Redis 在线测试
Redis 中文文档
Redis 配置【官网】
Redis 命令【中文官网】
Docker Redis镜像【官网】
Redis集群教程 官方文档
Redis集群规范官方文档
Redis哨兵模式 官方文档
redis.conf 官网下载-稳定版
sentinel.conf 官网下载-稳定版
简介
Redis 百度百科
Redis(Remote Dictionary Server ),即远程字典服务,
是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Linux安装
官网下载页面https://redis.io/download,点击Stable(稳定版)对应的Download
1 | # 1. 安装gcc环境 |
性能测试
请求本机6379,并发100,请求10万次
可以使用redis-benchmark --help查看帮助
1 | root@f48ac81f2b56:/data# redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000 |
操作命令
基本命令
命令起效返回
1不起效返回0找不到返回nil语法错误error…
Redis索引(下标)都从0开始
1)、数据库相关
1 | # DBSIZE 查看当前数据库有多少条数据 |
2)、connection连接/client客户端/server服务端
1 | ## QUIT / exit |
Key
对所有key生效
1 | ## expire / ttl |
String
字符串
Redis最基本的类型,一共key对应一个value,是二进制安全的,可以包含jpg图片或者序列号的对象.value最多可以是512M
1 | ## set / get |
使用场景
1)、单值缓存
1 | set k v |
2)、对象缓存
1 | set user:1 v # v是json格式 |
3)、分布式锁
1 | 127.0.0.1:6379> SETNX redisLock v # 设置成功返回1 |
4)、计数器
1 | 127.0.0.1:6379> INCR article:readCount:x001 # 每浏览一次文章阅读数 + 1,x001是文章编号 |
5)、Web集群session共享
1 | 用Redis来存取session |
List
有序集合
左头右尾,lpush依次头插入,rpush依次尾插入,lpop删除头,rpop删除尾
就把它当做LinkedList就行了。lpush头插入,rpush尾插入,lpop删除头,rpop删除尾
lrange key 0 -1 就是for循环,从左开始循环
注意:不存在为空的集合,如果集合无元素,就会删除这个集合的key。
1 | ## lpush / rpush |
使用场景
1)、常用数据结构
1 | # Stack 栈 |
2)、微博,工众号消息
1 | 127.0.0.1:6379> LPUSH msg:daniu hello # 公众号弟弟推送消息 |
Set
无序集合
String类型的无序集合.值不允许重复.
1 | ## sadd / srem |
使用场景
1)、抽奖小程序
1 | # 1. 点击参与抽奖:加入集合 |
2)、微信微博点赞,收藏,标签
1 | 127.0.0.1:6379> SADD like:helloworld daniu # 点赞 |
3)、微信朋友圈,微博相同关注的人:集合操作
1 | 127.0.0.1:6379> SADD k1 1 2 3 4 5 # 用户k1关注了:1 2 3 4 5 |
Hash
哈希
类似于java的Map.KV模式不变.但V是一个键值对.
我们这里称【主key为k1,副key为k2,k2对应的值为v2】
1 | ## hset / hget |
使用场景
1)、对象缓存
1 | 127.0.0.1:6379> HMSET user 1:name daniu 1:age 18 |
2)、电商购物车
1 | 1. 以用户id为key |
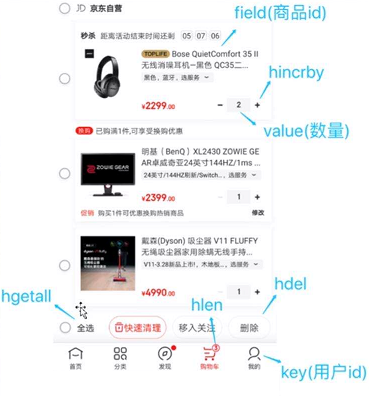
优点&缺点
1 | # 优点 |
Zset
有序set集合
Zset(sorted set) 有序集合 和set一样不允许重复,不同的是每个元素都会关联一个double类型的分数,
通过这些分数从大到小降序排列,成员是唯一的,分数是可以重复的
》》》多说一句
在sadd基础上,加一个score值
之前sadd是k1 v1 v2 v3 …
现在zset是k1 score1 v1 score2 v2 … 在sadd基础上,加一个score值
1 | # ZADD |
应用场景
1)、微博热搜排行榜
1 | # 点击新闻,浏览量 + 1 |
Geospatial
地理空间
经纬度查询【便民查询网】
可以用于附近的人
1 | # GEOADD |
HyperLogLogs
基数统计
用于网站的UV(访问量)
基数介绍:
A(1 ,3 ,5 ,7)
B(1 ,5 ,7 ,9)
基数(不重复的元素):=3,可以接受误差!
1 | # PFADD |
Bitmaps
位图
位运算
模式:使用 bitmap 实现用户上线次数统计
Bitmap 对于一些特定类型的计算非常有效。
1 | # SETBIT |
事务
命令简介
1 | MULTI(开启事务) |
正常执行事务
1 | 127.0.0.1:6379> FLUSHALL |
取消事务
取消事务,全部不执行,注意,DISCARD具有UNWATCH的功能
1 | 127.0.0.1:6379> FLUSHALL |
(编译异常)全部失败
(编译异常)一个入队失败,全部不执行。
1 | 127.0.0.1:6379> FLUSHALL |
(运行时异常)部分失败
(运行时异常)全部入队成功,部分命令可能会执行失败。
1 | 127.0.0.1:6379> FLUSHALL |
不进行WATCH
1 | 127.0.0.1:6379> FLUSHALL |
进行WATCH监控
进行WATCH乐观锁监控
1 | 127.0.0.1:6379> FLUSHALL |
Jedis操作
更多参考Redis【4】Java Jedis 操作 Redis
0)、引入依赖
1 | <dependencies> |
1)、测试连接
1 | package taopanfeng; |
2)、输出结果
3)、操作和我们的命令都是一样的
4)、事务
1 | package taopanfeng; |
SpringBoot整合
Redis配置文件
Redis.conf文件,6.0配置
1)、说明
、可以在启动时加上参数,例如:redis-server --port 6380 --slaveof 127.0.0.1 6379
、如果要指定配置文件,要把配置文件放在第一个参数:redis-server /usr/local/etc/redis/redis.conf --port 6380 --slaveof 127.0.0.1 6379
、获取配置config get 配置key
、设置配置,临时生效,重启server失效config set 配置key "xxx"
、如果配置文件key的值存在多个可使用空格作为间隔,例如:bind 192.168.1.1 192.168.1.2
、单位不区分大小写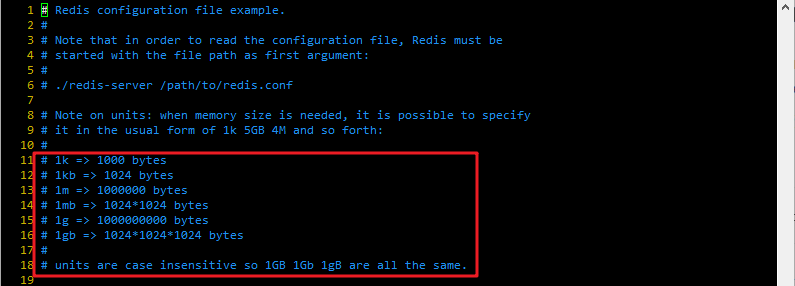
2)、INCLUDES
、包含一段配置文件
1 | # include /path/to/local.conf |
3)、MODULES
、加载一下模块(了解)
1 | # loadmodule /path/to/my_module.so |
4)、NETWORK
网络
1 | # 默认本地访问,可指定其他的IP进行远程外部访问 |
5)、TLS/SSL
省略
6)、GENERAL
通用
1 | daemonize no # 守护进程开启,no表示后台运行 |
7)、SNAPSHOTTING
快照
1 | # 持久化,在规定的时间内,执行了多少次操作,则会持久化到文件:rdb,aof |
8)、REPLICATION
主从复制
1 | # replicaof <masterip> <masterport># 主从复制选项,本机为从机,设置主机的IP和端口 |
9)、KEYS TRACKING
省略
10)、SECURITY
安全
1 | # 设置密码,默认为空,可以配置密码,持久化 |
11)、CLIENTS
客户端
1 | # maxclients 10000 # 设置最大连接数 |
12)、MEMORY MANAGEMENT
内存管理
1 | # maxmemory <bytes> # 最大内存 |
13)、LAZY FREEING
14)、THREADED I/O
线程IO
1 | 975 # Redis is mostly single threaded, however there are certain threaded |
15)、APPEND ONLY MODE
AOF追加模式
1 | appendonly no # 默认不开启AOF模式。大部分情况下,RDB够用了 |
16)、LUA SCRIPTING LUA脚本
17)、REDIS CLUSTER Redis集群
1 | # cluster-enabled yes # 默认不开启集群 |
18)、CLUSTER DOCKER/NAT support
Docker集群的支持
1 | # 案例: |
19)、LATENCY MONITOR 延迟监控
20)、EVENT NOTIFICATION 事件通知
21)、GOPHER SERVER
22)、ADVANCED CONFIG 高级配置
23)、ACTIVE DEFRAGMENTATION 激活碎片
Redis持久化
RDB
配置:在上面配置文件7)、SNAPSHOTTING中进行了讲解
0)、简介
Redis DataBase, 对应文件dump.rdb
、能够在指定的时间间隔对你的数据进行快照储存,保存RDB文件时,父进程开启一个子进程,接下来的工作全部由子进程来做,可以最大化Redis性能
1)、测试
1 | #save 900 1 # 900秒内修改1次 |
2)、触发机制(以下任何一个都会生成dump.rdb文件):
、关闭server端
、执行flushall命令
、满足save条件
3)优缺点
优点
、使用大规模数据恢复
、对数据完整性要求不高!
缺点
、需要一定的间隔时间,如果意外挂了,就会丢失最后一次数据
、开启一份进程进行持久化的时候,会占用一定的时间
AOF
配置:在上面配置文件15)、APPEND ONLY MODE中进行了讲解
0)、简介
Append Only File,对应文件appendonly.aof
、以日志形式来追加记录每一个写操作,恢复需要根据日志文件的命令从头到尾执行一次
1)、测试
1 | #appendonly no |
2)、说明
退出server也会生产dump.rdb文件,但不会生成aof文件,只有启动server端,才会生成aof文件。
启动client时,会读取AOF文件。
如果读取aof文件错误,可使用命令修复AOF文件:redis-check-aof --fix appendonly.aof,会把错误的命令去除
3)、优缺点
优点
、每一次修改都同步,文件完整性更好
、每秒同步一次,可能会丢失1秒数据
、从不同步,效率最高
缺点
、对于文件来说,aof比rdb文件要大,修改的速度也比rdb慢。
、aof比rdb的效率慢,所以Redis默认使用rdb
Redis发布订阅
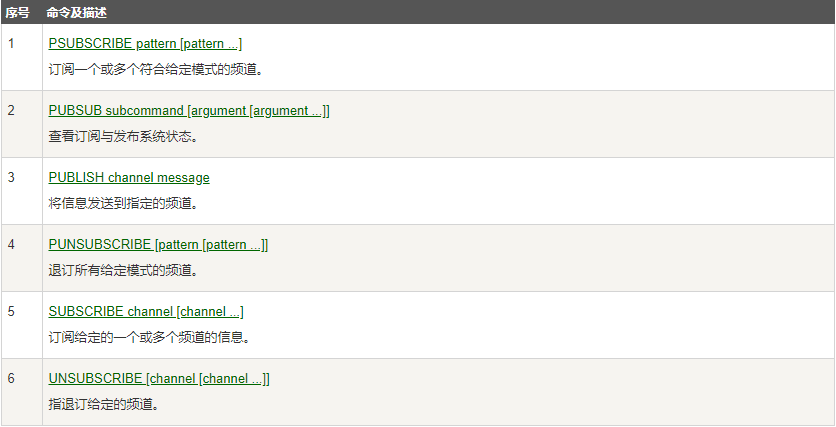
1 | + SUBSCRIBE channel [channel ...] |
Redis主从复制
请转自Redis主从复制
Redis哨兵模式
请转自Redis哨兵模式
缓存雪崩/穿透/击穿
1 | 2021-07-16 09:31:49 补充 |
雪崩
缓存在同一时间内大量key过期(失效)或Redis挂了,接着来的一大波请求瞬间都落在了数据库中导致连接异常。
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。
因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,这个时候,数据库也是可以顶住压力的。
无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
解决方案:
1)、Redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。(异地多活!)
2)、限流降级(在SpringCloud讲解过!)
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。
比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
3)、数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。
在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
穿透
缓存查不到,去查数据库,数据库也差不到,导致写入不了缓存。
这会导致每次查询都会去请求数据库,造成缓存穿透;
解决方案:
1)、布隆过滤器
对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力;
2)、缓存空对象
当数据库不存在时,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了数据库;
存在问题:
但是这种方法会存在两个问题:
1、如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;
2、即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。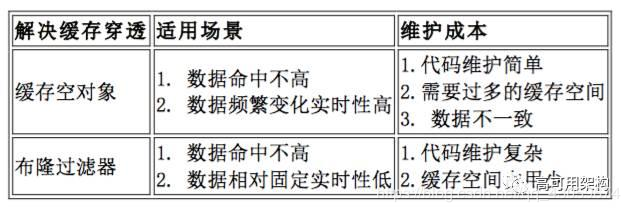
击穿
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,
大并发集中 对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,
直接请求数据库,就像在一 个屏障上凿开了一个洞。
当某个key在过期的瞬间,有大量的请求并发访问,这类数据一般是热点数据,由于缓存过期,
会同时访 问数据库来查询新数据,并且回写缓存,会导使数据库瞬间压力过大。
1)、设置热点数据永不过期
从缓存层面来看,没有设置过期时间,所以不会出现热点 key 过期后产生的问题。
2)、加互斥锁
分布式锁:使用分布式锁,保证对于每个key同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。
这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大。
Redis分布式锁:先setnx获取锁,再del释放锁。可能造成长时间等待。会存在超时时间问题。
1 | Jedis jedis = new Jedis("192.168.1.1", 6379); |