节点也提交日志。
我们看看比较特殊或者极端的情况。
情况1:(日志相同,谁先 TIMEOUT 谁当 Leader,下次提交日志再提交下标)
假设现在有A,B,C三个节点,领导者A接收了一个add请求,现在自己日志add了,然后发送信息让节点B和C也add到日志了。这个时候领导者A宕机了,也就是说接收不到其他节点的成功信息,不能进行commit操作,那咋办?这个add操作还有效吗?
答:现在B的TIMEOUT时间为150ms,C的TIMEOUT时间为160ms,所以B先变成候选人发起投票,C给B投票(如果在请求达到C之前,C也变成候选人,就等待下一次选举呗,先TIMEOUT的再次Term + 1,这里假设C还没有变为候选人),B变为了领导者,这个时候B和C都存在有未提交的日志下标8(如上图),但是Raft算法要求领导者不能删除或者覆盖自己的日志文件,所以新领导者B是不会删除下标未更新的日志8,并且会履行原来A的职责让追随者们更新日志8,但不会进行commit操作,只有在下一次客户端请求进来对日志进行操作时,让追随者们更新日志9,领导者B得到大多数的成功信息后,才会把两个日志都进行一个commit操作。
情况2:(日志多的人当 Leader,日志少的会进行同步)
现在有A,B,C三个节点,领导者A接收了一个add请求,现在自己日志add了,然后发送信息让节点B进行更新,还没对节点C发送,这个时候领导者A挂了咋办?
答:如果这时候还是C先到了过期时间,C向B发送了投票请求会发生什么?因为Raft算法要求新的领导者需要更具有完整性的日志,所以会拒绝向C进行投票,会等待下一次B自己选举的时候向C发送投票请求。也就是说,日志最新的B会成为领导者。
情况3:(日志少的人当 Leader,日志多的更新会被覆盖)
如果有A,B,C,D,E五个节点,A为领导者,接收了一个请求,B更新,C,D,E还没有更新就宕机了,这个时候还是C先TIMEOUT了,会发生什么?这个和特殊情况2有什么不同?
答:特殊情况2的时候A和B是已经存在有日志更新了,占据了绝大多数;但是在特殊情况3更新日志的情况只是占据少数,如果这个时候让没有更新日志的C来发起投票,那么C,D,E都会投给C,而B会拒绝投给C,但是C也拿到了绝大多数的票数,所以当选领导者,并且会检查其他节点的日志是否是最新的了,发现B存在它没有的日志,领导者首先不会去理会,在下一次进行更新的时候,因为会维护一个日志的index,并且是按照领导者index来执行,所以B更新的日志会被覆盖。
后言
还有许多比较极端的例子,大家可以自行进行分析,按照Raft算法设计的原则去进行推演,这里给大家介绍几个网站,保证大家一定能搞懂Raft算法,不单止能搞懂,而且还能搞的透透的。
所以说在日志不一致的时候,会按照领导者的日志来保证一致,通过一遍遍发送index(从大到小)到追随者节点找到第一个能匹配到的数据,然后把之后的数据进行情况,按照领导者的日志来进行写入操作。
Raft的简单动画:http://thesecretlivesofdata.com/raft/
Raft算法的可视化页面:https://raft.github.io/raftscope/index.html(可以设置TIMEOUT等各种参数,或者让服务器节点宕机等,动态的推演变化过程,在尝试极端情况例子非常好用!赞赞赞!)
想要深入理解Raft算法,光看文章还是有限的,上面的可视化页面搞起来!