搬运自:并发框架Disruptor译文
Martin Fowler在自己网站上写了一篇LMAX架构的文章,在文章中他介绍了LMAX是一种新型零售金融交易平台,它能够以很低的延迟产生大量交易。这个系统是建立在JVM平台上,其核心是一个业务逻辑处理器,它能够在一个线程里每秒处理6百万订单。业务逻辑处理器完全是运行在内存中,使用事件源驱动方式。业务逻辑处理器的核心是Disruptor。
Disruptor它是一个开源的并发框架,并获得2011 Duke’s 程序框架创新奖,能够在无锁的情况下实现网络的Queue并发操作。本文是Disruptor官网中发布的文章的译文(现在被移到了GitHub)。
剖析Disruptor:为什么快?
锁的缺点
Martin Fowler写了一篇非常好的文章,里面不仅提到了Disruptor,而且还解释了Disruptor 如何应用在LMAX的架构里。里面有提及了一些目前没有涉及的概念,但最经常问到的问题是 “Disruptor究竟是什么?”。
目前我正准备在回答这个问题,但首先回答“为什么它会这么快?”
这些问题持续出现,但是我不能没有说它是干什么的就说它为什么会这么快,不能没有说它为什么这样做就说它是什么东西。
所以我陷入了一个僵局,一个如何写博客的僵局。
要打破这个僵局,我准备以最简单方式回答第一个问题,如果幸运的话,在以后博文里,如果需要解释的话我会重新提回:Disruptor提供了一种线程之间信息交换的方式。
作为一个开发者,因为“线程”一词的出现,我的警钟已经敲响,它意味着并发,而并发是困难的。
》》》并发 01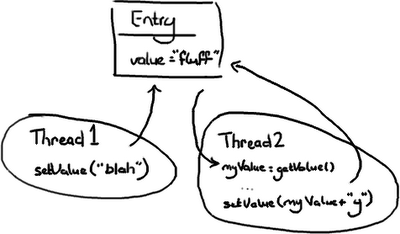
想象有两个线程尝试修改同一个变量value(注意看图,两个线程做分别做什么):
1 | 情况一:线程1先到达 |
情况三显然是唯一一个是错误的,除非除非你认为wiki编辑的幼稚做法是正确的(Google Code) Wiki,我一直在关注你)。其他两种情况主要是看你的意图和想要达到的效果。线程2可能不会关心变量value的值是什么,主要的意图就是在后面加上字符 “y” 而不管它原来的值是什么,在这种前提下,情况一和情况二都是正确的。
但是如果线程2只是想把“fluff”改为“fluffy”,那么情况二和三都不正确。假定线程2想把值设为“fluffy”,有几种办法可以解决这个问题:
》》》办法一:悲观锁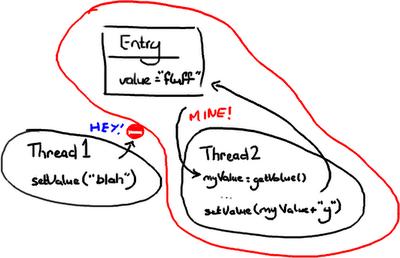
悲观锁和乐观锁这两个词通常在我们谈论数据库读写时经常会用到,但原理可以应用到在获得一个对象的锁的情况。
只要线程2 获得Entry 的互斥锁,它就会阻击其它线程去改变它,然后它就可以随意做它要做的事情,设置值,然后做其它事情。
你可以想象这里非常耗性能的,因为其它线程在系统各处徘徊着准备要获得锁然后又阻塞。线程越多,系统的响应性就会越慢.
》》》办法二:乐观锁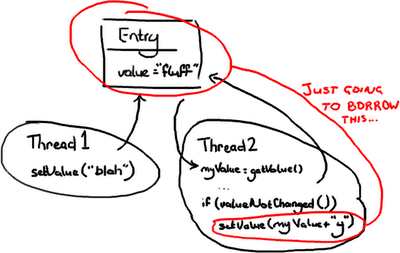
在这种情况,当线程2需要去写Entry时才会去锁定它,它需要检查Entry自从上次读过后是否已经被改过了。
如果线程1在线程2读完后到达并把值改为“blah”,线程2读到了这个新值,线程2不会把“fluffy”写到Entry里并把线程1所写的数据覆盖。
线程2会重试(重新读新的值,与旧值比较,如果相等则在变量的值后面附上“y”),这里在线程2不会关心新的值是什么的情况,或者线程2会抛出一个异常,或者会返回一个某些字段已更新的标志,这是在期望把“fluff”改为“fluffy”的情况。
举一个第二种情况的例子,如果你和另外一个用户同时更新一个Wiki的页面,你会告诉另外一个用户的线程 Thread-2,它们需要重新加载从 Thread-1 来新的变化,然后再提交它们的内容。
》》》潜在的问题:死锁
锁定会带来各种各样的问题,比如死锁,想象有2个线程需要访问两个资源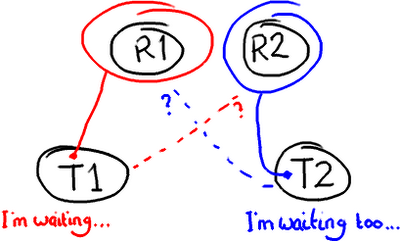
如果你滥用锁技术,两个锁都在获得锁的情况下尝试去获得另外一个锁,那就是你应该重启你的电脑的时候了。(校注:作者还挺幽默)
》》》很明确的一个问题:锁技术是慢的。。。
关于锁就是它们需要操作系统去做裁定。
线程就像两姐妹在为一个玩具在争吵,然后操作系统就是能决定他们谁能拿到玩具的父母,就像当你跑向你父亲告诉他你的姐姐在你玩着的时候抢走了你的变形金刚-他还有比你们争吵更大的事情去担心,他或许在解决你们争吵之前要启动洗碗机并把它摆在洗衣房里。
如果你把你的注意力放在锁上,不仅要花时间来让操作系统来裁定。
Disruptor论文中讲述了我们所做的一个实验。这个测试程序调用了一个函数,该函数会对一个64位的计数器循环自增5亿次。
- 当单线程无锁时,程序耗时300ms。
- 如果增加一个锁(仍是单线程、没有竞争、仅仅增加锁),程序需要耗时10000ms,慢了两个数量级。
- 更令人吃惊的是,如果增加一个线程(简单从逻辑上想,应该比单线程加锁快一倍),耗时224000ms。使用两个线程对计数器自增5亿次比使用无锁单线程慢1000倍。并发很难而锁的性能糟糕。
我仅仅是揭示了问题的表面,而且,这个例子很简单。但重点是,如果代码在多线程环境中执行,作为开发者将会遇到更多的困难:
- 代码没有按设想的顺序执行。上面的场景3表明,如果没有注意到多线程访问和写入相同的数据,事情可能会很糟糕。
- 减慢系统的速度。场景3中,使用锁保护代码可能导致诸如死锁或者效率问题。
这就是为什么许多公司在面试时会多少问些并发问题(当然针对Java面试)。不幸的是,即使未能理解问题的本质或没有问题的解决方案,也很容易学会如何回答这些问题。
》》》Disruptor如何解决这些问题。
首先,Disruptor根本就不用锁。
取而代之的是,在需要确保操作是线程安全的(特别是,在多生产者的环境下,更新下一个可用的序列号)地方,我们使用CAS(Compare And Swap/Set)操作。
这是一个CPU级别的指令,在我的意识中,它的工作方式有点像乐观锁:CPU去更新一个值,但如果想改的值不再是原来的值,操作就失败,因为很明显,有其它操作先改变了这个值。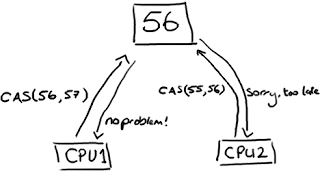
注意,这可以是CPU的两个不同的核心,但不会是两个独立的CPU。
CAS操作比锁消耗资源少的多,因为它们不牵涉操作系统,它们直接在CPU上操作,但它们并非没有代价。
在上面的试验中:
- 单线程无锁耗时300ms
- 单线程有锁耗时10000ms
- 单线程使用CAS耗时5700ms(所以它比使用锁耗时少,但比不需要考虑竞争的单线程耗时多)。
回到Disruptor,在我讲生产者时讲过ClaimStrategy。在这些代码中,你可以看见两个策略:一个是SingleThreadedStrategy(单线程策略)另一个是MultiThreadedStrategy(多线程策略)。你可能会有疑问,为什么在只有单个生产者时不用多线程的那个策略?它是否能够处理这种场景?当然可以。但多线程的那个使用了AtomicLong(Java提供的CAS操作),而单线程的使用long,没有锁也没有CAS。这意味着单线程版本会非常快,因为它只有一个生产者,不会产生序号上的冲突。
我知道,你可能在想:把一个数字转成AtomicLong不可能是Disruptor速度快的唯一秘密。当然,它不是,否则它不可能称为“为什么这么快(第一部分)”。
但这是非常重要的一点:在整个复杂的框架中,只有这一个地方出现多线程竞争修改同一个变量值。这就是秘密。还记得所有的访问对象都拥有序号吗?如果只有一个生产者,那么系统中的每一个序列号只会由一个线程写入。这意味着没有竞争、不需要锁、甚至不需要CAS。在ClaimStrategy中,如果存在多个生产者,唯一会被多线程竞争写入的序号就是 ClaimStrategy 对象里的那个。
这也是为什么Entry中的每一个变量都只能被一个消费者写。它确保了没有写竞争,因此不需要锁或者CAS。
》》》回到为什么队列不能胜任这个工作
因此你可能会有疑问,为什么队列底层用RingBuffer来实现,仍然在性能上无法与 Disruptor 相比。队列和最简单的ring buffer只有两个指针:一个指向队列的头,一个指向队尾: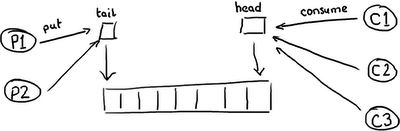
如果有超过一个生产者想要往队列里放东西,尾指针就将成为一个冲突点,因为有多个线程要更新它。如果有多个消费者,那么头指针就会产生竞争,因为元素被消费之后,需要更新指针,所以不仅有读操作还有写操作了。
等等,我听到你喊冤了!因为我们已经知道这些了,所以队列常常是单生产者和单消费者(或者至少在我们的测试里是)。
队列的目的就是为生产者和消费者提供一个地方存放要交互的数据,帮助缓冲它们之间传递的消息。这意味着缓冲常常是满的(生产者比消费者快)或者空的(消费者比生产者快)。生产者和消费者能够步调一致的情况非常少见。
所以,这就是事情的真面目。
一个空的队列: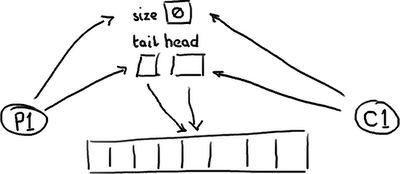
一个满的队列: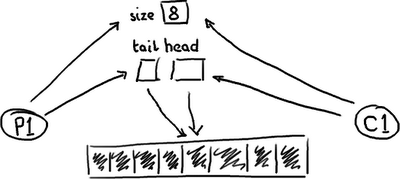
(校对注:这应该是一个双向队列)
队列需要保存一个关于大小的变量,以便区分队列是空还是满。否则,它需要根据队列中的元素的内容来判断,这样的话,消费一个节点(Entry)后需要做一次写入来清除标记,或者标记节点已经被消费过了。无论采用何种方式实现,在头、尾和大小变量上总是会有很多竞争,或者如果消费操作移除元素时需要使用一个写操作,那元素本身也包含竞争。
基于以上,这三个变量常常在一个cache line里面,有可能导致false sharing。因此,不仅要担心生产者和消费者同时写size变量(或者元素),还要注意由于头指针尾指针在同一位置,当头指针更新时,更新尾指针会导致缓存不命中。这篇文章已经很长了,所以我就不再详述细节了。
这就是我们所说的“分离竞争点问题”或者队列的“合并竞争点问题”。通过将所有的东西都赋予私有的序列号,并且只允许一个消费者写Entry对象中的变量来消除竞争,Disruptor 唯一需要处理访问冲突的地方,是多个生产者写入 Ring Buffer 的场景。
》》》总结
Disruptor相对于传统方式的优点:
- 没有竞争=没有锁=非常快。
- 所有访问者都记录自己的序号的实现方式,允许多个生产者与多个消费者共享相同的数据结构。
- 在每个对象中都能跟踪序列号(ring buffer,claim Strategy,生产者和消费者),加上神奇的cache line padding,就意味着没有为伪共享和非预期的竞争。
校订:需要注意Disruptor2.0使用了与本文中不一样的名字。如果对类名感到困惑,请参考我的变更汇总。
神奇的缓存行填充
我们经常提到一个短语Mechanical Sympathy,这个短语也是Martin博客的标题(译注:Martin Thompson),Mechanical Sympathy讲的是底层硬件是如何运作的,以及与其协作而非相悖的编程方式。
我在之前锁的缺点中提到RingBuffer后,有很多人对RingBuffer中填充高速缓存行存在疑问。由于这个适合用漂亮的图片来说明,所以我想这是下一个我该解决的问题了。
(译注:Martin Thompson很喜欢用Mechanical Sympathy这个短语,这个短语源于赛车驾驶,它反映了驾驶员对于汽车有一种天生的感觉,所以他们对于如何最佳的驾御它非常有感觉。)
补充另外一种说法:Mechanical Sympathy 是说“硬件和软件协同工作”
》》》计算机入门
我喜欢在LMAX工作的原因之一是,在这里工作让我明白从大学和A Level Computing所学的东西实际上还是有意义的。做为一个开发者你可以逃避不去了解CPU,数据结构或者大O符号 —— 而我用了10年的职业生涯来忘记这些东西。但是现在看来,如果你知道这些知识并应用它,你能写出一些非常巧妙和非常快速的代码。
因此,对在学校学过的人是种复习,对未学过的人是个简单介绍。但是请注意,这篇文章包含了大量的过度简化。
CPU是你机器的心脏,最终由它来执行所有运算和程序。主内存(RAM)是你的数据(包括代码行)存放的地方。本文将忽略硬件驱动和网络之类的东西,因为Disruptor的目标是尽可能多的在内存中运行。
CPU和主内存之间有好几层缓存,因为即使直接访问主内存也是非常慢的。如果你正在多次对一块数据做相同的运算,那么在执行运算的时候把它加载到离CPU很近的地方就有意义了(比如一个循环计数-你不想每次循环都跑到主内存去取这个数据来增长它吧)。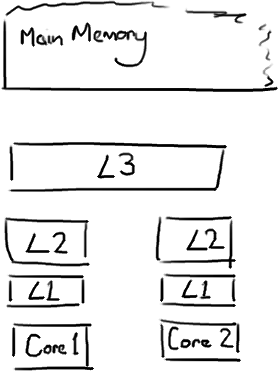
越靠近CPU的缓存越快也越小。所以L1缓存很小但很快(译注:L1表示一级缓存),并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在L1缓存中。
Martin和Mike的 QCon presentation 演讲中给出了一些缓存未命中的消耗数据: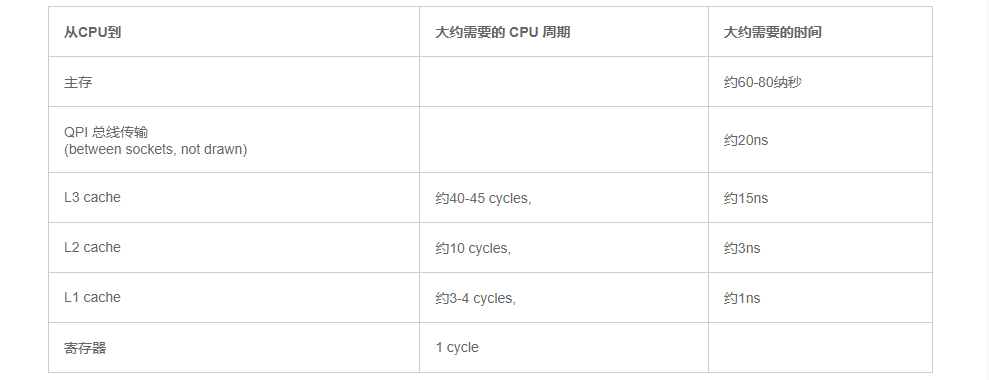
如果你的目标是让端到端的延迟只有 10毫秒,而其中花80纳秒去主存拿一些未命中数据的过程将占很重的一块。
》》》缓存行
现在需要注意一件有趣的事情,数据在缓存中不是以独立的项来存储的,如不是一个单独的变量,也不是一个单独的指针。缓存是由缓存行组成的,通常是64字节(译注:这篇文章发表时常用处理器的缓存行是64字节的,比较旧的处理器缓存行是32字节),并且它有效地引用主内存中的一块地址。一个Java的long类型是8字节,因此在一个缓存行中可以存8个long类型的变量。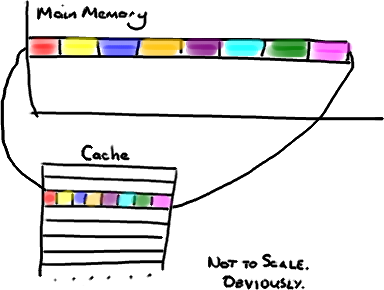
(为了简化,我将忽略多级缓存)
非常奇妙的是如果你访问一个long数组,当数组中的一个值被加载到缓存中,它会额外加载另外7个。因此你能非常快地遍历这个数组。事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构。我在第一篇关于ring buffer的文章中顺便提到过这个,它解释了我们的ring buffer使用数组的原因。
因此如果你数据结构中的项在内存中不是彼此相邻的(链表,我正在关注你呢),你将得不到免费缓存加载所带来的优势。并且在这些数据结构中的每一个项都可能会出现缓存未命中。
不过,所有这种免费加载有一个弊端。设想你的long类型的数据不是数组的一部分。设想它只是一个单独的变量。让我们称它为head,这么称呼它其实没有什么原因。然后再设想在你的类中有另一个变量紧挨着它。让我们直接称它为tail。现在,当你加载head到缓存的时候,你也免费加载了tail。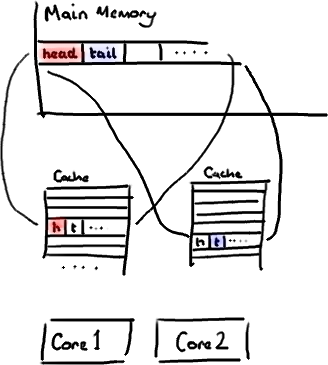
听想来不错。直到你意识到tail正在被你的生产者写入,而head正在被你的消费者写入。这两个变量实际上并不是密切相关的,而事实上却要被两个不同内核中运行的线程所使用。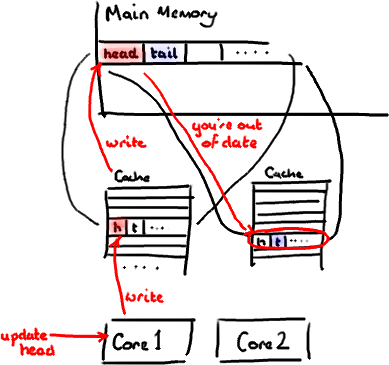
设想你的消费者更新了head的值。缓存中的值和内存中的值都被更新了,而其他所有存储head的缓存行都会都会失效,因为其它缓存中head不是最新值了。请记住我们必须以整个缓存行作为单位来处理(译注:这是CPU的实现所规定的,详细可参见深入分析volatile的实现原理),不能只把head标记为无效。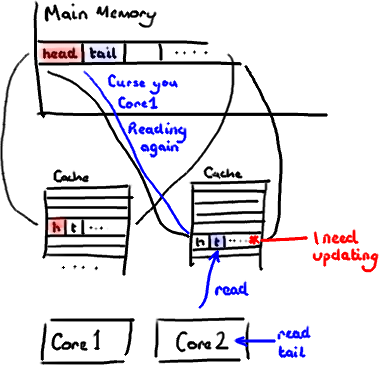
现在如果一些正在其他内核中运行的进程只是想读tail的值,整个缓存行需要从主内存重新读取。那么一个和你的消费者无关的线程读一个和head无关的值,它被缓存未命中给拖慢了。
当然如果两个独立的线程同时写两个不同的值会更糟。因为每次线程对缓存行进行写操作时,每个内核都要把另一个内核上的缓存块无效掉并重新读取里面的数据。你基本上是遇到两个线程之间的写冲突了,尽管它们写入的是不同的变量。
这叫作“伪共享”(译注:可以理解为错误的共享),因为每次你访问head你也会得到tail,而且每次你访问tail,你也会得到head。这一切都在后台发生,并且没有任何编译警告会告诉你,你正在写一个并发访问效率很低的代码。
》》》解决方案:神奇的缓存行填充
你会看到Disruptor消除这个问题,至少对于缓存行大小是64字节或更少的处理器架构来说是这样的(译注:有可能处理器的缓存行是128字节,那么使用64字节填充还是会存在伪共享问题),通过增加补全来确保ring buffer的序列号不会和其他东西同时存在于一个缓存行中。
1 | public long p1, p2, p3, p4, p5, p6, p7; // cache line left padding |
因此没有伪共享,就没有和其它任何变量的意外冲突,没有不必要的缓存未命中。
在你的Entry类中也值得这样做,如果你有不同的消费者往不同的字段写入,你需要确保各个字段间不会出现伪共享。
修改:Martin写了一个从技术上来说更准确更详细的关于伪共享的文章,并且发布了性能测试结果。
伪共享(False Sharing)
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。
当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
缓存行上的写竞争是运行在SMP系统(Symmetric Multi Processing 多处理系统)中并行线程实现可伸缩性最重要的限制因素。
有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
为了让可伸缩性与线程数呈线性关系,就必须确保不会有两个线程往同一个变量或缓存行中写。两个线程写同一个变量可以在代码中发现。为了确定互相独立的变量是否共享了同一个缓存行,就需要了解内存布局,或找个工具告诉我们。Intel VTune就是这样一个分析工具。下面我将解释Java对象的内存布局以及我们该如何填充缓存行以避免伪共享。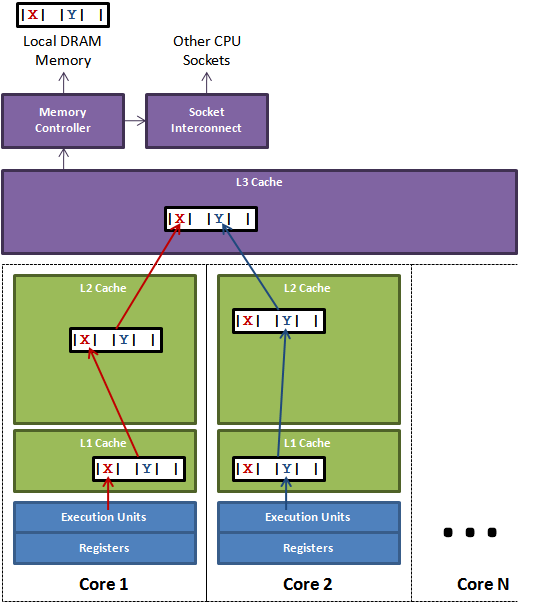
上图说明了伪共享的问题。在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y。不幸的是,这两个变量在同一个缓存行中。每个线程都要去竞争缓存行的所有权来更新变量。如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。当核心2获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,问题可能更加严重。
》》》Java内存布局(Java Memory Layout)
对于HotSpot JVM,所有对象都有两个字长的对象头。第一个字是由24位哈希码和8位标志位(如锁的状态或作为锁对象)组成的Mark Word。第二个字是对象所属类的引用。如果是数组对象还需要一个额外的字来存储数组的长度。每个对象的起始地址都对齐于8字节以提高性能。因此当封装对象的时候为了高效率,对象字段声明的顺序会被重排序成下列基于字节大小的顺序:
- doubles (8) 和 longs (8)
- ints (4) 和 floats (4)
- shorts (2) 和 chars (2)
- booleans (1) 和 bytes (1)
- references (4或8)
- <子类字段重复上述顺序>
(译注:更多HotSpot虚拟机对象结构相关内容:HotSpot 虚拟机对象探秘)
了解这些之后就可以在任意字段间用7个long来填充缓存行。在Disruptor里我们对RingBuffer的cursor和BatchEventProcessor的序列进行了缓存行填充。
为了展示其性能影响,我们启动几个线程,每个都更新它自己独立的计数器。计数器是volatile long类型的,所以其它线程能看到它们的进展。
1 | public final class FalseSharing |
》》》结果(Results)
运行上面的代码,增加线程数以及添加/移除缓存行的填充,下图描述了我得到的结果。这是在我4核CPU上测得的运行时间。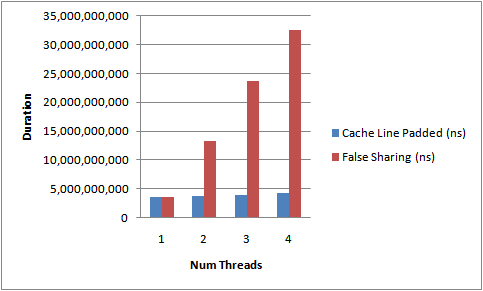
从不断上升的测试所需时间中能够明显看出伪共享的影响。没有缓存行竞争时,我们几近达到了随着线程数的线性扩展。
这并不是个完美的测试,因为我们不能确定这些VolatileLong对象会布局在内存的什么位置。它们是独立的对象。但是经验告诉我们同一时间分配的对象趋向集中于一块。
所以你也看到了,伪共享可能是无声的性能杀手。
注意:更多伪共享相关的内容,请阅读我后续blog。
》》》最新版本 3.4.4,Disruptor伪共享代码
2022-03-15 15:50:26
静态代码块,UNSAFE 操作 Value.value。
它会进行左右填充,左 7x8字节=56字节,右7x8字节=56字节。加上自己共 112 + 8 = 120(15个 long 占用空间),再加上 Object 占用 8 字节,一共 128字节。
cache line 默认 64字节占一行。
所以,无论怎么取,它都能命中,不会造成伪共享问题。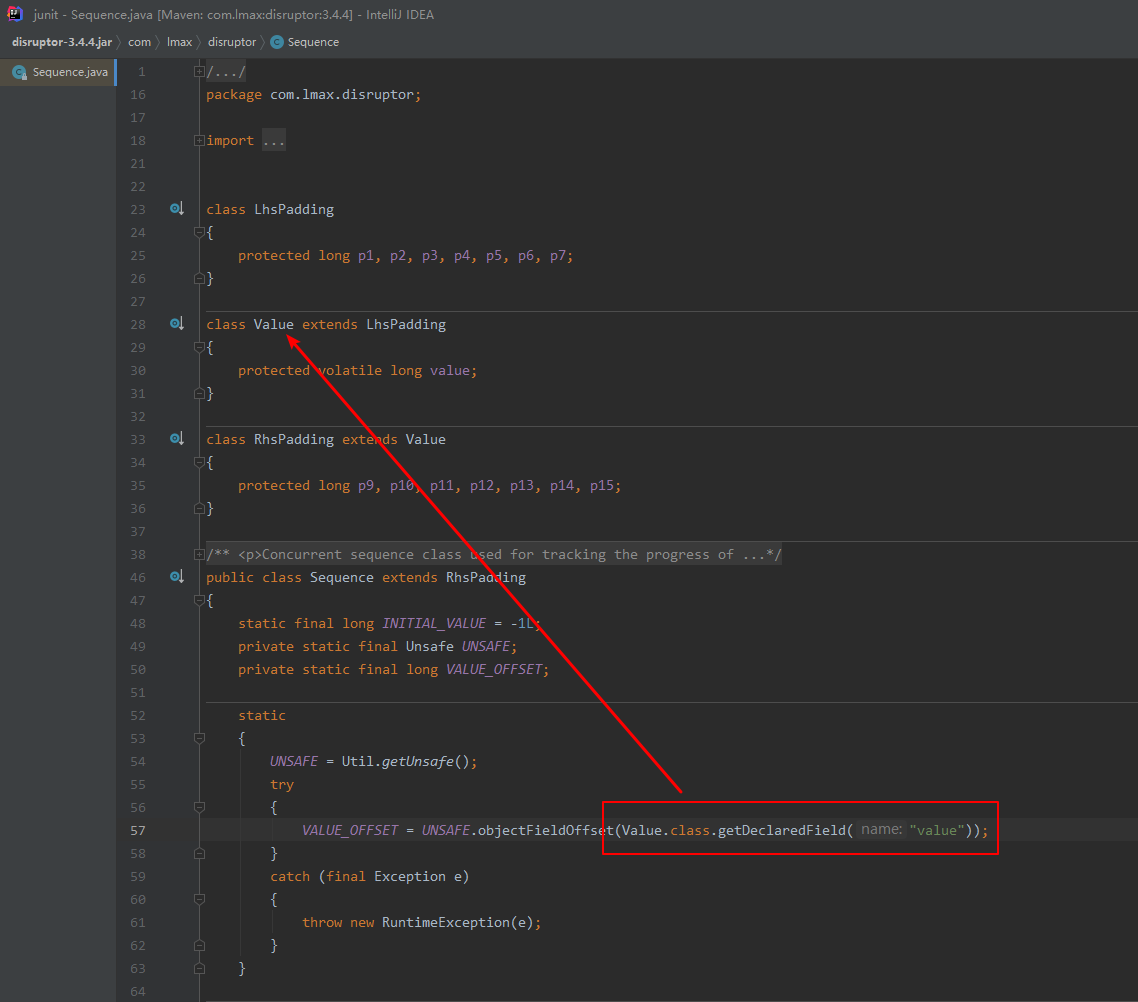
揭秘内存屏障
最近我博客文章更新有点慢,因为我在忙着写一篇介绍内存屏障(Memory Barries)以及如何将其应用于Disruptor的文章。问题是,无论我翻阅了多少资料,向耐心的Martin和Mike请教了多少遍,以试图理清一些知识点,可我总是不能直观地抓到重点。大概是因为我不具备深厚的背景知识来帮助我透彻理解。
所以,与其像个傻瓜一样试图去解释一些自己都没完全弄懂的东西,还不如在抽象和大量简化的层次上,把我在该领域所掌握的知识分享给大家 。Martin已经写了一篇文章《going into memory barriers》介绍内存屏障的一些具体细节,所以我就略过不说了。
免责声明:文章中如有错误全由本人负责,与Disruptor的实现和LMAX里真正懂这些知识的大牛们无关。
》》》主题是什么?
我写这个系列的博客主要目的是解析Disruptor是如何工作的,并深入了解下为什么这样工作。理论上,我应该从可能准备使用disruptor的开发人员的角度来写,以便在代码和技术论文 Disruptor-1.0.pdf 之间搭建一座桥梁。这篇文章提及到了内存屏障,我想弄清楚它们到底是什么,以及它们是如何应用于实践中的。
》》》什么是内存屏障?
它是一个CPU指令。没错,又一次,我们在讨论CPU级别的东西,以便获得我们想要的性能(Martin著名的Mechanical Sympathy理论)。基本上,它是这样一条指令: a)确保一些特定操作执行的顺序; b)影响一些数据的可见性(可能是某些指令执行后的结果)。
编译器和CPU可以在保证输出结果一样的情况下对指令重排序,使性能得到优化。插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行。正如去拉斯维加斯旅途中各个站点的先后顺序在你心中都一清二楚。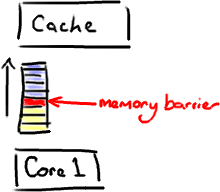
内存屏障另一个作用是强制更新一次不同CPU的缓存。例如,一个写屏障会把这个屏障前写入的数据刷新到缓存,这样任何试图读取该数据的线程将得到最新值,而不用考虑到底是被哪个cpu核心或者哪个CPU执行的。
》》》和Java有什么关系?
现在我知道你在想什么——这不是汇编程序。它是Java。
这里有个神奇咒语叫volatile(我觉得这个词在Java规范中从未被解释清楚)。如果你的字段是volatile,Java内存模型将在写操作后插入一个写屏障指令,在读操作前插入一个读屏障指令。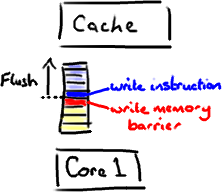
这意味着如果你对一个volatile字段进行写操作,你必须知道:
1、一旦你完成写入,任何访问这个字段的线程将会得到最新的值。
2、在你写入前,会保证所有之前发生的事已经发生,并且任何更新过的数据值也是可见的,因为内存屏障会把之前的写入值都刷新到缓存。
》》》举个栗子!
很高兴你这样说了。又是时候让我来画几个甜甜圈了。
RingBuffer的指针(cursor)(译注:指向队尾元素)属于一个神奇的volatile变量,同时也是我们能够不用锁操作就能实现Disruptor的原因之一。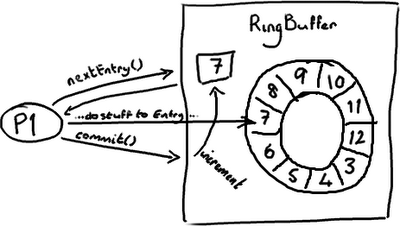
生产者将会取得下一个Entry(或者是一批),并可对它(们)作任意改动, 把它(们)更新为任何想要的值。如你所知,在所有改动都完成后,生产者对ring buffer调用commit方法来更新序列号(译注:把cursor更新为该Entry的序列号)。对volatile字段(cursor)的写操作创建了一个内存屏障,这个屏障将刷新所有缓存里的值(或者至少相应地使得缓存失效)。
这时候,消费者们能获得最新的序列号码(8),并且因为内存屏障保证了它之前执行的指令的顺序,消费者们可以确信生产者对7号Entry所作的改动已经可用。
》》》…那么消费者那边会发生什么?
消费者中的序列号是volatile类型的,会被若干个外部对象读取——其他的下游消费者可能在跟踪这个消费者。ProducerBarrier/RingBuffer(取决于你看的是旧的还是新的代码)跟踪它以确保环没有出现重叠(wrap)的情况(译注:为了防止下游的消费者和上游的消费者对同一个Entry竞争消费,导致在环形队列中互相覆盖数据,下游消费者要对上游消费者的消费情况进行跟踪)。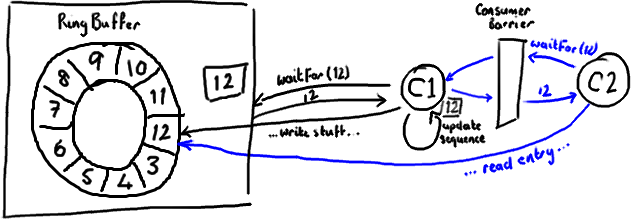
所以,如果你的下游消费者(C2)看见前一个消费者(C1)在消费号码为12的Entry,当C2的读取也到了12,它在更新序列号前将可以获得C1对该Entry的所作的更新。
基本来说就是,C1更新序列号前对ring buffer的所有操作(如上图黑色所示),必须先发生,待C2拿到C1更新过的序列号之后,C2才可以为所欲为(如上图蓝色所示)。
》》》对性能的影响
内存屏障作为另一个CPU级的指令,没有锁那样大的开销。内核并没有在多个线程间干涉和调度。但凡事都是有代价的。内存屏障的确是有开销的——编译器/cpu不能重排序指令,导致不可以尽可能地高效利用CPU,另外刷新缓存亦会有开销。所以不要以为用volatile代替锁操作就一点事都没。
你会注意到Disruptor的实现对序列号的读写频率尽量降到最低。对volatile字段的每次读或写都是相对高成本的操作。但是,也应该认识到在批量的情况下可以获得很好的表现。如果你知道不应对序列号频繁读写,那么很合理的想到,先获得一整批Entries,并在更新序列号前处理它们。这个技巧对生产者和消费者都适用。以下的例子来自BatchConsumer:
1 | long nextSequence = sequence + 1;// [1] sequence 是 volatile,对其操作会消耗一定的性能 |
(你会注意到,这是个旧式的代码和命名习惯,因为这是摘自我以前的博客文章,我认为如果直接转换为新式的代码和命名习惯会让人有点混乱)
在上面的代码中,我们在消费者处理entries的循环中用一个局部变量(nextSequence)来递增。这表明我们想尽可能地减少对volatile类型的序列号的进行读写(可参考上面注释)。
》》》总结
内存屏障是CPU指令,它允许你对数据什么时候对其他进程可见作出假设。在Java里,你使用volatile关键字来实现内存屏障。使用volatile意味着你不用被迫选择加锁,并且还能让你获得性能的提升。
但是,你需要对你的设计进行一些更细致的思考,特别是你对volatile字段的使用有多频繁,以及对它们的读写有多频繁。
PS:上文中讲到的Disruptor中使用的 New World Order 是一种完全不同于我目前为止所发表的博文中的命名习惯。我想下一篇文章会对旧式的和新式的命名习惯做一个对照。
延伸阅读:
[1] 一种高效无锁内存队列的实现
[3] Disruptor系列译文
Disruptor如何工作和使用
*Ringbuffer的特别之处
最近,我们开源了LMAX Disruptor,它是我们的交易系统吞吐量快(LMAX是一个新型的交易平台,号称能够单线程每秒处理数百万的订单)的关键原因。为什么我们要将其开源?我们意识到对高性能编程领域的一些传统观点,有点不对劲。我们找到了一种更好、更快地在线程间共享数据的方法,如果不公开于业界共享的话,那未免太自私了。同时开源也让我们觉得看起来更酷。
从这个站点,你可以下载到一篇解释什么是Disruptor及它为什么如此高性能的文档。这篇文档的编写过程,我并没有参与太多,只是简单地插入了一些标点符号和重组了一些我不懂的句子,但是非常高兴的是,我仍然从中提升了自己的写作水平。
我发现要把所有的事情一下子全部解释清楚还是有点困难的,所有我准备一部分一部分地解释它们,以适合我的NADD听众。
首先介绍ringbuffer。我对Disruptor的最初印象就是ringbuffer。但是后来我意识到尽管ringbuffer是整个模式(Disruptor)的核心,但是Disruptor对ringbuffer的访问控制策略才是真正的关键点所在。
》》》ringbuffer到底是什么?
嗯,正如名字所说的一样,它是一个环(首尾相接的环),你可以把它用做在不同上下文(线程)间传递数据的buffer。
(好吧,这是我通过画图板手画的,我试着画草图,希望我的强迫症不会让我画完美的圆和直线)
基本来说,ringbuffer拥有一个序号,这个序号指向数组中下一个可用的元素。(校对注:如下图右边的图片表示序号,这个序号指向数组的索引4的位置。)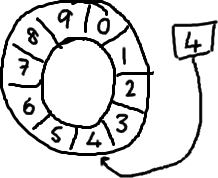
随着你不停地填充这个buffer(可能也会有相应的读取),这个序号会一直增长,直到绕过这个环。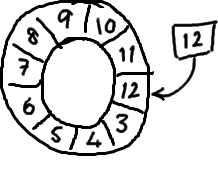
要找到数组中当前序号指向的元素,可以通过mod操作:sequence mod array length = array index
以上面的ringbuffer为例(java的mod语法):12 % 10 = 2。很简单吧。
事实上,上图中的ringbuffer只有10个槽完全是个意外。如果槽的个数是2的N次方更有利于基于二进制的计算机进行计算。
(校对注:2的N次方换成二进制就是1000,100,10,1这样的数字, sequence & (array length-1) = array index,比如一共有8槽,3 &(8-1)=3,HashMap就是用这个方式来定位数组元素的,这种方式比取模的速度更快。)
》》》那又怎么样?
如果你看了维基百科里面的关于环形buffer的词条,你就会发现,我们的实现方式,与其最大的区别在于:没有尾指针。我们只维护了一个指向下一个可用位置的序号。这种实现是经过深思熟虑的—我们选择用环形buffer的最初原因就是想要提供可靠的消息传递。我们需要将已经被服务发送过的消息保存起来,这样当另外一个服务通过nak (校对注:拒绝应答信号)告诉我们没有成功收到消息时,我们能够重新发送给他们。
听起来,环形buffer非常适合这个场景。它维护了一个指向尾部的序号,当收到nak(校对注:拒绝应答信号)请求,可以重发从那一点到当前序号之间的所有消息: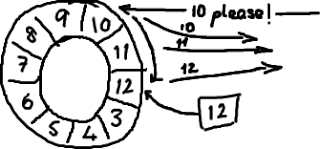
我们实现的ring buffer和大家常用的队列之间的区别是,我们不删除buffer中的数据,也就是说这些数据一直存放在buffer中,直到新的数据覆盖他们。这就是和维基百科版本相比,我们不需要尾指针的原因。ringbuffer本身并不控制是否需要重叠(决定是否重叠是生产者-消费者行为模式的一部分–如果你等不急我写blog来说明它们,那么可以自行检出Disruptor项目)。
》》》它为什么如此优秀?
之所以ringbuffer采用这种数据结构,是因为它在可靠消息传递方面有很好的性能。这就够了,不过它还有一些其他的优点。
首先,因为它是数组,所以要比链表快,而且有一个容易预测的访问模式。(译者注:数组内元素的内存地址的连续性存储的)。这是对CPU缓存友好的—也就是说,在硬件级别,数组中的元素是会被预加载的,因此在ringbuffer当中,cpu无需时不时去主存加载数组中的下一个元素。(校对注:因为只要一个元素被加载到缓存行,其他相邻的几个元素也会被加载进同一个缓存行)
其次,你可以为数组预先分配内存,使得数组对象一直存在(除非程序终止)。这就意味着不需要花大量的时间用于垃圾回收。此外,不像链表那样,需要为每一个添加到其上面的对象创造节点对象—对应的,当删除节点时,需要执行相应的内存清理操作。
》》》缺少的部分
我并没有在本文中介绍如何避免ringbuffer产生重叠,以及如何对ringbuffer进行读写操作。你可能注意到了我将ringbuffer和链表那样的数据结构进行比较,因为我并认为链表是实际问题的标准答案。
当你将Disruptor和基于 队列之类的实现进行比较时,事情将变得很有趣。队列通常注重维护队列的头尾元素,添加和删除元素等。所有的这些我都没有在ringbuffer里提到,这是因为ringbuffer不负责这些事情,我们把这些操作都移到了数据结构(ringbuffer)的外部
到这个站点阅读文章或者检出代码可以了解更多细节。或者观看Mike 和Martin在去年San Francisco QCon大会上的视频,或者再等我一些时间来思考剩下的东西,然后在接下来的blog中逐一介绍。
*读取 Ringbuffer
从上面文章中我们都了解了什么是Ring Buffer以及它是如何的特别。但遗憾的是,我还没有讲述如何使用Disruptor向Ring Buffer写数据和从Ring Buffer中读取数据。
》》》ConsumerBarrier与消费者
这里我要稍微反过来介绍,因为总的来说读取数据这一过程比写数据要容易理解。
假设通过一些“魔法”已经把数据写入到Ring Buffer了,怎样从Ring Buffer读出这些数据呢?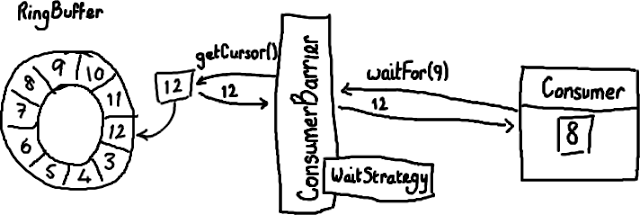
消费者(Consumer)是一个想从Ring Buffer里读取数据的线程,它可以访问ConsumerBarrier对象——这个对象由RingBuffer创建并且代表消费者与RingBuffer进行交互。就像Ring Buffer显然需要一个序号才能找到下一个可用节点一样,消费者也需要知道它将要处理的序号——每个消费者都需要找到下一个它要访问的序号。在上面的例子中,消费者处理完了Ring Buffer里序号8之前(包括8)的所有数据,那么它期待访问的下一个序号是9。
消费者可以调用ConsumerBarrier对象的waitFor()方法,传递它所需要的下一个序号。
1 | final long availableSeq = consumerBarrier.waitFor(nextSequence); |
ConsumerBarrier返回RingBuffer的最大可访问序号:在上面的例子中是12。ConsumerBarrier有一个WaitStrategy方法来决定它如何等待这个序号,我现在不会去描述它的细节,代码的注释里已经概括了每一种WaitStrategy的优点和缺点 。
》》》接下来怎么做?
接下来,消费者会一直原地停留,等待更多数据被写入Ring Buffer。并且,一旦数据写入后消费者会收到通知——节点9,10,11和12 已写入。现在序号12到了,消费者可以让ConsumerBarrier去拿这些序号节点里的数据了。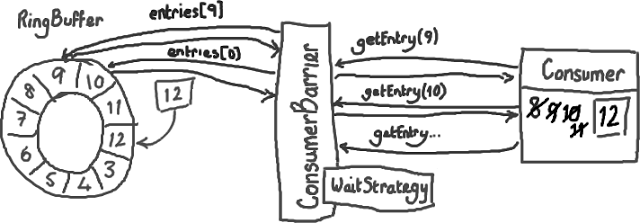
拿到了数据后,消费者(Consumer)会更新自己的标识(cursor)。
你应该已经感觉得到,这样做是怎样有助于平缓延迟的峰值了——以前需要逐个节点地询问“我可以拿下一个数据吗?现在可以了么?现在呢?”,消费者(Consumer)现在只需要简单的说“当你拿到的数字比我这个要大的时候请告诉我”,函数返回值会告诉它有多少个新的节点可以读取数据了。因为这些新的节点的确已经写入了数据(Ring Buffer本身的序号已经更新),而且消费者对这些节点的唯一操作是读而不是写,因此访问不用加锁。这太好了,不仅代码实现起来可以更加安全和简单,而且不用加锁使得速度更快。
另一个好处是——你可以用多个消费者(Consumer)去读同一个RingBuffer ,不需要加锁,也不需要用另外的队列来协调不同的线程(消费者)。这样你可以在Disruptor的协调下实现真正的并发数据处理。
BatchConsumer代码是一个消费者的例子。如果你实现了BatchHandler, 你可以用BatchConsumer来完成上面我提到的复杂工作。它很容易对付那些需要成批处理的节点(例如上文中要处理的9-12节点)而不用单独地去读取每一个节点。
更新:注意Disruptor 2.0版本使用了与本文不一样的命名。如果你对类名感到困惑,请阅读我的变更总结。
*写入 Ringbuffer
这是 Disruptor 全方位解析(end-to-end view)中缺少的一章。当心,本文非常长。但是为了让你能联系上下文阅读,我还是决定把它们写进一篇博客里。
本文的 重点 是:不要让 Ring 重叠;如何通知消费者;生产者一端的批处理;以及多个生产者如何协同工作。
》》》ProducerBarriers
Disruptor 代码 给 消费者 提供了一些接口和辅助类,但是没有给写入 Ring Buffer 的 生产者 提供接口。这是因为除了你需要知道生产者之外,没有别人需要访问它。尽管如此,Ring Buffer 还是与消费端一样提供了一个 ProducerBarrier 对象,让生产者通过它来写入 Ring Buffer。
写入 Ring Buffer 的过程涉及到两阶段提交 (two-phase commit)。首先,你的生产者需要申请 buffer 里的下一个节点。然后,当生产者向节点写完数据,它将会调用 ProducerBarrier 的 commit 方法。
那么让我们首先来看看第一步。 “给我 Ring Buffer 里的下一个节点”,这句话听起来很简单。的确,从生产者角度来看它很简单:简单地调用 ProducerBarrier 的 nextEntry() 方法,这样会返回给你一个 Entry 对象,这个对象就是 Ring Buffer 的下一个节点。
》》》ProducerBarrier 如何防止 Ring Buffer 重叠
在后台,由 ProducerBarrier 负责所有的交互细节来从 Ring Buffer 中找到下一个节点,然后才允许生产者向它写入数据。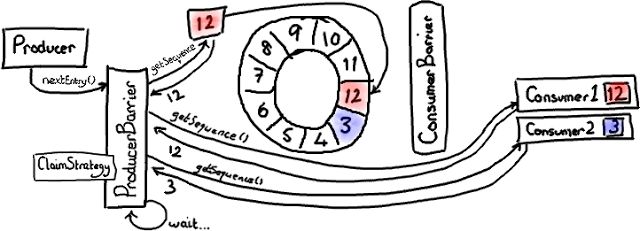
(我不确定 闪闪发亮的新手写板 能否有助于提高我画图片的清晰度,但是它用起来很有意思)。
在这幅图中,我们假设只有一个生产者写入 Ring Buffer。过一会儿我们再处理多个生产者的复杂问题。
ConsumerTrackingProducerBarrier 对象拥有所有正在访问 Ring Buffer 的 消费者 列表。这看起来有点儿奇怪-我从没有期望 ProducerBarrier 了解任何有关消费端那边的事情。但是等等,这是有原因的。因为我们不想与队列“混为一谈”(队列需要追踪队列的头和尾,它们有时候会指向相同的位置),Disruptor 由消费者负责通知它们处理到了哪个序列号,而不是 Ring Buffer。所以,如果我们想确定我们没有让 Ring Buffer 重叠,需要检查所有的消费者们都读到了哪里。
在上图中,有一个 消费者 顺利的读到了最大序号 12(用红色/粉色高亮)。第二个消费者 有点儿落后——可能它在做 I/O 操作之类的——它停在序号 3。因此消费者 2 在赶上消费者 1 之前要跑完整个 Ring Buffer 一圈的距离。
现在生产者想要写入 Ring Buffer 中序号 3 占据的节点,因为它是 Ring Buffer 当前游标的下一个节点。但是 ProducerBarrier 明白现在不能写入,因为有一个消费者正在占用它。所以,ProducerBarrier 停下来自旋 (spins),等待,直到那个消费者离开。
》》》申请下一个节点
现在可以想像消费者 2 已经处理完了一批节点,并且向前移动了它的序号。可能它挪到了序号 9(因为消费端的批处理方式,现实中我会预计它到达 12,但那样的话这个例子就不够有趣了)。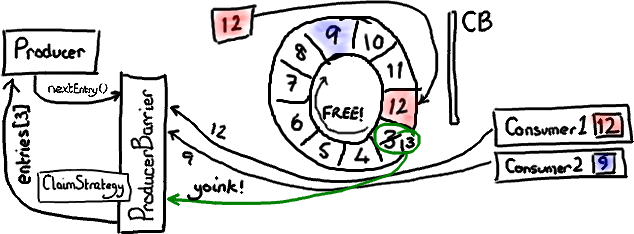
上图显示了当消费者 2 挪动到序号 9 时发生的情况。在这张图中我已经忽略了ConsumerBarrier,因为它没有参与这个场景。
ProducerBarier 会看到下一个节点——序号 3 那个已经可以用了。它会抢占这个节点上的 Entry(我还没有特别介绍 Entry 对象,基本上它是一个放写入到某个序号的 Ring Buffer 数据的桶),把下一个序号(13)更新成 Entry 的序号,然后把 Entry 返回给生产者。生产者可以接着往 Entry 里写入数据。
》》》提交新的数据
两阶段提交的第二步是:对,提交。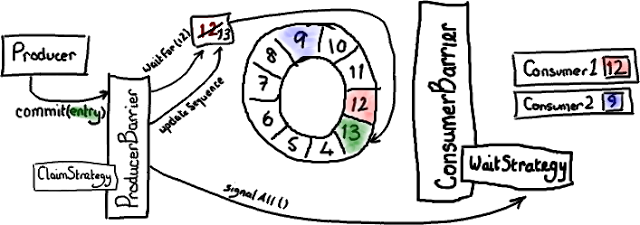
绿色表示最近写入的 Entry,序号是 13 ——厄,抱歉,我也是红绿色盲。但是其他颜色甚至更糟糕。
当生产者结束向 Entry 写入数据后,它会要求 ProducerBarrier 提交。
ProducerBarrier 先等待 Ring Buffer 的游标追上当前的位置(对于单生产者这毫无意义-比如,我们已经知道游标到了 12 ,而且没有其他人正在写入 Ring Buffer)。然后 ProducerBarrier 更新 Ring Buffer 的游标到刚才写入的 Entry 序号-在我们这儿是 13。接下来,ProducerBarrier 会让消费者知道 buffer 中有新东西了。它戳一下 ConsumerBarrier 上的 WaitStrategy 对象说-“喂,醒醒!有事情发生了!”(注意-不同的 WaitStrategy 实现以不同的方式来实现提醒,取决于它是否采用阻塞模式。)
现在消费者 1 可以读 Entry 13 的数据,消费者 2 可以读 Entry 13 以及前面的所有数据,然后它们都过得很 happy。
》》》ProducerBarrier 上的批处理
有趣的是 Disruptor 可以同时在生产者和 消费者 两端实现批处理。还记得伴随着程序运行,消费者 2 最后达到了序号 9 吗?ProducerBarrier 可以在这里做一件很狡猾的事-它知道 Ring Buffer 的大小,也知道最慢的消费者位置。因此它能够发现当前有哪些节点是可用的。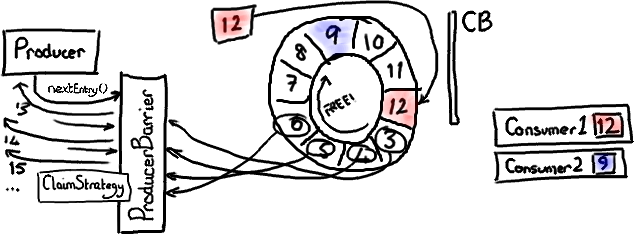
如果 ProducerBarrier 知道 Ring Buffer 的游标指向 12,而最慢的消费者在 9 的位置,它就可以让生产者写入节点 3,4,5,6,7 和 8,中间不需要再次检查消费者的位置。
》》》多个生产者的场景
到这里你也许会以为我讲完了,但其实还有一些细节。
在上面的图中我稍微撒了个谎。我暗示了 ProducerBarrier 拿到的序号直接来自 Ring Buffer 的游标。然而,如果你看过代码的话,你会发现它是通过 ClaimStrategy 获取的。我省略这个对象是为了简化示意图,在单个生产者的情况下它不是很重要。
在多个生产者的场景下,你还需要其他东西来追踪序号。这个序号是指当前可写入的序号。注意这和“向 Ring Buffer 的游标加 1”不一样-如果你有一个以上的生产者同时在向 Ring Buffer 写入,就有可能出现某些 Entry 正在被生产者写入但还没有提交的情况。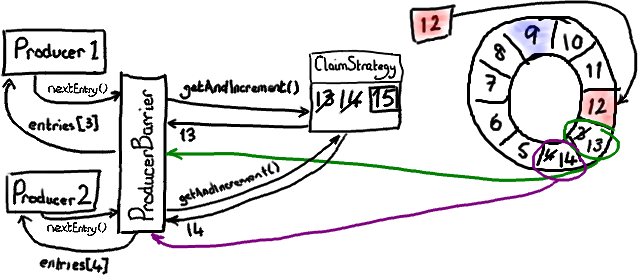
让我们复习一下如何申请写入节点。每个生产者都向 ClaimStrategy 申请下一个可用的节点。生产者 1 拿到序号 13,这和上面单个生产者的情况一样。生产者 2 拿到序号 14,尽管 Ring Buffer的当前游标仅仅指向 12。这是因为 ClaimSequence 不但负责分发序号,而且负责跟踪哪些序号已经被分配。
现在每个生产者都拥有自己的写入节点和一个崭新的序号。
我把生产者 1 和它的写入节点涂上绿色,把生产者 2 和它的写入节点涂上可疑的粉色-看起来像紫色。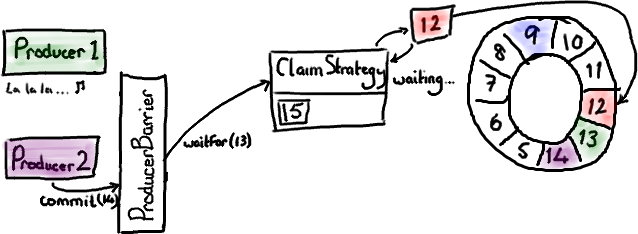
现在假设生产者 1 还生活在童话里,因为某些原因没有来得及提交数据。生产者 2 已经准备好提交了,并且向 ProducerBarrier 发出了请求。
就像我们先前在 commit 示意图中看到的一样,ProducerBarrier 只有在 Ring Buffer 游标到达准备提交的节点的前一个节点时它才会提交。在当前情况下,游标必须先到达序号 13 我们才能提交节点 14 的数据。但是我们不能这样做,因为生产者 1 正盯着一些闪闪发光的东西,还没来得及提交。因此 ClaimStrategy 就停在那儿自旋 (spins), 直到 Ring Buffer 游标到达它应该在的位置。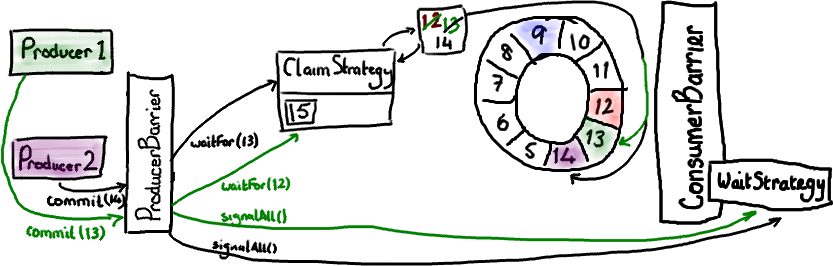
现在生产者 1 从迷糊中清醒过来并且申请提交节点 13 的数据(生产者 1 发出的绿色箭头代表这个请求)。ProducerBarrier 让 ClaimStrategy 先等待 Ring Buffer 的游标到达序号 12,当然现在已经到了。因此 Ring Buffer 移动游标到 13,让 ProducerBarrier 戳一下 WaitStrategy 告诉所有人都知道 Ring Buffer 有更新了。现在 ProducerBarrier 可以完成生产者 2 的请求,让 Ring Buffer 移动游标到 14,并且通知所有人都知道。
你会看到,尽管生产者在不同的时间完成数据写入,但是 Ring Buffer 的内容顺序总是会遵循 nextEntry() 的初始调用顺序。也就是说,如果一个生产者在写入 Ring Buffer 的时候暂停了,只有当它解除暂停后,其他等待中的提交才会立即执行。
呼——。我终于设法讲完了这一切的内容并且一次也没有提到内存屏障(Memory Barrier)。
更新:最近的 RingBuffer 版本去掉了 Producer Barrier。如果在你看的代码里找不到 ProducerBarrier,那就假设当我讲“Producer Barrier”时,我的意思是“Ring Buffer”。
更新2:注意 Disruptor 2.0 版使用了与本文不一样的命名。如果你对类名感到困惑,请阅读我写的Disruptor 2.0更新摘要。
解析Disruptor的依赖关系
现在我已经讲了 RingBuffer 本身,如何从它 读取 以及如何向它 写入。从逻辑上来说,下一件要做的事情就是把所有的东西拼装到在一起。
我前面提到过多生产者的情况——他们通过 ProducerBarrier 保证写入操作顺序与可控。我也提到过简单场景下的多消费者数据访问。更多的消费者的场景会变得更加复杂,我们 实现了一些聪明的机制允许多个消费者在访问 Ring Buffer 的时候互相等待(依赖)。像很多应用里,有一连串的工作需要在实际执行业务逻辑之前完成 (happen before) —— 例如,在做任何操作之前,我们都必须先保证消息写入磁盘。
Disruptor 论文 和性能测试里包含了你可能想到的一些基本结构。我准备讲一下其中最有趣的那个,这多半是因为我需要练习如何使用画图板。
》》》菱形结构
DiamondPath1P3CPerfTest 展示了一个并不罕见的结构——独立的一个生产者和三个消费者。最棘手的一点是:第三个消费者必须等待前两个消费者处理完成后,才能开始工作。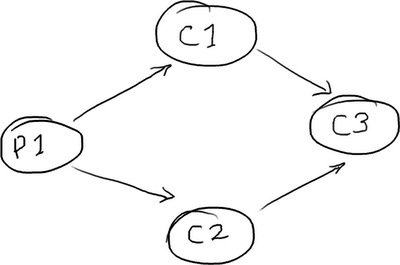
消费者 C3 也许是你的业务逻辑。消费者 C1 可能在备份接收到的数据,而消费者 C2 可能在准备数据或者别的东西。
》》》用队列实现菱形结构
在一个 SEDA-风格的架构 中,每个处理阶段都会用队列分开: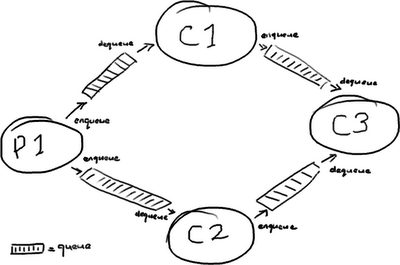
(为什么单词 Queue 里必须有这么多 “e” 呢?这是我在画这些图时遇到的最麻烦的词)。
你也许从这里看到了问题的端倪:一条消息从 P1 传输到 C3 要完整的穿过四个队列,每个队列在消息进入队列和取出队列时都会产生消耗成本。
》》》用 Disruptor 实现菱形结构
在 Disruptor 的世界里,一切都由一个单独的 Ring Buffer 管理: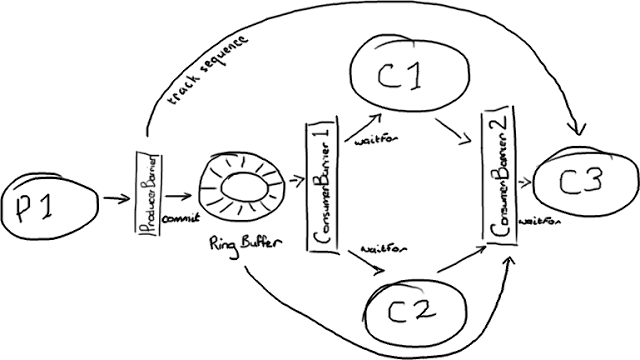
这张图看起来更复杂。不过所有的参与者都只依赖 Ring Buffer 作为一个单独的联结点,而且所有的交互都是基于 Barrier 对象与检查依赖的目标序号来实现的。
生产者这边比较简单,它是我在 上文 中描述过的单生产者模型。有趣的是,生产者并不需要关心所有的消费者。它只关心消费者 C3,如果消费者 C3 处理完了 Ring Buffer 的某一个节点,那么另外两个消费者肯定也处理完了。因此,只要 C3 的位置向前移动,Ring Buffer 的后续节点就会空闲出来。
管理消费者的依赖关系需要两个 ConsumerBarrier 对象。第一个仅仅与 Ring Buffer 交互,C1 和 C2 消费者向它申请下一个可访问节点。第二个 ConsumerBarrier 只知道消费者 C1 和 C2,它返回两个消费者访问过的消息序号中较小的那个。
》》》Disruptor 怎样实现消费者等待(依赖)
Hmmm。我想需要一个例子。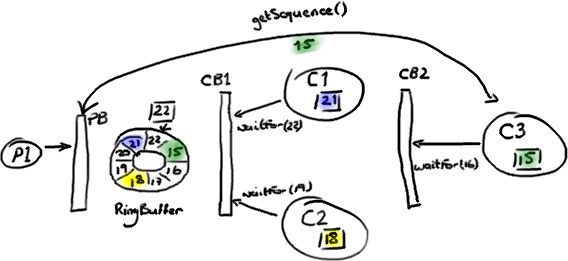
我们从这个故事发生到一半的时候来看:生产者 P1 已经在 Ring Buffer 里写到序号 22 了,消费者 C1 已经访问和处理完了序号 21 之前的所有数据。消费者 C2 处理到了序号 18。消费者 C3,就是依赖其他消费者的那个,才处理到序号 15。
生产者 P1 不能继续向 RingBuffer 写入数据了,因为序号 15 占据了我们想要写入序号 23 的数据节点 (Slot)。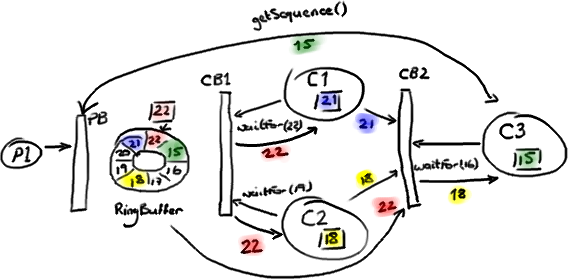
(抱歉,我真的试过用其他颜色来代替红色和绿色,但是别的都更容易混淆。)
第一个 ConsumerBarrier(CB1)告诉 C1 和 C2 消费者可以去访问序号 22 前面的所有数据,这是 Ring Buffer 中的最大序号。第二个 ConsumerBarrier (CB2) 不但会检查 RingBuffer 的序号,也会检查另外两个消费者的序号并且返回它们之间的最小值。因此,三号消费者被告知可以访问 Ring Buffer 里序号 18 前面的数据。
注意这些消费者还是直接从 Ring Buffer 拿数据节点——并不是由 C1 和 C2 消费者把数据节点从 Ring Buffer 里取出再传递给 C3 消费者的。作为替代的是,由第二个 ConsumerBarrier 告诉 C3 消费者,在 RingBuffer 里的哪些节点可以安全的处理。
这产生了一个问题——如果任何数据都来自于 Ring Buffer,那么 C3 消费者如何读到前面两个消费者处理完成的数据呢?如果 C3 消费者关心的只是先前的消费者是否已经完成它们的工作(例如,把数据复制到别的地方),那么这一切都没有问题—— C3 消费者知道工作已完成就放心了。但是,如果 C3 消费者需要访问先前的消费者的处理结果,它又从哪里去获取呢?
》》》更新数据节点
秘密在于把处理结果写入 Ring Buffer 数据节点 (Entry) 本身。这样,当 C3 消费者从 Ring Buffer 取出节点时,它已经填充好了 C3 消费者工作需要的所有信息。这里 真正 重要的地方是节点 (Entry) 对象的每一个字段应该只允许一个消费者写入。这可以避免产生并发写入冲突 (write-contention) 减慢了整个处理过程。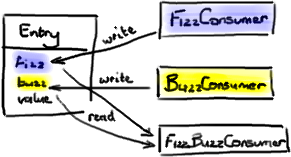
你可以在 DiamondPath1P3CPerfTest 里看到这个例子—— FizzBuzzEntry 有两个字段:fizz 和 buzz。如果消费者是 Fizz Consumer, 它只写入字段 fizz。如果是 Buzz Consumer, 它只写入字段 buzz。第三个消费者 FizzBuzz,它只去读这两个字段但是不会做写入,因为读没问题,不会引起争用。
》》》一些实际的 Java 代码
这一切看起来都要比队列实现更复杂。是的,它涉及到更多的内部协调。但是这些细节对于消费者和生产者是隐藏的,它们只和 Barrier 对象交互。诀窍在消费者结构里。上文例子中提到的菱形结构可以用下面的方法创建:
为了方便理解,我使用换行来隔开
1 | ConsumerBarrier consumerBarrier1 = ringBuffer.createConsumerBarrier(); |
》》》总结
现在你知道了:如何关联 Disruptor 与相互依赖(等待)的多个消费者。关键点如下:
- 使用多个 ConsumerBarrier 来管理消费者之间的依赖(等待)关系。
- 使用 ProducerBarrier 监视结构图中最后一个消费者。
- 只允许一个消费者更新数据节点 (Entry) 的每一个独立字段。
更新:Adrian 写了一个非常好的 DSL 工具让拼接 Disruptor 更加简单了。
更新 2:注意 Disruptor 2.0 版使用了与本文不一样的命名。如果你对类名感到困惑,请阅读我的 变更总结。另外,Adrian 的 DSL 工具现在是 Disruptor 主干代码的一部分了。
Disruptor(无锁并发框架)-发布
假如你生活在另外一个星球,我们最近开源了一套高性能的基于消息传递的开源框架。
下面我给大家介绍一下如何将消息通过Ring buffer在无锁的情况下进行处理。
在深入介绍之前,可以先快速阅读一下Trish发表的文章,该文章介绍了ring buffer和其工作原理。
这篇文章的要点如下:
1、ring buffer是由一个大数组组成的。
2、所有ring buffer的“指针”(也称为序列或游标)是java long类型的(64位有符号数),指针采用往上计数自增的方式。(不用担心越界,即使每秒1,000,000条消息,也要消耗300,000年才可以用完)。
3、对ring buffer中的指针进行按ring buffer的size取模找出数组的下标来定位入口(类似于HashMap的entry)。为了提高性能,我们通常将ring buffer的size大小设置成实际使用的2倍。
这样我们可以通过位运算(bit-mask )的方式计算出数组的下标。
》》》Ring buffer的基础结构
注意:和代码中的实际实现,我这里描述的内容是进行了简化和抽象的。从概念上讲,我认为更加方面理解。
ring buffer维护两个指针,“next”和“cursor”。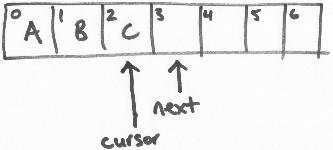
在上面的图示里,是一个size为7的ring buffer(你应该知道这个手工绘制的图示的原理),从0-2的坐标位置是填充了数据的。
“next”指针指向第一个未填充数据的区块。“cursor”指针指向最后一个填充了数据的区块。在一个空闲的ring bufer中,它们是彼此紧邻的,如上图所示。
》》》填充数据(Claiming a slot,获取区块)
Disruptor API 提供了事务操作的支持。当从ring buffer获取到区块,先是往区块中写入数据,然后再进行提交的操作。
假设有一个线程负责将字母“D”写进ring buffer中。将会从ring buffer中获取一个区块(slot),这个操作是一个基于CAS的“get-and-increment”操作,将“next”指针进行自增。这样,当前线程(我们可以叫做线程D)进行了get-and-increment操作后,
指向了位置4,然后返回3。这样,线程D就获得了位置3的操作权限。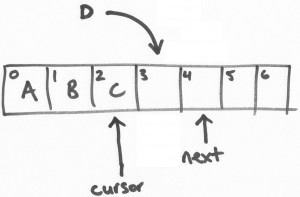
接着,另一个线程E做类似以上的操作。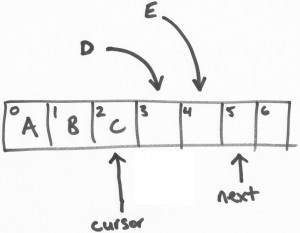
》》》提交写入
以上,线程D和线程E都可以同时线程安全的往各自负责的区块(或位置,slots)写入数据。但是,我们可以讨论一下线程E先完成任务的场景…
线程E尝试提交写入数据。在一个繁忙的循环中有若干的CAS提交操作。线程E持有位置4,它将会做一个CAS的waiting操作,直到 “cursor”变成3,然后将“cursor”变成4。
再次强调,这是一个原子性的操作。因此,现在的ring buffer中,“cursor”现在是2,线程E将会进入长期等待并重试操作,直到 “cursor”变成3。
然后,线程D开始提交。线程E用CAS操作将“cursor”设置为3(线程E持有的区块位置)当且仅当“cursor”位置是2.“cursor”当前是2,所以CAS操作成功和提交也成功了。
这时候,“cursor”已经更新成3,然后所有和3相关的数据变成可读。
这是一个关键点。知道ring buffer填充了多少 – 即写了多少数据,那一个序列数写入最高等等,是游标的一些简单的功能。“next”指针是为了保证写入的事务特性。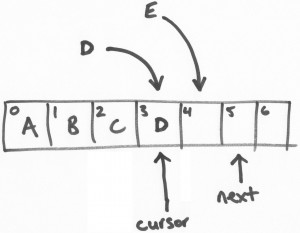
最后的疑惑是线程E的写入可见,线程E一直重试,尝试将“cursor”从3更新成4,经过线程D操作后已经更新成3,那么下一次重试就可以成功了。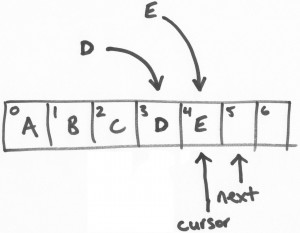
》》》总结
写入数据可见的先后顺序是由线程所抢占的位置的先后顺序决定的,而不是由它的提交先后决定的。但你可以想象这些线程从网络层中获取消息,这是和消息按照时间到达的先后顺序是没什么不同的,而两个线程竞争获取一个不同循序的位置。
因此,这是一个简单而优雅的算法,写操作是原子的,事务性和无锁,即使有多个写入线程。
LMAX Disruptor:一个高性能、低延迟且简单的框架
Disruptor是一个用于在线程间通信的高效低延时的消息组件,它像个增强的队列,并且它是让LMAX Exchange跑的如此之快的一个关键创新。关于什么是Disruptor、为何它很重要以及它的工作原理方面的信息都呈爆炸性增长 —— 这些文章很适合开始学习Disruptor,还可跟着LMAX BLOG深入学习。这里还有一份更详细的白皮书。
虽然disruptor模式使用起来很简单,但是建立多个消费者以及它们之间的依赖关系需要的样板代码太多了。为了能快速又简单适用于99%的场景,我为Disruptor模式准备了一个简单的DSL(领域特定语言)。例如,为建立一个消费者的“四边形模式”: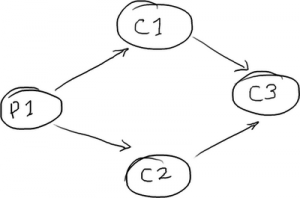
(从Trisha Gee’s excellent series explaining the disruptor pattern偷来的图片)
在这种情况下,只要生产者(P1)将元素放到ring buffer上,消费者C1和C2就可以并行处理这些元素。但是消费者C3必须一直等到C1和C2处理完之后,才可以处理。在现实世界中的对应的案例就像:在处理实际的业务逻辑(C3)之前,需要校验数据(C1),以及将数据写入磁盘(C2)。
用原生的Disruptor语法来创建这些消费者的话代码如下:
1 | Executor executor = Executors.newCachedThreadPool(); |
在以上这段代码中,我们不得不创建那些个handler(就是那些个MyBatchHandler实例),外加消费者屏障,BatchConsumer实例,然后在他们各自的线程中处理这些消费者。DSL能帮我们完成很多创建工作,最终的结果如下:
1 | Executor executor = Executors.newCachedThreadPool(); |
我们甚至可以在一个更复杂的六边形模式中构建一个并行消费者链: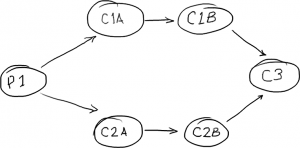
1 | dw.consumeWith(handler1a, handler2a); |
这个DSL(领域特定语言)刚刚诞生不久,欢迎任何反馈,也欢迎大家从github上fork并改进它。
Disruptor Wizard已死,Disruptor Wizard永存!
Disruptor Wizard(上一篇中提到的DSL组件)目前已经正式并入Disruptor的代码树当中。既然.net移植版包含了Wizard风格的语法很久了,并且看起来还挺受欢迎,所以为什么还要让人们非得搞两个jar而不是一个?
我跟随Disruptor在术语命名上的变动做出了相应的更新。以前的Customer(消费者),现在叫EventProcessor(事件处理器)和EventHandler(事件句柄)。这样的命名更好的说明了实际上的情况:消费者事实上可以向事件添加附加值。另外,ProducerBarrier(生产者屏障)被合并到Ring Buffer一起,并且Ring Buffer Entry(条目)被改名为Event(事件)。新的命名更贴切了,因为实际上围绕Disruptor的编程模型大部分时候都是基于事件的。
除了以下两点,Wizard API与以往并没有太大的不同:
1、consumeWith方法改名为handleEventsWith
2、getProducerBarrier方法被替换成了一个返回值为ring buffer的start方法。这就不会混淆地认为getProducerBarrier方法也被用作触发事件处理器线程的启动。
现在的方法命名清楚地表示了该方法的其它作用。
Disruptor 2.0更新摘要
马丁最近发布了Disruptor的2.0版本,从我们开始将其开源以来发生了很多变化,现在是个时候推出一个正式的里程碑了。马丁的博客上涵盖了这次更新的所有内容,这篇文章的目的是尝试把我以前的博文以新框架的架构转述给大家,因为将它们都重写一遍要耗费很多时间。现在我看到手工绘图的缺点了。
》》》旧版本
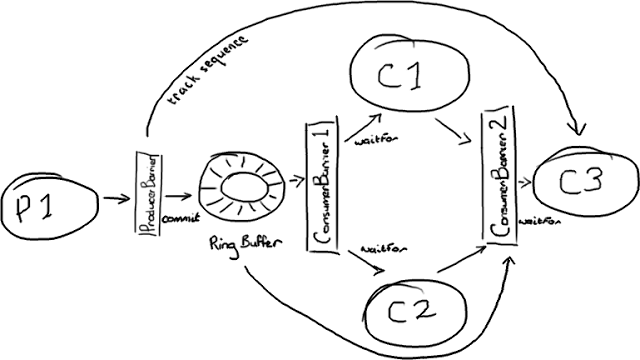
这是一个Disruptor的配置示例,具体上来说就是一个菱形的结构。如果你对此毫无感觉,可以回过头复习下disruptor的细节。
对于2.0版的主要变化有3点:
1、更贴切的命名;
2、把producer barrier(生产者屏障)整合进了ring buffer;
3、将Disruptor Wizard加入了主代码库。
》》》新版本
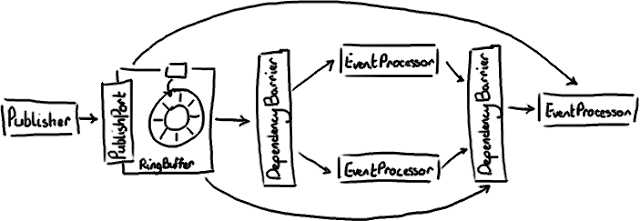
你可以看到基本原理还是类似的。新版本更加简单,因为ProducerBarrier本身不再作为一个单独的实体存在,它的替代者是PublishPort 接口,且RingBuffer自身就实现了这个接口。 类似地,DependencyBarrier替代ConsumerBarrier ,厘清了此对象的职责。另外,Publisher (Producer的替代者)和EventProcessor(替代了Consumer)也更能精确地体现出它们的行为。Consumer这个名字总是会带来一些混淆,因为因为其实消费者从来不从ring buffer消费任何东西。Consumer之前仅仅是用于队列实现的一个术语。
图上没有表现出来的变动是以前存在ring buffer里的东西叫entry(输入条目),而现在改名叫Event(事件)了,相应的就是EventProcessor。
整个命名上的大规模更改是为了让大家更清晰的明白Disruptor是如何工作的,以及该如何使用它。尽管我们把它用在事件处理上,但是当我们开源它的时候,还是希望它看起来可以更像一个通用的解决方案,所以命名惯例也倾向于表述这个事实。但是事件模型看起来确实更直观一些,于是我们就改成这个命名了。
另外由于Wizard的引入,事件发布者和事件处理者之间的接驳更加简单了。
现在如果你想建立一个菱形的Disruptor模式(例如FizzBuzz性能测试),一切变得优雅很多:
1 | DisruptorWizard dw = new DisruptorWizard( |
》》》其它变化:性能提升
马丁在他博客提到过,他已经成功的提高了2.0版的性能。 在2.0版中还有一个闪耀的新成员Sequence(序列),它被用来搞缓存行填充,并消除了对内存屏障的需要。现在缓存行填充的做法和以前略有不同,因为JAVA7新的优化特性,它成功的“优化”掉了我们原来的技术方案。
那么就到这里吧,这篇博文我就是想给大家一个简明的更新摘要,并且解释我以前画的图为什么可能不再正确了。
线程间共享数据无需竞争
LMAX Disruptor 是一个开源的并发框架,并获得2011 Duke’s程序框架创新奖。本文将用图表的方式为大家介绍Disruptor是什么,用来做什么,以及简单介绍背后的实现原理。
》》》Disruptor是什么?
Disruptor 是线程内通信框架,用于线程里共享数据。LMAX 创建Disruptor作为可靠消息架构的一部分并将它设计成一种在不同组件中共享数据非常快的方法。
基于Mechanical Sympathy(对于计算机底层硬件的理解),基本的计算机科学以及领域驱动设计,Disruptor已经发展成为一个帮助开发人员解决很多繁琐并发编程问题的框架。
很多架构都普遍使用一个队列共享线程间的数据(即传送消息)。图1 展示了一个在不同的阶段中通过使用队列来传送消息的例子(每个蓝色的圈代表一个线程)。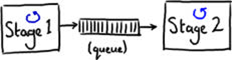
(图1)
这种架构允许生产者线程(图1中的stage1)在stage2很忙以至于无法立刻处理的时候能够继续执行下一步操作,从而提供了解决系统中数据拥堵的方法。这里队列可以看成是不同线程之间的缓冲。
在这种最简单的情况下,Disruptor 可以用来代替队列作为在不同的线程传递消息的工具(如图2所示)。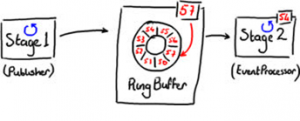
(图2)
这种数据结构叫着RingBuffer,是用数组实现的。Stage1线程把数据放进RingBuffer,而Stage2线程从RingBuffer中读取数据。
图2 中,可以看到RingBuffer中每格中都有序号,并且RingBuffer实时监测值最大(最新)的序号,该序号指向RingBuffer中最后一格。序号会伴随着越来越多的数据增加进RingBuffer中而增长。
Disruptor的关键在于是它的设计目标是在框架内没有竞争.这是通过遵守single-writer 原则,即只有一块数据可以写入一个数据块中,而达到的。遵循这样的规则使得Disruptor避免了代价高昂的CAS锁,这也使得Disruptor非常快。
Disruptor通过使用RingBuffer以及每个事件处理器(EventProcessor)监测各自的序号从而减少了竞争。这样,事件处理器只能更新自己所获得的序号。当介绍向RingBuffer读取和写入数据时会对这个概念作进一步阐述。
》》》发布到Disruptor
向RingBuffer写入数据需要通过两阶段提交(two-phase commit)。首先,Stage1线程即发布者必须确定RingBuffer中下一个可以插入的格,如图3所示。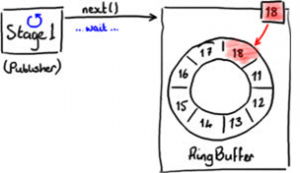
(图3)
RingBuffer持有最近写入格的序号(图3中的18格),从而确定下一个插入格的序号。
RingBuffer通过检查所有事件处理器正在从RingBuffer中读取的当前序号来判断下一个插入格是否空闲。
图4显示发现了下一个插入格。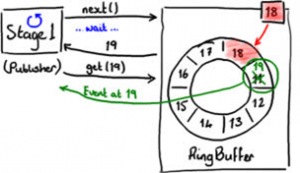
(图4)
当发布者得到下一个序号后,它可以获得该格中的对象,并可以对该对象进行任意操作。你可以把格想象成一个简单的可以写入任意值的容器。
同时,在发布者处理19格数据的时候,RingBuffer的序号依然是18,所以其他事件处理器将不会读到19格中的数据。
图5表示对象的改动保存进了RingBuffer。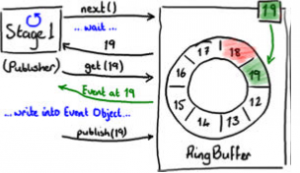
(图5)
最终,发布者最终将数据写入19格后,通知RingBuffer发布19格的数据。这时,RingBuffer更新序号并且所有从RingBuffer读数据的事件处理器都可以看到19格中的数据。
》》》RingBuffer中数据读取
Disruptor框架中包含了可以从RingBuffer中读取数据的BatchEventProcessor,下面将概述它如何工作并着重介绍它的设计。
当发布者向RingBuffer请求下一个空格以便写入时,一个实际上并不真的从RingBuffer消费事件的事件处理器,将监控它处理的最新的序号并请求它所需要的下一个序号。
图5显示事件处理器等待下一个序号。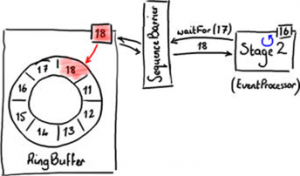
(图6)
事件处理器不是直接向RingBuffer请求序号,而是通过SequenceBarrier向RingBuffer请求序号。其中具体实现细节对我们的理解并不重要,但是下面可以看到这样做的目的很明显。
如图6中Stage2所示,事件处理器的最大序号是16.它向SequenceBarrier调用waitFor(17)以获得17格中的数据。因为没有数据写入RingBuffer,Stage2事件处理器挂起等待下一个序号。如果这样,没有什么可以处理。但是,如图6所示的情况,RingBuffer已经被填充到18格,所以waitFor函数将返回18并通知事件处理器,它可以读取包括直到18格在内的数据,如图7所示。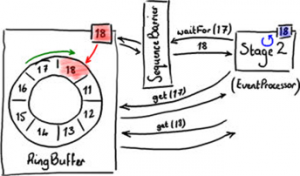
(图7)
这种方法提供了非常好的批处理功能,可以在BatchEventProcessor源码中看到。源码中直接向RingBuffer批量获取从下一个序号直到最大可以获得的序号中的数据。
你可以通过实现EventHandler使用批处理功能。在Disruptor性能测试中有关于如何使用批处理的例子,例如FizzBuzzEventHandler。
》》》是低延迟队列?
当然,Disruptor可以被当作低延迟队列来使用。我们对于Disruptor之前版本的测试数据显示了,运行在一个2.2 GHz的英特尔酷睿i7-2720QM处理器上使用Java 1.6.0_25 64位的Ubuntu的11.04三层管道模式架构中,Disruptor比ArrayBlockingQueue快了多少。表1显示了在管道中的每跳延迟。有关此测试的更多详细信息,请参阅Disruptor技术文件。
但是不要根据延迟数据得出Disruptor只是一种解决某种特定性能问题的方案,因为它不是。
》》》更酷的东西
一个有意思的事是Disruptor是如何支持系统组件之间的依赖关系,并在线程之间共享数据时不产生竞争。
Disruptor在设计上遵守single-writer 原则从而实现零竞争,即每个数据位只能被一个线程写入。但是,这不代表你不可以使用多个线程读数据,而这正是Disruptor所支持的。
Disruptor系统的最初设计是为了支持需要按照特定的顺序发生的阶段性类似流水线事件,这种需求在企业应用系统开发中并不少见。图8显示了标准的3级流水线。
(图8)
首先,每个事件都被写入硬盘(日志)作为日后恢复用。其次,这些事件被复制到备份服务器。只有在这两个阶段后,系统开始业务逻辑处理。
按顺序执行上次操作是一个合乎逻辑的方法,但是并不是最有效的方法。日志和复制操作可以同步执行,因为他们互相独立。但是业务逻辑必须在他们都执行完后才能执行。图9显示他们可以并行互不依赖。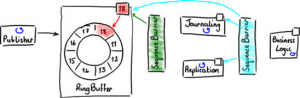
(图9)
如果使用Disruptor,前两个阶段(日志和复制)可以直接从RingBuffer中读取数据。正如图7种的简化图所示,他们都使用一个单一的Sequence Barrier从RingBuffer获取下一个可用的序号。他们记录他们使用过的序号,这样他们知道那些事件已经读过并可以使用BatchEventProcessor批量获取事件。
业务逻辑同样可以从同一个RingBuffer中读取事件,但是只限于前两个阶段已经处理过事件。这是通过加入第二个SequenceBarrier实现的,用它来监控处理日志的事件处理器和复制的事件处理器,当请求最大可读的序号时,它返回两个处理器中较小的序号。
当每个事件处理器都使用SequenceBarrier 来确定哪些事件可以安全的从RingBuffer中读出,那么就从中读出这些事件。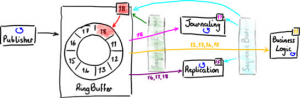
(图10)
有很多事件处理器都可以从RingBuffer中读取序号,包括日志事件处理器,复制事件处理器等,但是只有一个处理器可以增加序号。这保证了共享数据没有竞争。
》》》如果有多个发布者?
Disruptor也支持多个发布者向RingBuffer写入。当然,因为这样的话必然会发生两个不同的事件处理器写入同一格的情况,这样就会产生竞争。Disruptor提供ClaimStrategy的处理方式应对有多个发布者的情况。
》》》结论
在这里,我已经在总体上介绍了Disruptor框架是如何高性能在线程中共享数据,并简单阐述了它的原理。
有关更高级事件处理器以及向RingBuffer申请空间并等待下一个序号等很多策略在这里都没有涉及,Disruptor是开源的,到代码中去搜索吧。
Disruptor的应用
LMAX的架构
通过Axon和Disruptor处理1M tps
实操案例
首先你要引入 maven 依赖
1 | <!--2022-03-15 11:56:30 disruptor--> |
案例1
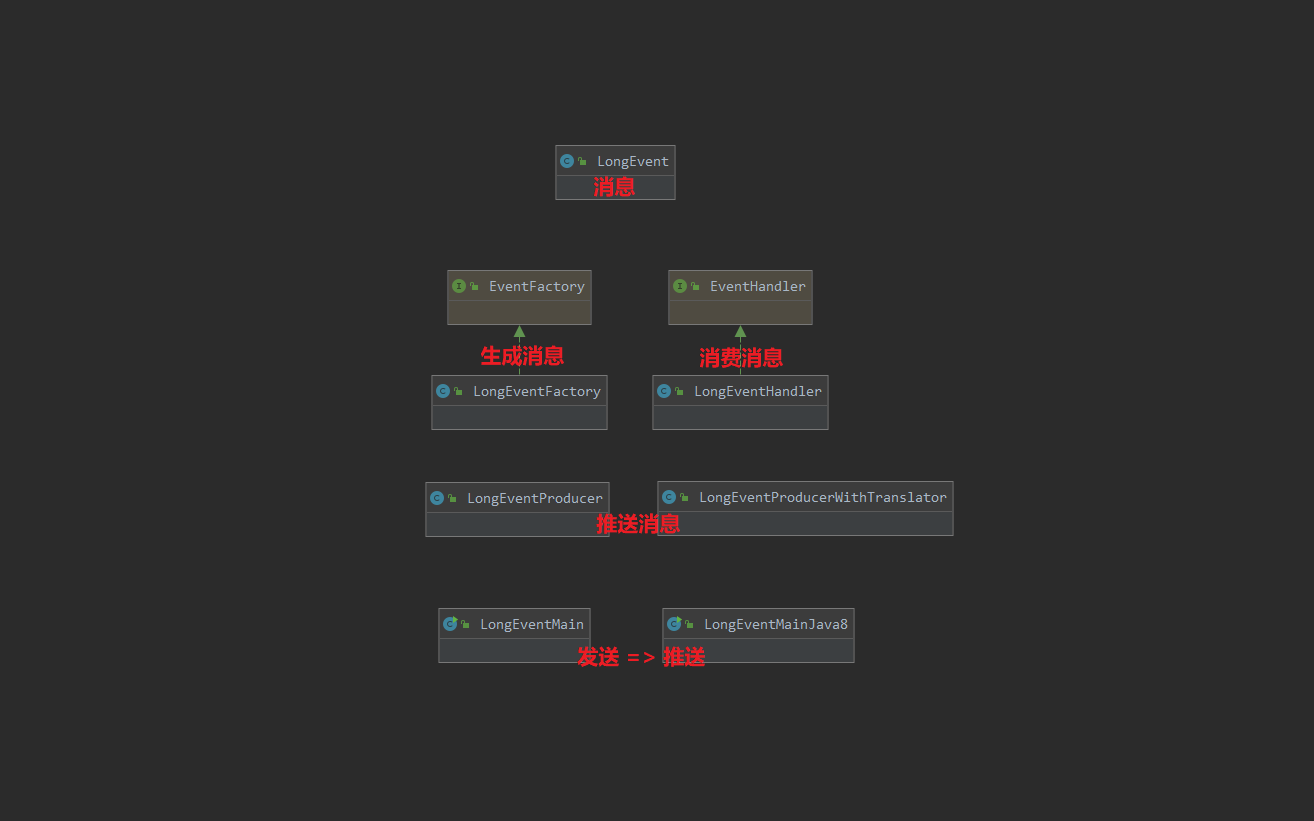
参考自:disruptor (史上最全)
Event
1 | /** |
EventFactory
1 | import com.lmax.disruptor.EventFactory; |
EventHandler
1 | import java.time.LocalDateTime; |
EventProducer
1 | import com.lmax.disruptor.RingBuffer; |
Main
1 |
|
EventProducerWithTranslator
1 | import com.lmax.disruptor.EventTranslatorOneArg; |
Main Java8
1 | import com.lmax.disruptor.RingBuffer; |
案例2
参考自:Disruptor 入门使用案例
队列中的消息对象:Message
1 | /** |
消费者 MessageHandler
1 | import java.time.LocalDateTime; |
生产者 MessageProducer
1 | import com.lmax.disruptor.EventTranslatorVararg; |
Main
1 |
|
案例3
Event类:汽车信息
1 | /** |
Handler类:DB
1 | import com.lmax.disruptor.EventHandler; |
Handler类:Kafka
1 | import com.lmax.disruptor.EventHandler; |
Handler类:SMS
1 | import com.lmax.disruptor.EventHandler; |
Producer类:生产Event
1 |
|
Main:测试
1 |
|