参考鸟哥Linux私房菜
学习的时候,要记得翻译:繁体->简体
命令未找到
ssh免密
1 | Windows ~/.ssh/id_rsa.pub 内容追加到 Linux ~/.ssh/authorized_keys |
exit:退出
1 | 1、命令行执行:退出 bash |
seq:数字序列
2020-11-27 16:57:30
打印一个数字序列(sequence)
1 | 用法:seq 尾数 |
locale:本地语言
2020-11-03 11:41:33
1 | [root@localhost ~]# locale |
永久生效(如果想设置英文:LANG=”en_US.UTF-8”):
1 | 1. 改文件 |
date:日期时间
1 | -----------------------date |
cal:日历
1 | 1. 查看当前 |
tab:补全
单击:自动补全
双击:列出候选补全
man:命令手册
manual
命令数字
1 | 代号 代表内容 |
man 页面操作
1 | 按键 进行工作 |
man:中文手册
》》》记得要先设置上面的locale:本地语言
1 | yum -y install man-pages-zh-CN |
who:谁在线上
1 | [root@localhost test]# who |
showdown:关机
reboot:重启
reboot -f
强制重启
chgrp:改变所属群组
1 | [root@study ~]# chgrp [-R] dirname/filename ... |
chown:改变档案拥有者
1 |
|
chmod:改变权限
》》》数字
1 | r:4 w:2 x:1 |
》》》符号
1 | user:u group:g others:o |
1 | 例题: |
cd:改变目录
Change Directory
1 | . 代表此层目录 |
pwd:显示目前所在的目录
Print Working Directory
1 | [root@study ~]# pwd [-P] |
mkdir:建立新目录
make directory
1 | [root@study ~]# mkdir [-mp] 目录名称 |
rmdir:删除『空』的目录
1 | [root@study ~]# rmdir [-p] 目录名称 |
$PATH:路径变量
1 | # 追加变量 |
ls:列出目录内容
1 | [root@study ~]# ls [-aAdfFhilnrRSt]档名或目录名称.. |
ll:查看
无论如何, ls最常被使用到的功能还是那个-l的选项。
为此,很多distribution在预设的情况中,已经将ll (L的小写)设定成为ls -l的意思了!
其实,那个功能是Bash shell的 alias 功能呢~也就是说,我们直接输入ll就等于是输入ls -l是一样的
1 | [root@localhost /]# alias |
cp:拷贝
1 |
|
rm:移除档案或目录
remove
1 | [root@study ~]# rm [-fir]档案或目录 |
mv:移动档案与目录,或更名
move
1 |
|
basename dirname:取得路径的档案名称与目录名称
那么你怎么知道那个是档名?那个是目录名?嘿嘿!就是利用斜线(/) 来分辨啊!
所以,这部分的指令可以用在 shell scripts 里头喔!
1 | [root@localhost test]# basename /app/test/a |
cat:显示
concatenate
1 |
|
< <<
2022-06-13 17:06:42 补
之前我记得我记录过,不过找不到在哪里了,再次记录这里以便于以后查找。
Linux的”<”,”<<”的详细用法和总结
先说明,以下的file和file.txt作用一样,并且这里不做> ,>>等符号的说明。
为了区分目录,下面使用了索引
1 | << 的使用 |
tac:反向显示
(tac刚好是将cat反写过来,所以他的功能就跟cat相反啦)
1 | [root@localhost test]# tac a |
nl:添加行号列印
1 | [root@study ~]# nl [-bnw]档案 |
more:只能往下翻
1 | 空白键(space): 代表向下翻一页; |
less:上下翻动
1 | 空白键 :向下翻动一页; |
head:取出前面几行
1 |
|
tail:取出后面几行
1 |
|
touch:修改档案时间或建置新档
1 | [root@study ~]# touch [-acdmt]档案 |
1、touch 文件存在,只修改 mtime,atime,ctime 为当前时间。文件不存在,会新建,mtime,atime,ctime 为当前时间
2、即使使用 cp -a src dest,只会复制 mtime,atime,并不会复制 ctime,ctime 是命令执行的当前时间
3、注意看看下面,日期在atime 与mtime 都改变了,但是ctime 则也是记录目前的时间!
1 | [dmtsai@study tmp]# touch -t 201406150202 bashrc |
无论如何, touch 这个指令最常被使用的情况是:
、建立一个空的档案;
、将某个档案日期修订为目前(mtime 与atime)
umask:档案预设权限
1 | 1. 第一个 0 表示特殊权限,后面 022 表示ugo所去除的权限:u什么都不去除,g、o去除写权限 |
chattr:设定档案隐藏属性
1 |
|
lsattr:显示档案隐藏属性
1 |
|
1、src 设置 +i 之后不能建立硬链接,但可以建立软链接,
2、如果 src 与 dest 是硬链接,对其中一个 +i,两个都会有 +i 属性
3、软链接不能 lsattr 查看,因为它仅仅是一个链接,而不是文件
4、+i 之后的文件,不可以修改,移动,删除,但能读取,执行
5、+i 施加于文件夹,这个文件夹则不能添加东西
6、+a 之后的文件,只能追加,不能修改
SUID/SGID/SBIT 前引
不是应该只有rwx吗?还有其他的特殊权限( s跟t )啊?
2020-11-04 16:57:16 先提一嘴,学到后面再进行更新。
1 | [root@localhost test]# ll -d /usr/bin/passwd /etc/shadow /tmp/ |
Set UID:4
当s这个标志出现在档案拥有者的x权限上时,
例如刚刚提到的/usr/bin/passwd这个档案的权限状态:『-rw s r-xr-x』,此时就被称为Set UID,简称为SUID的特殊权限。
那么SUID的权限对于一个档案的特殊功能是什么呢?
基本上SUID有这样的限制与功能:
、SUID 权限仅对二进位程式(binary program)有效;
、执行者对于该程式需要具有x 的可执行权限;
、本权限仅在执行该程式的过程中有效(run-time);
、执行者将具有该程式拥有者(owner) 的权限。
讲这么硬的东西你可能对于SUID还是没有概念,没关系,我们举个例子来说明好了。
我们的Linux系统中,所有帐号的密码都记录在/etc/shadow这个档案里面,
这个档案的权限为:『———- 1 root root』,意思是这个档案仅有root可读且仅有root可以强制写入而已。
既然这个档案仅有root可以修改,那么鸟哥的dmtsai这个一般帐号使用者能否自行修改自己的密码呢?
你可以使用你自己的帐号输入『passwd』这个指令来看看,嘿嘿!一般使用者当然可以修改自己的密码了!
唔!有没有冲突啊!明明/etc/shadow 就不能让dmtsai 这个一般帐户去存取的,为什么dmtsai 还能够修改这个档案内的密码呢?
这就是SUID 的功能啦!藉由上述的功能说明,我们可以知道
1、dmtsai 对于/usr/bin/passwd 这个程式来说是具有x 权限的,表示dmtsai 能执行passwd;
2、passwd 的拥有者是root 这个帐号;
3、dmtsai 执行passwd 的过程中,会『暂时』获得root 的权限;
4、/etc/shadow 就可以被dmtsai 所执行的passwd 所修改。
但如果dmtsai 使用cat 去读取/etc/shadow 时,他能够读取吗?
因为cat 不具有SUID 的权限,所以dmtsai 执行『cat /etc/shadow』 时,是不能读取/etc/shadow 的。
我们用一张示意图来说明如下: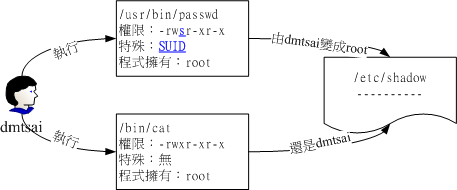
另外,SUID仅可用在binary program上,不能够用在shell script上面!这是因为shell script只是将很多的binary执行档叫进来执行而已!
所以SUID的权限部分,还是得要看shell script呼叫进来的程式的设定,而不是shell script本身。
当然,SUID对于目录也是无效的~这点要特别留意。
(陶攀峰总结:运行时短暂获取拥有者的权限)
Set GID:2
当s 标志在档案拥有者的x 项目为SUID,那s 在群组的x 时则称为Set GID, SGID 啰!是这样没错!^_^。
举例来说,你可以用底下的指令来观察到具有SGID 权限的档案喔:
1 | [root@localhost test]# ll /usr/bin/locate |
:::如果没有 locate 命令,可使用yum -y install mlocate安装
与SUID 不同的是,SGID 可以针对档案或目录来设定!
如果是对档案来说, SGID 有如下的功能:
、SGID 对二进位程式有用;
、程式执行者对于该程式来说,需具备x 的权限;
、执行者在执行的过程中将会获得该程式群组的支援!
举例来说,上面的/usr/bin/locate 这个程式可以去搜寻/var/lib/mlocate/mlocate.db 这个档案的内容(详细说明会在下节讲述), mlocate.db 的权限如下:
1 | [root@localhost test]# ll /usr/bin/locate /var/lib/mlocate/mlocate.db |
:::如果出现:ls: 无法访问/var/lib/mlocate/mlocate.db: 没有那个文件或目录,可使用updatedb
与SUID 非常的类似,若我使用dmtsai 这个帐号去执行locate 时,那dmtsai 将会取得slocate 群组的支援, 因此就能够去读取mlocate.db 啦!非常有趣吧!
除了binary program 之外,事实上SGID 也能够用在目录上,这也是非常常见的一种用途!当一个目录设定了SGID 的权限后,他将具有如下的功能:
、使用者若对于此目录具有r 与x 的权限时,该使用者能够进入此目录;
、使用者在此目录下的有效群组(effective group)将会变成该目录的群组;
、用途:若使用者在此目录下具有w 的权限(可以新建档案),则使用者所建立的新档案,该新档案的群组与此目录的群组相同。
SGID对于专案开发来说是非常重要的!因为这涉及群组权限的问题,您可以参考一下本章后续情境模拟的案例,应该就能够对于SGID有一些了解的!^_^
(陶攀峰总结:获取群组权限,可读取具有群组的档案)
Sticky Bit:1
这个Sticky Bit, SBIT 目前只针对目录有效,对于档案已经没有效果了。SBIT 对于目录的作用是:
、当使用者对于此目录具有w, x 权限,亦即具有写入的权限时;
、当使用者在该目录下建立档案或目录时,仅有自己与root 才有权力删除该档案
换句话说:当甲这个使用者于A目录是具有群组或其他人的身份,并且拥有该目录w的权限,这表示『甲使用者对该目录内任何人建立的目录或档案均可进行”删除/更名/搬移”等动作。』
不过,如果将A目录加上了SBIT的权限项目时,则甲只能够针对自己建立的档案或目录进行删除/更名/移动等动作,而无法删除他人的档案。
举例来说,我们的/tmp 本身的权限是『drwxrwxrwt』, 在这样的权限内容下,任何人都可以在/tmp 内新增、修改档案,但仅有该档案/目录建立者与root 能够删除自己的目录或档案。这个特性也是挺重要的啊!
你可以这样做个简单的测试:
1、以root 登入系统,并且进入/tmp 当中;
2、touch test,并且更改test 权限成为777 ;
3、以一般使用者登入,并进入/tmp;
4、尝试删除test 这个档案!
由于SUID/SGID/SBIT牵涉到程序的概念,因此再次强调,这部份的资料在您读完第十六章关于程序方面的知识后,要再次的回来瞧瞧喔!
目前,你先有个简单的基础概念就好了!文末的参考资料也建议阅读一番喔!
(陶攀峰总结:这个目录里的东西只要自己和root可操作,其他人都不可以操作)
SUID/SGID/SBIT 权限设定
前面介绍过SUID与SGID的功能,那么如何设定档案使成为具有SUID与SGID的权限呢?这就需要第五章的数字更改权限的方法了!
现在你应该已经知道数字型态更改权限的方式为『三个数字』的组合,那么如果在这三个数字之前再加上一个数字的话,最前面的那个数字就代表这几个权限了!
1 | 4 为SUID |
1 | 1. 进入目录,建立一个测试用空档 |
最后一个例子就要特别小心啦!怎么会出现大写的S与T呢?不都是小写的吗?因为s与t都是取代x这个权限的,但是你有没有发现阿,我们是下达7666喔!
也就是说, user, group以及others都没有x这个可执行的标志(因为666嘛),所以,这个S, T代表的就是『空的』啦!
怎么说?SUID是表示『该档案在执行的时候,具有档案拥有者的权限』,但是档案拥有者都无法执行了,哪里来的权限给其他人使用?当然就是空的啦!^_^
而除了数字法之外,妳也可以透过符号法来处理喔!其中SUID 为u+s ,而SGID 为g+s ,SBIT 则是o+t 啰!来看看如下的范例:
1 | 1. 设定权限成为-rws--x--x的模样 |
file:查看文件类型
1 | 1. empty 档 |
透过这个指令,我们可以简单的先判断这个档案的格式为何喔!
包括未来你也可以用来判断使用tar 包裹时,该tarball 档案是使用哪一种压缩功能哩!
which:查看命令别名,所在位置
2020-11-05 10:25:20
寻找『执行档』
1 | [root@study ~]# which [-a] command |
这个指令是根据『PATH』这个环境变数所规范的路径,去搜寻『执行档』的档名~所以,重点是找出『执行档』而已!
且which后面接的是『完整档名』喔!若加上-a选项,则可以列出所有的可以找到的同名执行档,而非仅显示第一个而已!
df:查看卷
列出档案系统的整体磁碟使用量;
1 | [root@study ~]# df [-ahikHTm] [目录或档名] |
另外需要注意的是,如果使用-a 这个参数时,系统会出现/proc 这个挂载点,但是里面的东西都是 0 ,不要紧张!/proc 的东西都是Linux 系统所需要载入的系统资料,而且是挂载在『记忆体当中』的, 所以当然没有占任何的磁碟空间啰!
至于那个/dev/shm/目录,其实是利用记忆体虚拟出来的磁碟空间,通常是总实体记忆体的一半! 由于是透过记忆体模拟出来的磁碟,因此你在这个目录底下建立任何资料档案时,存取速度是非常快速的!(在记忆体内工作)不过,也由于他是记忆体模拟出来的,因此这个档案系统的大小在每部主机上都不一样,而且建立的东西在下次开机时就消失了!因为是在记忆体中嘛!
du:查看目录
评估档案系统的磁碟使用量(常用在推估目录所占容量)
注意:这里并不是真实的使用大小,而是占用的大小。因为单位至少 4KB,所以都是 4KB 的倍数
1 | [root@study ~]# du [-ahskm]档案或目录名称 |
free:显示内存
显示系统中空闲内存和使用内存的数量
1 | -------------------------free --help |
ln:软硬链接
1 | [root@study ~]# ln [-sf]来源档目标档 |
删除软链接
2021-01-14 19:11:48
这个有必要拿出来说,有可能你会造成大错。
1 | lrwxrwxrwx 1 root root 28 Jan 14 19:05 script -> /data/httpd/order-bff/script |
》》同理,你要想查看软链接的详情也不能加上 “/” 斜杠
1 | # 加了 / |
软硬链接分析
2020-11-09 14:33:44
inode 只是记录的一个编号,cp -l a aa,或 ln a aa 建立的都只是一个档名而已,而不是建立档案。
删除其中一个不会影响另外一个,是因为删除的是一个档名而已。
硬链接不能:目录
cp -s a aa,或 ln -s a aa 不同于 hard link,因为 aa 是指向 a 的一个快捷方式而已。
删除了 a 就相当于删除了档名和档案,所以 aa 就找不到 a 档案了。
软链接不能:删除文件,再对 dest 进行 cat
mount:挂载
2020-11-11 09:43:52
mount –bind m1 m2
执行了这个之后,会把 m2 的 inode 指向 m1,此时 两个目录都指向 m1 的 inode。
所以,进入 m2 就相当于进入 m1,其中一个删除或更新,另外一个就会改变,因为操作的是同一个 inode。
1 | [root@localhost ~]# mkdir -p /app/test/ |
1 | mount [-hV] |
磁碟空间之浪费问题
我们在前面的EXT2 data block介绍中谈到了一个block只能放置一个档案,因此太多小档案将会浪费非常多的磁碟容量。但你有没有注意到,整个档案系统中包括superblock, inode table与其他中介资料等其实都会浪费磁碟容量喔!所以当我们在/dev/vda4, /dev/vda5建立起xfs/ext4档案系统时,一挂载就立刻有很多容量被用掉了!
另外,不知道你有没有发现到,当你使用ls -l 去查询某个目录下的资料时,第一行都会出现一个『total』的字样!那是啥东西?其实那就是该目录下的所有资料所耗用的实际block 数量* block 大小的值。我们可以透过ll -s 来观察看看上述的意义:
1 | [root@study ~]# ll -sh |
从上面的特殊字体部分,那就是每个档案所使用掉block 的容量!
举例来说,那个crontab 虽然仅有451bytes , 不过他却占用了整个block (每个block 为4K),所以将所有的档案的所有的block 加总就得到12Kbytes 那个数值了。
如果计算每个档案实际容量的加总结果,其实只有不到5K 而已~所以啰,这样就耗费掉好多容量了!未来大家在讨论小磁碟、 大磁碟,档案容量的损耗时,要回想到这个区块喔!^_^
压缩后缀名
1 | *.Z compress 程式压缩的档案; |
这些都是针对单一档案的压缩/解压,压缩一大推,需要用到 tar 命令。
gzip 可解压 compress,zip,gzip 压缩的档案
.gz 文件可被 Windows 的 WinRAR/7zip/Bandizip 解压
gzip,gunzip,zcat,zmore,zless,zgrep
1 | [dmtsai@study ~]$ gzip [-cdtv#] 档名 |
bzip2,bunzip2,bzcat,bzmore,bzless,bzgrep
1 | [dmtsai@study ~]$ bzip2 [-cdkzv#] 档名 |
xz,unxz,xzcat,xzmore,xzless,xzgrep
1 | [dmtsai@study ~]$ xz [-dtlkc#] 档名 |
zip,unzip
1 | # 压缩文件 |
tar:打包
1 |
|
1 | ### 1. 压缩 ### |
tarfile 是 .tar 文件,仅是打包文件
tarball 是 .tar.gz,或.tar.xz 等,它们是 tar 打包之后再 gzip,或xz压缩的文件
tar 与 wget
2020-12-25 16:21:10
参考关于tar解压重命名的问题
1 | 1、下载压缩包,并改名 mysql.tar.gz (此时直接解压后目录是:mysql-5.6.15-linux-glibc2.5-i686) |
wget:下载器
2020-12-25 16:21:07
1、默认下载,会在当前路径保存index.html文件
1 | wget www.baidu.com/index.html |
2、下载并指定名称,会在当前路径保存diy.html文件
1 | wget -O diy.html www.baidu.com/index.html |
3、下载放入指定文件夹,没有则会递归创建
1 | wget -P /a/b/c www.baidu.com/index.html |
4、下载放入指定文件夹并改名,这个是不可以的(-P 会失效,会在当前路径保存diy.html文件)
1 | wget -O diy.html -P /aaa www.baidu.com/index.html |
vim 快捷键
1 | h 或向左方向键(←) 游标向左移动一个字元 |
vim 的暂存档、救援回复与开启时的警告讯息
正在 vim 页面,退出 bash 时,当前编辑的目录会出现 .xxx.swp
可以查看 ls -la . 查看文件,通常删除文件后,再进行编辑。
区块选择快捷键(Visual Block)
1 | v 字元选择,会将游标经过的地方反白选择! |
多档案编辑
进入多档案:vim file1 file2
1 | :n 编辑下一个档案 |
多视窗功能
1 | :sp [filename] 开启一个新视窗,如果有加filename, 表示在新视窗开启一个新档案,否则表示两个视窗为同一个档案内容(同步显示)。 |
vim 的补全功能
1 | [ctrl]+x -> [ctrl]+n 透过目前正在编辑的这个『档案的内容文字』作为关键字,予以补齐 |
~/.vimrc, ~/.viminfo:vim 环境设定与记录
我们进入文件,输入搜索命令 :/xxx,此时 xxx 都进行高亮。
即使我们退出,或进入了其他文件后,再次进入该文件,依然有搜索的高亮提示。
这就是因为文件 ~/.viminfo 文件的作用。它记录了我们的 vim 操作。
关于 ~/.vimrc,是我们可以进行自定义的 vim 设置。
1 | :set nu |
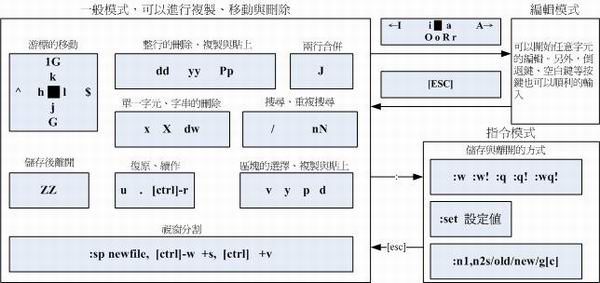
vim 指令总结图
dos2unix:DOS 与Linux 的断行字元
因为Windows换行符 CRLF 是M$结尾,而Linux是LF $结尾
可以使用cat -A 脚本文件来查看Shell隐藏内容
1 | [dmtsai@study ~]$ dos2unix [-kn] file [newfile] |
iconv:语系编码转换
1 |
|
bash,shell 区别?
首先,问这个问题,就表示你不是很理解。你 -> Shell,或 APP -> Kernel -> 硬件
“shell”就是一个能访问内核的壳子。这个壳子也是一个程序(APP),这个程序的名称叫“bash”。
1 |
|
bash 的功能
1 |
|
type:查询指令是否为Bash shell 的内建命令
1 |
|
bash 快捷键
1 | \ 表示跳脱 |
set,env,export,unset:变量操作
$$:当前 bash PID
$?:上一条命令执行结果。0 表示正常执行,非 0 表示错误代码
$!:后台运行的最后一个进程的PID进程号(Linux要运行很多进程,一个进程对应一个PID号)
1 | [root@localhost test]# echo $$ |
PS1:表示 bash 的左侧提示 -> [root@localhost test]#
PATH:环境变量,冒号:分割。执行命令时会按顺序搜索,搜索到就不往下搜索了,搜索不到就报 -bash:xxx command not found
$变量名 或 ${变量名}:表示变量的使用。例如(变量追加):PATH=”$PATH”:/app/test/diy 或 PATH=${PATH}:/app/test/diy
$(命令) 或 命令:表示命令的引用。例如:cd /lib/modules/$(uname -r)/kernel ===> 先执行 uname,再执行 cd
‘:一切符号失去含义,当做字符串。例如:a=阿 ; b=’$a’B ; echo $b 输出 $aB
“:一切符号可以当做特殊含义使用。例如:a=阿 ; b=”$a”B ; echo $b 输出 阿B
变量名=变量内容:声明变量
export 变量名:声明环境变量
set:当前 bash 变量(子 bash 不可用)
env:环境变量(子 bash 可用,不包含 declare 声明类型)
export:环境变量(子 bash 可用,包含 declare 声明类型)
unset 变量名:取消变量(可取消环境变量,或自变量)
数值运算
1 | #===> 方式1:用declare -i声明数值类型 |
运算符
1 | 优先级值越大越优先 |
PS1:bash 前缀提示
1 | [root@localhost test]# set | grep PS1 |
read:读取屏幕输入
1 | [root@localhost test]# chmod 777 read.sh |
declare:声明变量类型
1 | 1. 默认字符串 |
array:数组变量
1 | 声明:变量名[index]=content |
# ## % %% / //:变数内容的删除与取代
1 | ${变数#关键字} 若变数内容从头开始的资料符合『关键字』,则将符合的最短资料删除 |
1 |
|
- + = ? :变数的测试与内容替换
1 | 变数设定方式 str 没有设定 str 为空字串 str 已设定非为空字串 |
alias:别名
1 | alias 别名='原命令' |
history:历史命令
1 | [dmtsai@study ~]$ history [n] |
、当我们以bash 登入Linux 主机之后,系统会主动的由家目录的/.bash_history 读取以前曾经下过的指令,那么/.bash_history 会记录几笔资料呢?这就与你bash 的 HISTFILESIZE 这个变数设定值有关了!
、假设我这次登入主机后,共下达过100次指令,『等我登出时,系统就会将1011100这总共1000笔历史命令更新到/.bash_history当中。』也就是说,历史命令在我登出时,会将最近的HISTFILESIZE笔记录到我的纪录档当中啦!
、当然,也可以用history -w 强制立刻写入的!那为何用『更新』两个字呢?因为~/.bash_history 记录的笔数永远都是HISTFILESIZE 那么多,旧的讯息会被主动的拿掉!仅保留最新的!
1 | [dmtsai@study ~]$ !number |
我们知道,只有退出 bash 界面,才会把命令写入 ~/.bash_history
一般我们会开启多个 bash 页面,关闭时,会按照顺序一个一个写入
路径与指令搜寻顺序
如果一个指令(例如ls)被下达时,到底是哪一个ls被拿来运作?很有趣吧!
基本上,指令运作的顺序可以这样看:
1 | 1、以相对/绝对路径执行指令,例如『 /bin/ls 』或『 ./ls 』; |
举例来说,你可以下达/bin/ls 及单纯的ls 看看,会发现使用ls 有颜色但是/bin/ls 则没有颜色。
因为/bin/ls 是直接取用该指令来下达,而ls 会因为『 alias ls=’ls –color=auto’ 』这个命令别名而先使用!
如果想要了解指令搜寻的顺序,其实透过type -a ls 也可以查询的到啦!
1 |
|
/etc/issue, /etc/motd: bash 的进站与欢迎讯息
1 | /etc/issue 虚拟机开机提示 |
login shell
bash 在读完了整体环境设定的/etc/profile 并借此呼叫其他设定档后,接下来则是会读取使用者的个人设定档。
在login shell 的bash 环境中,所读取的个人偏好设定档其实主要有三个,依序分别是:
1 | /etc/profile 系统整体的设定,不要动 |
source :读入环境设定档的指令
1 | 立即生效:source 或 小数点 . |
non-login shell
1 | ~/.bashrc 根据 UID 规定了 umask,PS1,并读取 /etc/profile.d/*.sh 的设定 |
* ?等:万用字元与特殊符号
1 | * 代表『 0 个到无穷多个』任意字元 |
< << > >> 2> 2>>:箭头资料流重导向
1 | 标准输入(stdin) :代码为0 ,使用< 或<< ; |
1 | cat 配合 资料重导向,eof 使用 |
为什么需要重导向?
、萤幕输出的资讯很重要,而且我们需要将他存下来的时候;
、背景执行中的程式,不希望他干扰萤幕正常的输出结果时;
、一些系统的例行命令(例如写在/etc/crontab 中的档案) 的执行结果,希望他可以存下来时;
、一些执行命令的可能已知错误讯息时,想以『 2> /dev/null 』将他丢掉时;
、错误讯息与正确讯息需要分别输出时。
》》》关于“<< eof”,再做解释
1 | 你可能不太理解。<< 是输入重定向。 |
/dev/null:文件黑洞
不管错误,正确。写入的都不能读取。
1 | [root@localhost test]# ll /dev/null |
; , &&, ||:命令执行的判断依据
1 | 命令1 ; 命令2 顺序执行 |
| 管线命令(pipe)
1 | STDOUT->STDIN STDOUT->STDIN |
注意点:
、管线命令仅会处理standard output,对于standard error output 会予以忽略
、管线命令必须要能够接受来自前一个指令的资料成为standard input 继续处理才行。
cut:列分割
按照列进行分割
1 | [dmtsai@study ~]$ cut -d '分隔字元' -f fields <==用于有特定分隔字元 |
grep:行搜索
1 |
|
grep “表达式” 文件 参数
表达式:
1、or “陶攀峰|陶凯文” 无序
2、and “陶攀峰.*陶凯文” 注意顺序
文件:
查找多个文件,可以使用* 星号
例如(在当月的日志中找):grep 陶攀峰 /data/logs/2021-03*.log
1 |
|
grep:(进阶)显示前后n行
1 |
|
sort:排序
默认 String 字符串 排序
1 |
|
uniq:去重
使用之前要排序
1 |
|
有时候,你想按照月份,来统计登录次数,uniq 这个命令就比较实用了。
wc:统计行/词/字节
wordcount
1 | [root@localhost test]# wc /etc/passwd ===> 统计多少行,多少单词,多少字节 |
tee:双向重导向
1 | STDIN -> tee -> Screen |
》》》“tee” 代替 “cat >”
1 | ----------------------------cat > a << "eof" |
tr:删除,替换
1 |
|
col:tab转空格
1 |
|
join:多行合并
两个档案当中,有”相同资料” 的那一行,才将他加在一起
1 | [dmtsai@study ~]$ join [-ti12] file1 file2 |
paste:多行合并
这个 paste 就要比 join 简单多了!
paste 就直接『将两行贴在一起,且中间以 [tab] 键隔开』而已!
1 |
|
expand:tab转空格
1 |
|
也可以参考一下unexpand 这个将空白转成[tab] 的指令功能啊!^_^
split:分割文件
如果你有档案太大,导致一些携带式装置无法复制的问题,嘿嘿!找split 就对了!
他可以帮你将一个大档案,依据档案大小或行数来分割,就可以将大档案分割成为小档案了!
1 |
|
xargs:参数代换
1 |
|
- 减号的用途解释
管线命令在bash 的连续的处理程序中是相当重要的!
另外,在log file 的分析当中也是相当重要的一环, 所以请特别留意!
另外,在管线命令当中,常常会使用到前一个指令的stdout 作为这次的stdin ,
某些指令需要用到档案名称(例如tar) 来进行处理时,该stdin 与stdout 可以利用减号”-“ 来替代, 举例来说:
1 | [root@study ~]# mkdir /tmp/homeback |
上面这个例子是说:『我将/home 里面的档案给他打包,但打包的资料不是纪录到档案,而是传送到stdout;
经过管线后,将tar -cvf - /home 传送给后面的tar - xvf - 』。
后面的这个- 则是取用前一个指令的stdout, 因此,我们就不需要使用filename 了!
这是很常见的例子喔!注意注意!
正则表达式:扩展
vi, grep, awk ,sed 正则
cp, ls 通配符
1 | 特殊符号 代表意义 |
sed:替换、删除、新增、截取
1 |
|
1 | # 1. a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~ |
printf:格式化列印
1 | [dmtsai@study ~]$ printf '列印格式'实际内容 |
小案例
1 | ------------------------cat printf.txt |
awk:好用的资料处理工具
用于操作 列。分割成一列一列的。
cut 命令只能按照符号分割列,但不能按照空格分割。
但 awk 是可以按照空格分割列的。所以,可以说 awk 包含 cut 功能。
1 | # 常用补充 |
1 | # awk '条件1{动作1} 条件2{动作2} ...' 文件名 |
》》》简单使用,了解“动作”的使用。 print printf $0 $1 $2《《《
1 |
|
上面我们知道了列,如果想知道行号,和每一行的列数怎么办?
1 | NF (F field)每一行($0) 拥有的栏位总数 |
既然需要“条件”,就要有逻辑运算~
1 | > 大于 |
diff:找不同
1 |
|
cmp:提示两文件第一个不同之处
相对于diff 的广泛用途, cmp 似乎就用的没有这么多了~
可以比较二进制。
1 |
|
patch
省略学习
pr:档案分页显示
感觉没卵用啊
1 | [root@localhost ~]# pr /etc/man_db.conf |
案例1.对谈式脚本:变数内容由使用者决定
1 | [root@localhost sh]# cat showname.sh |
案例2.随日期变化:利用date 进行档案的建立
1 | [root@localhost sh]# cat create-3-filename.sh |
案例3.数值运算:简单的加减乘除
1 | [root@localhost sh]# cat multiplying.sh |
案例4.数值运算:透过bc 计算π
1 | [root@localhost sh]# cat cal-pi.sh |
script 的执行方式差异(source, sh script, ./script)
1、利用直接执行的方式来执行script
1 |
|
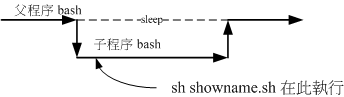
2、利用source 来执行脚本:在父程序中执行
1 |
|
竟然生效了!没错啊!因为source 对script 的执行方式可以使用底下的图示来说明!
showname.sh 会在父程序中执行的,因此各项动作都会在原本的bash 内生效!
这也是为啥你不登出系统而要让某些写入~/.bashrc 的设定生效时,需要使用『 source ~/.bashrc 』而不能使用『 bash ~/.bashrc 』是一样的啊!
总结:source:当前bash执行。其他模式:开一个子shell执行。
test:测试功能
当我要检测系统上面某些档案或者是相关的属性时,利用test 这个指令来工作真是好用得不得了
test -e /root/anaconda-ks.cfg
===> 为了看得清楚,我使用“空格”代替的一个空格
===> 下面的这些符号:”-e”、”-f”、”==”、”!”、… 等等,这些符号使用时,两边要有空格
===> 否则会提示:-bash: test: : 期待一元表达式这样等字样test空格-e空格/root/anaconda-ks.cfg
===> 数据不会显示,可以使用 $? 或 && || 来显示test -e /sdfs ; echo $?test -e /sdfs && echo "exist" || echo "not exist"
1 |
|
》》》 小练习
1、控制台输入一个档案名
2、判断档案是否存在,不存在要给予提示
3、若是文件、目录,也要给予提示
4、提示执行者身份具有它的rwx哪些权限
1 | [root@localhost sh]# cat file_perm.sh |
[]:判断符号
这个功能和上面的 test 一致。为了简化 test 命令
1 | test -e file_perm.sh && echo true || echo false #===> 正确,"-e"左右两边有空格 |
》》》变量的使用
1 | -----------------------name="tao panfeng" |
》》》注意事项,总结:
1、在中括号[] 内的每个元素都需要有空白键来分隔;
2、在中括号内的变量,最好都以双引号括号起来;
3、在中括号内的字符串,最好都以单或双引号括号起来。
》》》小练习
1、执行一个程序,让你输入 Y/N
2、输入 Y 或 y 时,提示“继续”
3、输入 N 或 n 时,提示“中断”
4、输入不是 Y/y/N/n 时,提示“不知道你输入的是什么”
1 | -----------------------cat ans-yn.sh |
$@, $*, $#, $0, $1…:Shell script 的预设变数
命令可以带有选项和参数,例如 ls -la 可以察看包含隐藏档的所有属性与权限。
那么 shell script 能不能在脚本档名后面带有参数呢?
举例来说,如果你想要重新启动系统的网络,可以这样做:
1 | -----------------------file /etc/init.d/network |
由上,可知“/etc/init.d/network”是一个 shell script。
1 | /etc/init.d/network restart #===> 重启网络 |
这里的 restart,start,stop。就是这个 shell script 的参数了。
这个脚本可以根据参数的不同,而执行对应的操作。
我们在之前学习了“read”指令,它可以根据输入的内容,来接收参数,但是它需要用户输入。
如果不想输入的话,就要透过命令后面接参数的方式了,这样比较方便啦。
1 | -----------------------cat params.sh |
》》》小练习
1、程序名称是什么?
2、共有几个参数?
3、若参数小于 2,则提示参数数量太少
4、全部参数内容是什么?
5、第一个参数是什么?
6、第二个参数是什么?
1 | -----------------------cat how_paras.sh |
shift:造成参数变数号码偏移
造成参数往后偏移一位
1 | -----------------------cat how_paras.sh |
经过以上,三次添加 shift,想必了解的差不多了吧。
下面我们来看“条件判断”。
if语句
语法参考:if语句
1 | #===> 单分支。写法 1(常用) |
注意:
1、if开头,fi结尾。(将if反过来写,就成为fi啦!结束if之意!)
2、是 elif,不是 else if
3、if、elif都是判断式,后面都带有then来处理。但else 是没有成立的结果了, 所以else 后面没有then!
》》》多重写法
1 | && 代表 and |
》》》小练习
1、执行一个程序,让你输入 Y/N
2、输入 Y 或 y 时,提示“继续”
3、输入 N 或 n 时,提示“中断”
4、输入不是 Y/y/N/n 时,提示“不知道你输入的是什么”
1 | -----------------------cp ans-yn.sh ans-yn-2-if.sh #===> 拷贝一份更快 |
》》》小练习
1、输入一个日期
2、计算现在日期对比输入日期
3、由两个日期的比较来显示【还需要几天】
1 | --------------------cat cal_retired.sh |
case
通常字符串不加双引号,通常有空格等特殊字符才加双引号。
我建议:最好加上双引号。
1 | case ${变量名} in |
》》》小练习
1、参数传 a 输出 1
2、传 b 或 c 输出 2
3、传空字符串,或不传参数 输出 3
4、其他参数 输出 4
1 | ----------------------------cat abc123.sh |
》》》关于 $0 的独特用途
1 | ----------------------------/etc/init.d/netconsole |
》》》关于“case ${变量} in”,其中 ${变量} 有两种获得方式。
1、直接下达式:例如上面提到的,利用『 script.sh variable 』的方式来直接给予$1这个变数的内容,这也是在/etc/init.d目录下大多数程式的设计方式。
2、互动式:透过read这个指令来让使用者输入变数的内容。
举个例子:
1 |
|
function:函数
1 | #===> 定义 |
》》》注意点:
1 | 1、因为shell script的执行方式是由上而下,由左而右。 |
》》》小练习1
1、定义一个函数,并传入一个返回值 a,在函数内打印出来
2、函数返回值 1
3、外部传入参数,并打印出来
1 | ----------------------------cat fun1.sh |
》》》小练习2
1、脚本参数传 aa,bb
2、函数参数传 a
3、在函数内外打印 $0。$1,$2,$*,$@,$#,…
1 | ----------------------------cat fun2.sh |
》》》查看/etc/init.d/netconsole {start|stop|status|restart|condrestart}的设计
1 | ----------------------------cat -n /etc/init.d/netconsole |
while,until:循环
1 | #===> while:当“条件成立执行循环”,直到条件不成立时才停止 |
》》》小练习
计算1 + 2 + 3 + ... + 100 = ?
1 | ----------------------------cat while.sh |
for:循环语法1
一行写法:for taskId in 30 ; do curl --location --request PUT "http://127.0.0.1:80/mgmt/taskCfg/stop/${taskId}" ; echo -e "\n"; done
1 | #===> 语法 1(第一次循环 变量=值1,第二次循环 变量=值2,...) |
》》》小练习1:依次循环输出 morning afternoon evening
1 | ----------------------------cat for1.sh |
》》》小练习2:输入三个参数,比较 $@,$* 的区别
1 | ----------------------------cat for2.sh |
》》》注意:上面是加了双引号的,若不加双引号,二者效果一致
1 | ----------------------------cat for2.sh |
》》》小练习3:循环打印/etc/passwd的用户名
1 | ----------------------------cat for3.sh |
》》》小练习4:借助seq 命令计算1 + 2 + 3 + ... + 100 = ?
1 | -----------------------cat for4.sh |
》》》小练习5:输入一个目录,显示里面所有档案的 rwx 权限
1 | -----------------------cat dir_perm.sh |
for:循环语法2
1 | #===> 语法 2(注意:for 是两个小括号) |
》》》小练习:计算1 + 2 + 3 + ... + 100 = ?
1 | -----------------------cat for5.sh |
RANDOM:随机数
》》》Linux 中 $RANDOM 用于生成 [0,32767] 的随机数
1 | #===> 生成 [0,32767] 的随机数:0,2^15-1 |
shell script 的追踪与debug
语法检测(个人感觉没太大用啊)
1 | [dmtsai@study ~]$ sh [-nvx] scripts.sh |
习题
whoami,pwd
请建立一支script ,当你执行该script 的时候,该script 可以显示:
1、你目前的身份(用whoami )
2、你目前所在的目录(用pwd)
1 | ----------------cat howami-pwd.sh |
几天生日
请自行建立一支程式,该程式可以用来计算『你还有几天可以过生日』啊?
1 | ----------------cat birthday.sh |
累加数字
让使用者输入一个数字,程式可以由1+2+3… 一直累加到使用者输入的数字为止。
1 | ----------------cat sum.sh |
判断档案
撰写一支程式,他的作用是:
1、先查看一下/root/test/logical 这个名称是否存在;
2、若不存在,则建立一个档案,使用touch 来建立,建立完成后离开;
3、如果存在的话,判断该名称是否为档案,若为档案则将之删除后建立一个目录,档名为logical ,之后离开;
4、如果存在的话,而且该名称为目录,则移除此目录!
1 | ----------------cat ./check.sh |
分割 /etc/passwd
我们知道/etc/passwd 里面以: 冒号来分隔,第一栏为帐号名称。
请写一只程式,可以将/etc/passwd 的第一栏取出,而且每一栏都以一行字串『The 1 account is “root” 』来显示,那个1 表示行数。
》》》方式1:awk NR 记录行号
1 | ----------------cat passwd.sh |
》》》方式2:定义变量,for 循环 ++ 记录行号
1 | ----------------cat passwd2.sh |
useradd:添加用户
1 |
|
1 | ----------------useradd taopanfeng |
其实系统已经帮我们规定好非常多的预设值了,所以我们可以简单的使用『 useradd 帐号』来建立使用者即可。
CentOS 这些预设值主要会帮我们处理几个项目:
1、在/etc/passwd 里面建立一行与帐号相关的资料,包括建立UID/GID/家目录等;
2、在/etc/shadow 里面将此帐号的密码相关参数填入,但是尚未有密码;
3、在/etc/group 里面加入一个与帐号名称一模一样的群组名称;
4、在/home 底下建立一个与帐号同名的目录作为使用者家目录,且权限为700
使用useradd 建立使用者帐号时,其实会更改不少地方,至少我们就知道底下几个档案:
1、使用者帐号与密码参数方面的档案:/etc/passwd, /etc/shadow
2、使用者群组相关方面的档案:/etc/group, /etc/gshadow
3、使用者的家目录:/home/帐号名称
passwd:设置密码
1 | [root@study ~]# passwd [--stdin] [帐号名称] <==所有人均可使用来改自己的密码 |
usermod:修改用户
如果你仔细的比对,会发现usermod的选项与useradd非常类似!这是因为usermod也是用来微调useradd增加的使用者参数嘛!
不过usermod还是有新增的选项,那就是-L与-U ,不过这两个选项其实与passwd的-l, -u是相同的!
1 | [root@study ~]# usermod [-cdegGlsuLU] username |
userdel:删除用户
这个功能就太简单了,目的在删除使用者的相关资料,而使用者的资料有:
1、使用者帐号/密码相关参数:/etc/passwd, /etc/shadow
2、使用者群组相关参数:/etc/group, /etc/gshadow
3、使用者个人档案资料: /home/username, /var/spool/mail/username..
1 | [root@study ~]# userdel [-r] username |
如果想要完整的将某个帐号完整的移除,最好可以在下达userdel -r username之前,
先以『 find / -user username 』查出整个系统内属于username的档案,然后再加以删除吧!
id:查看用户
id 这个指令则可以查询某人或自己的相关UID/GID 等等的资讯,他的参数也不少,不过,都不需要记~反正使用id 就全部都列出啰!
1 |
|
finger:查看用户信息
通过yum -y install finger安装
1 | [root@study ~]# finger [-s] username |
Login:为使用者帐号,亦即/etc/passwd 内的第一栏位;
Name:为全名,亦即/etc/passwd 内的第五栏位(或称为注解);
Directory:就是家目录了;
Shell:就是使用的Shell 档案所在;
Never logged in.:figner 还会调查使用者登入主机的情况喔!
No mail.:调查/var/spool/mail 当中的信箱资料;
No Plan.:调查~vbird1/.plan 档案,并将该档案取出来说明!
groupadd:添加群组
1 |
|
groupmod:修改群组
跟usermod类似的,这个指令仅是在进行group相关参数的修改而已。
1 |
|
groupdel:删除群组
1 |
|
为什么mygroup可以删除,但是vbird1就不能删除呢?
原因很简单,『有某个帐号(/etc/passwd)的initial group使用该群组!』如果查阅一下,你会发现在/etc/passwd内的vbird1第四栏的GID就是/etc/group内的vbird1那个群组的GID ,
所以啰,当然无法删除~否则vbird1这个使用者登入系统后,就会找不到GID ,那可是会造成很大的困扰的!那么如果硬要删除vbird1这个群组呢?
你『必须要确认/etc/passwd内的帐号没有任何人使用该群组作为initial group』才行喔!
所以,你可以:
、修改vbird1 的GID ,或者删除vbird1 这个使用者。
gpasswd:群组管理员功能
如果系统管理员太忙碌了,导致某些帐号想要加入某个专案时找不到人帮忙!这个时候可以建立『群组管理员』喔!
什么是群组管理员呢?就是让某个群组具有一个管理员,这个群组管理员可以管理哪些帐号可以加入/移出该群组!
那要如何『建立一个群组管理员』呢?就得要透过gpasswd 啰!
1 |
|
setfacl,getfacl
省略学习
su:身份切换
1 | [root@study ~]# su [-lm] [-c指令] [username] |
上表的解释当中有出现之前第十章谈过的login-shell设定档读取方式,如果你忘记那是啥东西,请先回去第十章瞧瞧再回来吧!
这个su的用法当中,有没有加上那个减号『 - 』差很多喔!
因为涉及login-shell与non-login shell的变数读取方法。这里让我们以一个小例子来说明吧!
1 |
|
单纯使用『 su 』切换成为root的身份,读取的变数设定方式为non-login shell的方式,
这种方式很多原本的变数不会被改变,尤其是我们之前谈过很多次的PATH这个变数,由于没有改变成为root的环境,
因此很多root惯用的指令就只能使用绝对路径来执行咯。其他的还有MAIL这个变数,你输入mail时,收到的邮件竟然还是dmtsai的,而不是root本身的邮件!
是否觉得很奇怪啊!所以切换身份时,请务必使用如下的范例二:
1 | 范例二:使用login shell的方式切换为root的身份并观察变数 |
上述的作法是让使用者的身份变成root 并开始操作系统,如果想要离开root 的身份则得要利用exit 离开才行。
那我如果只是想要执行『一个只有root 才能进行的指令,且执行完毕就恢复原本的身份』呢?
那就可以加上-c 这个选项啰!请参考底下范例三!
1 | 范例三:dmtsai想要执行『 head -n 3 /etc/shadow 』一次,且已知root密码 |
由于/etc/shadow 权限的关系,该档案仅有root 可以查阅。
为了查阅该档案,所以我们必须要使用root 的身份工作。但我只想要进行一次该指令而已,此时就使用类似上面的语法吧!
好,那接下来,如果我是root 或者是其他人, 想要变更成为某些特殊帐号,可以使用如下的方法来切换喔!
1 | 范例四:原本是dmtsai这个使用者,想要变换身份成为vbird1时? |
su 就这样简单的介绍完毕,总结一下他的用法是这样的:
1、若要完整的切换到新使用者的环境,必须要使用『 su - username 』或『 su -l username 』, 才会连同PATH/USER/MAIL 等变数都转成新使用者的环境;
2、如果仅想要执行一次root 的指令,可以利用『 su - -c “指令串” 』的方式来处理;
3、使用root 切换成为任何使用者时,并不需要输入新使用者的密码;
虽然使用su很方便啦,不过缺点是,当我的主机是多人共管的环境时,如果大家都要使用su来切换成为root的身份,那么不就每个人都得要知道root的密码,这样密码太多人知道可能会流出去,很不妥当呢!怎办?透过sudo来处理即可!
sudo:root执行
除非是信任用户,否则一般用户预设是不能操作sudo 的喔!
由于一开始系统预设仅有root可以执行sudo,
1 | [root@study ~]# sudo [-b] [-u新使用者帐号] |
sudo 可以让你切换身份来进行某项任务,例如上面的两个范例。范例一中,我们的root 使用sshd 的权限去进行某项任务!
要注意,因为我们无法使用『 su - sshd 』去切换系统帐号(因为系统帐号的shell 是/sbin/nologin), 这个时候sudo 真是他X 的好用了!
立刻以sshd 的权限在/tmp 底下建立档案!查阅一下档案权限你就了解意义啦!
至于范例二则更使用多重指令串(透过分号; 来延续指令进行),使用sh -c 的方法来执行一连串的指令, 如此真是好方便!
但是sudo 预设仅有root 能使用啊!为什么呢?因为sudo 的执行是这样的流程:
1、当使用者执行sudo 时,系统于/etc/sudoers 档案中搜寻该使用者是否有执行sudo 的权限;
2、若使用者具有可执行sudo 的权限后,便让使用者『输入使用者自己的密码』来确认;
3、若密码输入成功,便开始进行sudo 后续接的指令(但root 执行sudo 时,不需要输入密码);
4、若欲切换的身份与执行者身份相同,那也不需要输入密码。
所以说,sudo执行的重点是:『能否使用sudo必须要看/etc/sudoers的设定值,而可使用sudo者是透过输入使用者自己的密码来执行后续的指令串』喔!
由于能否使用与/etc/sudoers有关,所以我们当然要去编辑sudoers档案啦!
不过,因为该档案的内容是有一定的规范的,因此直接使用vi去编辑是不好的。此时,我们得要透过visudo去修改这个档案喔!
visudo 与/etc/sudoers
使用 visudo 来对 /etc/sudoers 文件编辑
1、添加用户,使之可使用 sudo 命令
1 | [root@study ~]# visudo |
修改之后,taopanfeng 用户就可以使用 sudo 命令了。
1 | [root@localhost ~]# su taopanfeng |
1 | root ALL=(ALL) ALL <==这是预设值 |
上面这一行的四个值分别是什么意思?:
1、『使用者帐号』:系统的哪个帐号可以使用sudo 这个指令的意思;
2、『登入者的来源主机名称』:当这个帐号由哪部主机连线到本Linux 主机,意思是这个帐号可能是由哪一部网路主机连线过来的, 这个设定值可以指定用户端电脑(信任的来源的意思)。预设值root 可来自任何一部网路主机
3、『(可切换的身份)』:这个帐号可以切换成什么身份来下达后续的指令,预设root 可以切换成任何人;
4、『可下达的指令』:可用该身份下达什么指令?这个指令请务必使用绝对路径撰写。预设root可以切换任何身份且进行任何指令之意。
注:那个ALL 是特殊的关键字,代表任何身份、主机或指令的意思。
2、利用 wheel 群组以及 NOPASSWD 免密码的功能处理visudo
》》》免密登录
1 | 98 root ALL=(ALL) ALL |
》》》利用 wheel 群组,免密登录
1 | 98 root ALL=(ALL) ALL |
3、有限制的命令操作
1 | [root@study ~]# visudo <==注意是root身份 |
上面的设定值指的是『myuser1可以切换成为root使用passwd这个指令』的意思。
其中要注意的是: 指令栏位必须要填写绝对路径才行!否则visudo会出现语法错误的状况发生!
1 |
|
恐怖啊!我们竟然让root 的密码被myuser1 给改变了!
1 |
|
在设定值中加上惊叹号『 ! 』代表『不可执行』的意思。
因此上面这一行会变成:可以执行『 passwd 任意字元』,但是『 passwd 』与『 passwd root 』这两个指令例外!如此一来myuser1 就无法改变root 的密码了!
这样这位使用者可以具有root 的能力帮助你修改其他用户的密码, 而且也不能随意改变root 的密码!很有用处的!
4、透过别名建置visudo
省略学习
w,who,whoami,last,lastlog
1 | ---------------w #===> 谁在线上 |
quota:磁碟配额
Quota 是什么?
在Linux 系统中,由于是多人多工的环境,所以会有多人共同使用一个硬碟空间的情况发生, 如果其中有少数几个使用者大量的占掉了硬碟空间的话,那势必压缩其他使用者的使用权力!因此管理员应该适当的限制硬碟的容量给使用者,以妥善的分配系统资源!避免有人抗议呀!
举例来说,我们使用者的预设家目录都是在/home 底下,如果/home 是个独立的partition , 假设这个分割槽有10G 好了,而/home 底下共有30 个帐号,也就是说,每个使用者平均应该会有333MB 的空间才对。偏偏有个使用者在他的家目录底下塞了好多只影片,占掉了8GB 的空间,想想看,是否造成其他正常使用者的不便呢?如果想要让磁碟的容量公平的分配,这个时候就得要靠quota 的帮忙啰!
Quota 的一般用途
quota 比较常使用的几个情况是:
、针对WWW server ,例如:每个人的网页空间的容量限制!
、针对mail server,例如:每个人的邮件空间限制。
、针对file server,例如:每个人最大的可用网路硬碟空间(教学环境中最常见!)
上头讲的是针对网路服务的设计,如果是针对Linux 系统主机上面的设定那么使用的方向有底下这一些:
1、限制某一群组所能使用的最大磁碟配额(使用群组限制):
你可以将你的主机上的使用者分门别类,有点像是目前很流行的付费与免付费会员制的情况,你比较喜好的那一群的使用配额就可以给高一些!呵呵!^_^…
2、限制某一使用者的最大磁碟配额(使用使用者限制):
在限制了群组之后,你也可以再继续针对个人来进行限制,使得同一群组之下还可以有更公平的分配!
3、限制某一目录(directory, project)的最大磁碟配额:
在旧版的CentOS当中,使用的预设档案系统为EXT家族,这种档案系统的磁碟配额主要是针对整个档案系统来处理,所以大多针对『挂载点』进行设计。新的xfs可以使用project这种模式,就能够针对个别的目录(非档案系统喔)来设计磁碟配额耶!超棒的!
基本上,quota 就是在回报管理员磁碟使用率以及让管理员管理磁碟使用情况的一个工具就是了!
比较特别的是,XFS 的quota 是整合到档案系统内,并不是其他外挂的程式来管理的。
因此,透过quota 来直接回报磁碟使用率,要比unix 工具来的快速!
举例来说, du 这东西会重新计算目录下的磁碟使用率,但xfs 可以透过xfs_quota 来直接回报各目录使用率,速度上是快非常多!
Quota 的使用限制
1、在EXT档案系统家族仅能针对整个filesystem:
EXT档案系统家族在进行quota限制的时候,它仅能针对整个档案系统来进行设计,无法针对某个单一的目录来设计它的磁碟配额。
因此,如果你想要使用不同的档案系统进行quota时,请先搞清楚该档案系统支援的情况喔!因为XFS已经可以使用project模式来设计不同目录的磁碟配额。
2、核心必须支援quota :
Linux核心必须有支援quota这个功能才行:如果你是使用CentOS 7.x的预设核心,嘿嘿!那恭喜你了,你的系统已经预设有支援quota这个功能啰!
如果你是自行编译核心的,那么请特别留意你是否已经『真的』开启了quota这个功能?否则底下的功夫将全部都视为『白工』。
3、只对一般身份使用者有效:
这就有趣了!并不是所有在Linux上面的帐号都可以设定quota呢,例如root就不能设定quota ,因为整个系统所有的资料几乎都是他的啊!^_^
4、若启用SELinux,非所有目录均可设定quota :
新版的CentOS预设都有启用SELinux这个核心功能,该功能会加强某些细部的权限控制!由于担心管理员不小心设定错误,因此预设的情况下, quota似乎仅能针对/home进行设定而已~
因此,如果你要针对其他不同的目录进行设定,请参考到后续章节查阅解开SELinux限制的方法喔!这就不是quota的问题了…
新版的CentOS使用的xfs确实比较有趣!不但无须额外的quota纪录档,也能够针对档案系统内的不同目录进行配置!
相当有趣!只是不同的档案系统在quota的处理情况上不太相同,因此这里要特别强调,进行quota前,先确认你的档案系统吧!
Quota 的规范设定项目
quota 这玩意儿针对XFS filesystem 的限制项目主要分为底下几个部分:
1、分别针对使用者、群组或个别目录(user, group & project):
XFS 档案系统的quota 限制中,主要是针对群组、个人或单独的目录进行磁碟使用率的限制!
2、容量限制或档案数量限制(block 或inode):
我们在第七章谈到档案系统中,说到档案系统主要规划为存放属性的inode与实际档案资料的block区块,Quota既然是管理档案系统,所以当然也可以管理inode或block啰!
这两个管理的功能为:
、、、限制inode 用量:可以管理使用者可以建立的『档案数量』;
、、、限制block 用量:管理使用者磁碟容量的限制,较常见为这种方式。
3、柔性劝导与硬性规定(soft/hard):
既然是规范,当然就有限制值。不管是inode/block ,限制值都有两个,分别是soft 与hard。通常hard 限制值要比soft 还要高。
举例来说,若限制项目为block ,可以限制hard 为500MBytes 而soft 为400MBytes。这两个限值的意义为:
、、、hard:表示使用者的用量绝对不会超过这个限制值,以上面的设定为例, 使用者所能使用的磁碟容量绝对不会超过500Mbytes ,若超过这个值则系统会锁住该用户的磁碟使用权;
、、、soft:表示使用者在低于soft 限值时(此例中为400Mbytes),可以正常使用磁碟,但若超过soft 且低于hard 的限值(介于400~500Mbytes 之间时),每次使用者登入系统时,系统会主动发出磁碟即将爆满的警告讯息, 且会给予一个宽限时间(grace time)。不过,若使用者在宽限时间倒数期间就将容量再次降低于soft 限值之下, 则宽限时间会停止。
4、会倒数计时的宽限时间(grace time):
刚刚上面就谈到宽限时间了!这个宽限时间只有在使用者的磁碟用量介于soft到hard之间时,才会出现且会倒数的一个咚咚!
由于达到hard限值时,使用者的磁碟使用权可能会被锁住。为了担心使用者没有注意到这个磁碟配额的问题,因此设计了soft 。
当你的磁碟用量即将到达hard且超过soft时,系统会给予警告,但也会给一段时间让使用者自行管理磁碟。
一般预设的宽限时间为七天,如果七天内你都不进行任何磁碟管理,那么soft限制值会即刻取代hard限值来作为quota的限制。
以上面设定的例子来说,假设你的容量高达450MBytes 了,那七天的宽限时间就会开始倒数, 若七天内你都不进行任何删除档案的动作来替你的磁碟用量瘦身, 那么七天后你的磁碟最大用量将变成400MBytes (那个soft 的限制值),此时你的磁碟使用权就会被锁住而无法新增档案了。
整个soft, hard, grace time 的相关性我们可以用底下的图示来说明: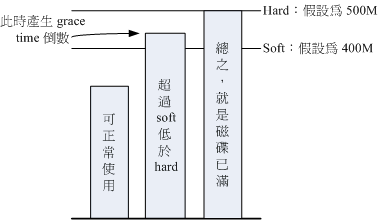
图中的长条图为使用者的磁碟容量,soft/hard 分别是限制值。只要小于400M 就一切OK , 若高于soft 就出现grace time 并倒数且等待使用者自行处理,若到达hard 的限制值, 那我们就搬张小板凳等着看好戏啦!嘿嘿!^_^!这样图示有清楚一点了吗?
RAID:磁碟阵列
什么是 RAID?
磁碟阵列全名是『 Redundant Arrays of Independent Disks, RAID 』,英翻中的意思为:独立容错式磁碟阵列,旧称为容错式廉价磁碟阵列,反正就称为磁碟阵列即可!RAID可以透过一个技术(软体或硬体),将多个较小的磁碟整合成为一个较大的磁碟装置;而这个较大的磁碟功能可不止是储存而已,他还具有资料保护的功能呢。
整个RAID由于选择的等级(level)不同,而使得整合后的磁碟具有不同的功能,基本常见的 level 有下面这几种:
RAID-0 (等量模式, stripe):效能最佳
(陶攀峰)个人理解:相当于多线程的理解,不然是单线程,使用了这个之后是多线程处理(所以速度快),但是其中一个线程不行了,那么整体的数据就不正确了,就会有丢失或损坏。
这种模式如果使用相同型号与容量的磁碟来组成时,效果较佳。
这种模式的RAID 会将磁碟先切出等量的区块(名为chunk,一般可设定4K~1M 之间), 然后当一个档案要写入RAID 时,该档案会依据chunk 的大小切割好,之后再依序放到各个磁碟里面去。
由于每个磁碟会交错的存放资料, 因此当你的资料要写入RAID 时,资料会被等量的放置在各个磁碟上面。
举例来说,你有两颗磁碟组成RAID-0 , 当你有100MB 的资料要写入时,每个磁碟会各被分配到50MB 的储存量。
RAID-0 的示意图如下所示: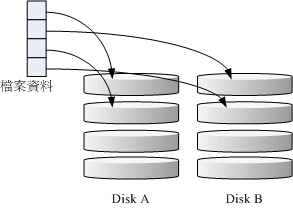
上图的意思是,在组成RAID-0时,每颗磁碟(Disk A与Disk B)都会先被区隔成为小区块(chunk)。当有资料要写入RAID时,资料会先被切割成符合小区块的大小,然后再依序一个一个的放置到不同的磁碟去。由于资料已经先被切割并且依序放置到不同的磁碟上面,因此每颗磁碟所负责的资料量都降低了!照这样的情况来看, 越多颗磁碟组成的RAID-0效能会越好,因为每颗负责的资料量就更低了!这表示我的资料可以分散让多颗磁碟来储存,当然效能会变的更好啊!此外,磁碟总容量也变大了!因为每颗磁碟的容量最终会加总成为RAID-0的总容量喔!
只是使用此等级你必须要自行负担资料损毁的风险,由上图我们知道档案是被切割成为适合每颗磁碟分割区块的大小,然后再依序放置到各个磁碟中。想一想,如果某一颗磁碟损毁了,那么档案资料将缺一块,此时这个档案就损毁了。由于每个档案都是这样存放的,因此RAID-0只要有任何一颗磁碟损毁,在RAID上面的所有资料都会遗失而无法读取。
另外,如果使用不同容量的磁碟来组成RAID-0 时,由于资料是一直等量的依序放置到不同磁碟中,当小容量磁碟的区块被用完了, 那么所有的资料都将被写入到最大的那颗磁碟去。举例来说,我用200G 与500G 组成RAID-0 , 那么最初的400GB 资料可同时写入两颗磁碟(各消耗200G 的容量),后来再加入的资料就只能写入500G 的那颗磁碟中了。此时的效能就变差了,因为只剩下一颗可以存放资料嘛!
RAID-1 (映射模式, mirror):完整备份
(陶攀峰)个人理解:相当于分布式的主从模式,但是它只有一个副本,如果自己丢失了,还是副本可以工作,如果副本丢失了,那么“恭喜你”,数据就彻底的丢失了。因为要拷贝一份同样的,所以容量减少一半。
这种模式也是需要相同的磁碟容量的,最好是一模一样的磁碟啦!如果是不同容量的磁碟组成RAID-1时,那么总容量将以最小的那一颗磁碟为主!这种模式主要是『让同一份资料,完整的保存在两颗磁碟上头』。
举例来说,如果我有一个100MB的档案,且我仅有两颗磁碟组成RAID-1时,那么这两颗磁碟将会同步写入100MB到他们的储存空间去。因此,整体RAID的容量几乎少了50%。由于两颗硬碟内容一模一样,好像镜子映照出来一样,所以我们也称他为mirror模式啰~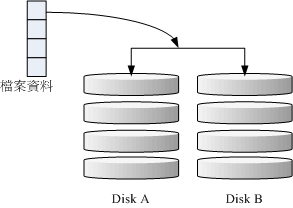
如上图所示,一份资料传送到RAID-1 之后会被分为两股,并分别写入到各个磁碟里头去。由于同一份资料会被分别写入到其他不同磁碟,因此如果要写入100MB 时,资料传送到I/O 汇流排后会被复制多份到各个磁碟, 结果就是资料量感觉变大了!因此在大量写入RAID-1 的情况下,写入的效能可能会变的非常差(因为我们只有一个南桥啊!)。好在如果你使用的是硬体RAID (磁碟阵列卡) 时,磁碟阵列卡会主动的复制一份而不使用系统的I/O 汇流排,效能方面则还可以。如果使用软体磁碟阵列,可能效能就不好了。
由于两颗磁碟内的资料一模一样,所以任何一颗硬碟损毁时,你的资料还是可以完整的保留下来的!所以我们可以说,RAID-1最大的优点大概就在于资料的备份吧!不过由于磁碟容量有一半用在备份,因此总容量会是全部磁碟容量的一半而已。虽然RAID-1的写入效能不佳,不过读取的效能则还可以啦!这是因为资料有两份在不同的磁碟上面,如果多个processes在读取同一笔资料时, RAID会自行取得最佳的读取平衡。
RAID 1+0,RAID 0+1:组合模式
(陶攀峰)个人理解:上面0和1的综合体。多个线程进行工作,每个线程再建立一份副本。
RAID-0 的效能佳但是资料不安全,RAID-1 的资料安全但是效能不佳,那么能不能将这两者整合起来设定RAID 呢?可以啊!那就是RAID 1+0 或RAID 0+1。
所谓的RAID 1+0 就是: (1)先让两颗磁碟组成RAID 1,并且这样的设定共有两组; (2)将这两组RAID 1 再组成一组RAID 0。这就是RAID 1+0 啰!反过来说,RAID 0+1 就是先组成RAID-0 再组成RAID-1 的意思。
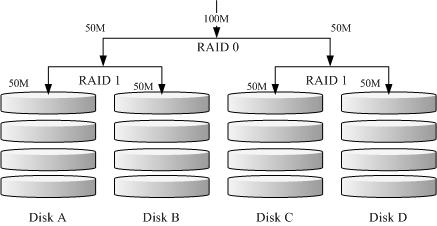
如上图所示,Disk A + Disk B 组成第一组RAID 1,Disk C + Disk D 组成第二组RAID 1, 然后这两组再整合成为一组RAID 0。如果我有100MB 的资料要写入,则由于RAID 0 的关系, 两组RAID 1 都会写入50MB,又由于RAID 1 的关系,因此每颗磁碟就会写入50MB 而已。如此一来不论哪一组RAID 1 的磁碟损毁,由于是RAID 1 的映像资料,因此就不会有任何问题发生了!这也是目前储存设备厂商最推荐的方法!
为何会推荐RAID 1+0 呢?想像你有20 颗磁碟组成的系统,每两颗组成一个RAID1,因此你就有总共10组可以自己复原的系统了!然后这10组再组成一个新的RAID0,速度立刻拉升10倍了!同时要注意,因为每组RAID1 是个别独立存在的,因此任何一颗磁碟损毁, 资料都是从另一颗磁碟直接复制过来重建,并不像RAID5/RAID6 必须要整组RAID 的磁碟共同重建一颗独立的磁碟系统!效能上差非常多!而且RAID 1 与RAID 0 是不需要经过计算的(striping) !读写效能也比其他的RAID 等级好太多了!
RAID 5:效能与资料备份的均衡考量
(陶攀峰)个人理解:因为至少三个,所以其中一个当做 parity 使用,所以真正使用的有两个。但是其中一个坏了,另外一个还可以恢复,但是这两个都坏了,就彻底丢失数据了。
RAID-5 至少需要三颗以上的磁碟才能够组成这种类型的磁碟阵列。
这种磁碟阵列的资料写入有点类似RAID-0 , 不过每个循环的写入过程中(striping),在每颗磁碟还加入一个同位检查资料(Parity) ,这个资料会记录其他磁碟的备份资料, 用于当有磁碟损毁时的救援。RAID-5 读写的情况有点像底下这样:
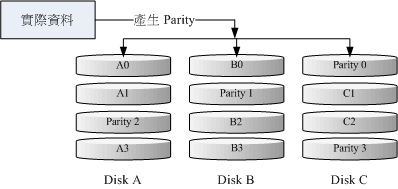
横向看,一层一层看。图中一层有三个位置。每层有一个 parity,其他两个为副本。
如上图所示,每个循环写入时,都会有部分的同位检查码(parity)被记录起来,并且记录的同位检查码每次都记录在不同的磁碟,因此,任何一个磁碟损毁时都能够藉由其他磁碟的检查码来重建原本磁碟内的资料喔!不过需要注意的是,由于有同位检查码,因此RAID 5的总容量会是整体磁碟数量减一颗。以上图为例,原本的3颗磁碟只会剩下(3-1)=2颗磁碟的容量。而且当损毁的磁碟数量大于等于两颗时,这整组RAID 5的资料就损毁了。因为RAID 5预设仅能支援一颗磁碟的损毁情况。
在读写效能的比较上,读取的效能还不赖!与RAID-0 有的比!不过写的效能就不见得能够增加很多!这是因为要写入RAID 5 的资料还得要经过计算同位检查码(parity) 的关系。由于加上这个计算的动作, 所以写入的效能与系统的硬体关系较大!尤其当使用软体磁碟阵列时,同位检查码是透过CPU 去计算而非专职的磁碟阵列卡, 因此效能方面还需要评估。
另外,由于RAID 5 仅能支援一颗磁碟的损毁,因此近来还有发展出另外一种等级,就是RAID 6 ,这个RAID 6 则使用两颗磁碟的容量作为parity 的储存,因此整体的磁碟容量就会少两颗,但是允许出错的磁碟数量就可以达到两颗了!也就是在RAID 6 的情况下,同时两颗磁碟损毁时,资料还是可以救回来!
Spare Disk:预备磁碟的功能
(陶攀峰)个人理解:相当于一个不断开,可以继续工作
当磁碟阵列的磁碟损毁时,就得要将坏掉的磁碟拔除,然后换一颗新的磁碟。换成新磁碟并且顺利启动磁碟阵列后, 磁碟阵列就会开始主动的重建(rebuild) 原本坏掉的那颗磁碟资料到新的磁碟上!然后你磁碟阵列上面的资料就复原了!这就是磁碟阵列的优点。不过,我们还是得要动手拔插硬碟,除非你的系统有支援热拔插,否则通常得要关机才能这么做。
为了让系统可以即时的在坏掉硬碟时主动的重建,因此就需要预备磁碟(spare disk) 的辅助。所谓的spare disk 就是一颗或多颗没有包含在原本磁碟阵列等级中的磁碟,这颗磁碟平时并不会被磁碟阵列所使用, 当磁碟阵列有任何磁碟损毁时,则这颗spare disk 会被主动的拉进磁碟阵列中,并将坏掉的那颗硬碟移出磁碟阵列!然后立即重建资料系统。如此你的系统则可以永保安康啊!若你的磁碟阵列有支援热拔插那就更完美了!直接将坏掉的那颗磁碟拔除换一颗新的,再将那颗新的设定成为spare disk ,就完成了!
举例来说,鸟哥之前所待的研究室有一个磁碟阵列可允许16 颗磁碟的数量,不过我们只安装了10 颗磁碟作为RAID 5。每颗磁碟的容量为250GB,我们用了一颗磁碟作为spare disk ,并将其他的9 颗设定为一个RAID 5, 因此这个磁碟阵列的总容量为: (9-1) x 250G= 2000G。运作了一两年后真的有一颗磁碟坏掉了,我们后来看灯号才发现!不过对系统没有影响呢!因为spare disk 主动的加入支援,坏掉的那颗拔掉换颗新的,并重新设定成为spare 后, 系统内的资料还是完整无缺的!嘿嘿!真不错!
磁碟阵列的总结
说的口沫横飞,重点在哪里呢?其实你的系统如果需要磁碟阵列的话,其实重点在于:
1、资料安全与可靠性:指的并非网路资讯安全,而是当硬体(指磁碟) 损毁时,资料是否还能够安全的救援或使用之意;
2、读写效能:例如RAID 0 可以加强读写效能,让你的系统I/O 部分得以改善;
3、容量:可以让多颗磁碟组合起来,故单一档案系统可以有相当大的容量。
尤其资料的可靠性与完整性更是使用RAID 的考量重点!毕竟硬体坏掉换掉就好了,软体资料损毁那可不是闹着玩的!所以企业界为何需要大量的RAID 来做为档案系统的硬体基准,现在您有点了解了吧?那依据这三个重点,我们来列表看看上面几个重要的RAID 等级各有哪些优点吧!
假设有n 颗磁碟组成的RAID 设定喔!
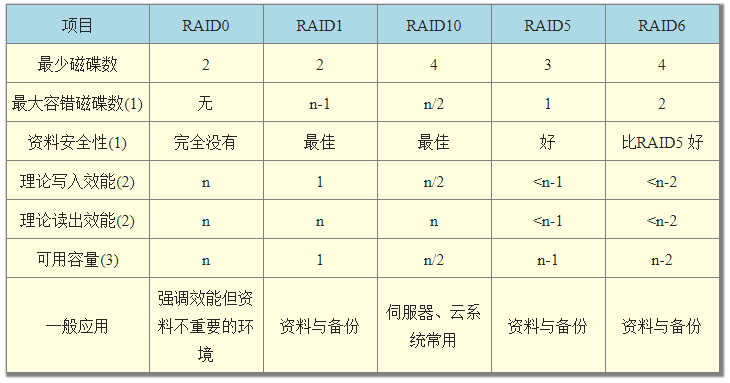
注:因为RAID5, RAID6 读写都需要经过parity 的计算机制,因此读/写效能都不会刚好满足于使用的磁碟数量喔!
另外,根据使用的情况不同,一般推荐的磁碟阵列等级也不太一样。以鸟哥为例,在鸟哥的跑空气品质模式之后的输出资料,动辄几百GB 的单一大档案资料, 这些情况鸟哥会选择放在RAID6 的阵列环境下,这是考量到资料保全与总容量的应用,因为RAID 6 的效能已经足以应付模式读入所需的环境。
近年来鸟哥也比较积极在作一些云程式环境的设计,在云环境下,确保每个虚拟机器能够快速的反应以及提供资料保全是最重要的部份!因此效能方面比较弱的RAID5/RAID6 是不考虑的,总结来说,大概就剩下RAID10 能够满足云环境的效能需求了。在某些更特别的环境下, 如果搭配SSD 那才更具有效能上的优势哩!
software, hardware RAID
为何磁碟阵列又分为硬体与软体呢?所谓的硬体磁碟阵列(hardware RAID) 是透过磁碟阵列卡来达成阵列的目的。磁碟阵列卡上面有一块专门的晶片在处理RAID 的任务,因此在效能方面会比较好。在很多任务(例如RAID 5 的同位检查码计算) 磁碟阵列并不会重复消耗原本系统的I/O 汇流排,理论上效能会较佳。此外目前一般的中高阶磁碟阵列卡都支援热拔插, 亦即在不关机的情况下抽换损坏的磁碟,对于系统的复原与资料的可靠性方面非常的好用。
不过一块好的磁碟阵列卡动不动就上万元台币,便宜的在主机板上面『附赠』的磁碟阵列功能可能又不支援某些高阶功能, 例如低阶主机板若有磁碟阵列晶片,通常仅支援到RAID0 与RAID1 ,鸟哥喜欢的RAID6 并没有支援。此外,作业系统也必须要拥有磁碟阵列卡的驱动程式,才能够正确的捉到磁碟阵列所产生的磁碟机!
由于磁碟阵列有很多优秀的功能,然而硬体磁碟阵列卡偏偏又贵的很~因此就有发展出利用软体来模拟磁碟阵列的功能, 这就是所谓的软体磁碟阵列(software RAID) 。软体磁碟阵列主要是透过软体来模拟阵列的任务, 因此会损耗较多的系统资源,比如说CPU 的运算与I/O 汇流排的资源等。不过目前我们的个人电脑实在已经非常快速了, 因此以前的速度限制现在已经不存在!所以我们可以来玩一玩软体磁碟阵列!
我们的CentOS提供的软体磁碟阵列为mdadm这套软体,这套软体会以partition或disk为磁碟的单位,也就是说,你不需要两颗以上的磁碟,只要有两个以上的分割槽(partition)就能够设计你的磁碟阵列了。此外, mdadm支援刚刚我们前面提到的RAID0/RAID1/RAID5/spare disk等!而且提供的管理机制还可以达到类似热拔插的功能,可以线上(档案系统正常使用)进行分割槽的抽换!使用上也非常的方便呢!
另外你必须要知道的是,硬体磁碟阵列在Linux底下看起来就是一颗实际的大磁碟,因此硬体磁碟阵列的装置档名为 /dev/sd[ap] ,因为使用到SCSI的模组之故。 至于软体磁碟阵列则是系统模拟的,因此使用的装置档名是系统的装置档,档名为 /dev/md0 , /dev/md1,两者的装置档名并不相同!不要搞混了喔!因为很多朋友常常觉得奇怪,怎么他的RAID档名跟我们这里测试的软体RAID档名不同,所以这里特别强调说明喔!
Intel 的南桥附赠的磁碟阵列功能,在windows 底下似乎是完整的磁碟阵列,但是在Linux 底下则被视为是软体磁碟阵列的一种!因此如果你有设定过Intel 的南桥晶片磁碟阵列,那在Linux 底下反而还会是/dev/md126, /dev/md127 等等装置档名, 而他的分割槽竟然是/dev/md126p1, / dev/md126p2… 之类的喔!比较特别,所以这里加强说明!
LVM:逻辑卷轴管理员
(Logical Volume Manager)
想像一个情况,你在当初规划主机的时候将/home 只给他50G ,等到使用者众多之后导致这个filesystem 不够大, 此时你能怎么作?多数的朋友都是这样:再加一颗新硬碟,然后重新分割、格式化,将/home 的资料完整的复制过来, 然后将原本的partition 卸载重新挂载新的partition 。啊!好忙碌啊!若是第二次分割却给的容量太多!导致很多磁碟容量被浪费了!你想要将这个partition 缩小时,又该如何作?将上述的流程再搞一遍!唉~烦死了,尤其复制很花时间ㄟ~有没有更简单的方法呢?有的!那就是我们这个小节要介绍的LVM 这玩意儿!
LVM的重点在于『可以弹性的调整filesystem的容量!』而并非在于效能与资料保全上面。需要档案的读写效能或者是资料的可靠性,请参考前面的RAID小节。 LVM可以整合多个实体partition在一起,让这些partitions看起来就像是一个磁碟一样!而且,还可以在未来新增或移除其他的实体partition到这个LVM管理的磁碟当中。如此一来,整个磁碟空间的使用上,实在是相当的具有弹性啊!既然LVM这么好用,那就让我们来瞧瞧这玩意吧!
什么是LVM: PV, PE, VG, LV 的意义
LVM 的全名是Logical Volume Manager,中文可以翻译作逻辑卷轴管理员。之所以称为『卷轴』可能是因为可以将 filesystem 像卷轴一样伸长或缩短之故吧!
LVM 的作法是将几个实体的partitions (或disk) 透过软体组合成为一块看起来是独立的大磁碟(VG) ,然后将这块大磁碟再经过分割成为可使用分割槽(LV),最终就能够挂载使用了。但是为什么这样的系统可以进行filesystem 的扩充或缩小呢?其实与一个称为PE 的项目有关!底下我们就得要针对这几个项目来好好聊聊!
Physical Volume, PV, 实体卷轴
我们实际的partition (或Disk)需要调整系统识别码(system ID)成为8e (LVM的识别码),然后再经过pvcreate的指令将他转成LVM最底层的实体卷轴(PV) ,之后才能够将这些PV加以利用!调整system ID的方是就是透过gdisk啦!
Volume Group, VG, 卷轴群组
所谓的LVM 大磁碟就是将许多PV 整合成这个VG 的东西就是啦!所以VG 就是LVM 组合起来的大磁碟!这么想就好了。那么这个大磁碟最大可以到多少容量呢?这与底下要说明的PE 以及LVM 的格式版本有关喔~在预设的情况下, 使用32位元的Linux 系统时,基本上LV 最大仅能支援到65534 个PE 而已,若使用预设的PE为4MB 的情况下, 最大容量则仅能达到约256GB 而已~不过,这个问题在64位元的Linux 系统上面已经不存在了!LV 几乎没有啥容量限制了!
Physical Extent, PE, 实体范围区块
LVM预设使用4MB的PE区块,而LVM的LV在32位元系统上最多仅能含有65534个PE (lvm1的格式),因此预设的LVM的LV会有4M*65534/(1024M/G )=256G。这个PE很有趣喔!他是整个LVM最小的储存区块,也就是说,其实我们的档案资料都是藉由写入PE来处理的。简单的说,这个PE就有点像档案系统里面的block大小啦。这样说应该就比较好理解了吧?所以调整PE会影响到LVM的最大容量喔!不过,在CentOS 6.x以后,由于直接使用lvm2的各项格式功能,以及系统转为64位元,因此这个限制已经不存在了。
Logical Volume, LV, 逻辑卷轴
最终的VG还会被切成LV,这个LV就是最后可以被格式化使用的类似分割槽的咚咚了!那么LV是否可以随意指定大小呢?当然不可以!既然PE是整个LVM的最小储存单位,那么LV的大小就与在此LV内的PE总数有关。为了方便使用者利用LVM来管理其系统,因此LV的装置档名通常指定为『 /dev/vgname/lvname』的样式!
此外,我们刚刚有谈到LVM 可弹性的变更filesystem 的容量,那是如何办到的?其实他就是透过『交换PE 』来进行资料转换, 将原本LV 内的PE 移转到其他装置中以降低LV 容量,或将其他装置的PE 加到此LV 中以加大容量!VG、LV 与PE 的关系有点像下图:
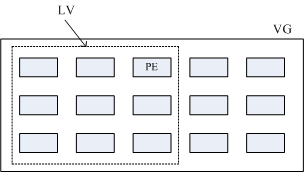
如上图所示,VG 内的PE 会分给虚线部分的LV,如果未来这个VG 要扩充的话,加上其他的PV 即可。而最重要的LV 如果要扩充的话,也是透过加入VG 内没有使用到的PE 来扩充的!
(陶攀峰)以下本人理解:
、多个磁碟搞成 LVM 流程
、多个磁碟,一个磁碟转成一个 PV(Physical Volume, PV, 实体卷轴)
、多个 PV 转成一个 VG(Volume Group, 卷轴群组)
、一个 VG 里面有很多 PE(Physical Extent, 实体范围区块)
、一个 VG 也会划分多个 LV(Logical Volume, 逻辑卷轴)
、划分的 LV 里面是包含 PE
大话:
、多个磁碟(班级)搞成 LVM(校长=学校管理员) 流程
、多个磁碟(班级),一个磁碟(班级)转成一个 PV(班级)(Physical Volume, PV, 实体卷轴)
、多个 PV (班级)转成一个 VG(学校)(Volume Group, 卷轴群组)
、一个 VG(学校) 里面有很多 PE(学生)(Physical Extent, 实体范围区块)
、一个 VG(学校) 也会划分多个 LV(年级)(Logical Volume, 逻辑卷轴)
、划分的 LV (年级)里面是包含 PE(学生)
实操流程
透过PV, VG, LV的规划之后,再利用mkfs 就可以将你的LV格式化成为可以利用的档案系统了!而且这个档案系统的容量在未来还能够进行扩充或减少,而且里面的资料还不会被影响!实在是很『福气啦!』
那实作方面要如何进行呢?很简单呢!整个流程由基础到最终的结果可以这样看:
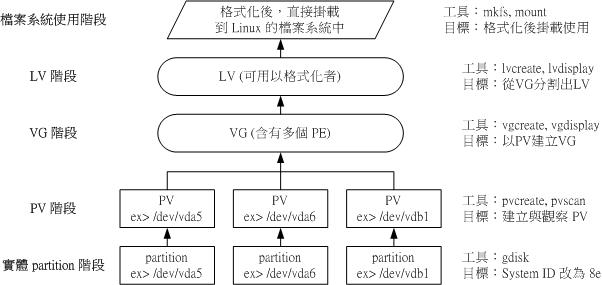
如此一来,我们就可以利用LV这个玩意儿来进行系统的挂载了。不过,你应该要觉得奇怪的是, 那么我的资料写入这个LV时,到底他是怎么写入硬碟当中的? 呵呵!好问题~其实,依据写入机制的不同,而有两种方式:
线性模式(linear):假如我将/dev/vda1, /dev/vdb1 这两个partition 加入到VG 当中,并且整个VG 只有一个LV 时,那么所谓的线性模式就是:当/dev/vda1 的容量用完之后,/dev/vdb1 的硬碟才会被使用到, 这也是我们所建议的模式。
交错模式(triped):那什么是交错模式?很简单啊,就是我将一笔资料拆成两部分,分别写入/dev/vda1 与/dev/vdb1 的意思,感觉上有点像RAID 0 啦!如此一来,一份资料用两颗硬碟来写入,理论上,读写的效能会比较好。
基本上,LVM最主要的用处是在实现一个可以弹性调整容量的档案系统上,而不是在建立一个效能为主的磁碟上,所以,我们应该利用的是LVM可以弹性管理整个partition大小的用途上,而不是著眼在效能上的。因此, LVM预设的读写模式是线性模式啦!如果你使用triped模式,要注意,当任何一个partition 『归天』时,所有的资料都会『损毁』的!所以啦,不是很适合使用这种模式啦!如果要强调效能与备份,那么就直接使用RAID即可,不需要用到LVM啊!
使用LVM thin Volume 让LVM 动态自动调整磁碟使用率
(陶攀峰)个人理解:这个池子相当于一个大棚,里面种的都是草莓,你带着篮子去摘草莓,实际装的只是你篮子的容量,而不是真实的大棚容量,这个大棚就是:LVM thin Volume
想像一个情况,你有个目录未来会使用到大约5T 的容量,但是目前你的磁碟仅有3T,问题是,接下来的两个月你的系统都还不会超过3T 的容量, 不过你想要让用户知道,就是他最多有5T 可以使用就是了!而且在一个月内你确实可以将系统提升到5T 以上的容量啊!你又不想要在提升容量后才放大到5T!那可以怎么办?呵呵!这时可以考虑『实际用多少才分配多少容量给LV 的LVM Thin Volume 』功能!
另外,再想像一个环境,如果你需要有3 个10GB 的磁碟来进行某些测试,问题是你的环境仅有5GB 的剩余容量,再传统的LVM 环境下, LV 的容量是一开始就分配好的,因此你当然没有办法在这样的环境中产生出3 个10GB 的装置啊!而且更呕的是,那个10GB 的装置其实每个实际使用率都没有超过10%, 也就是总用量目前仅会到3GB 而已!但…我实际就有5GB 的容量啊!为何不给我做出3 个只用1GB 的10GB 装置呢?有啊!就还是LVM thin Volume 啊!
什么是LVM thin Volume 呢?这东西其实挺好玩的,他的概念是:先建立一个可以实支实付、用多少容量才分配实际写入多少容量的磁碟容量储存池(thin pool), 然后再由这个thin pool 去产生一个『指定要固定容量大小的LV 装置』,这个LV 就有趣了!虽然你会看到『宣告上,他的容量可能有10GB ,但实际上, 该装置用到多少容量时,才会从thin pool 去实际取得所需要的容量』!就如同上面的环境说的,可能我们的thin pool 仅有1GB 的容量, 但是可以分配给一个10GB 的LV 装置!而该装置实际使用到500M 时,整个thin pool 才分配500M 给该LV 的意思!当然啦!在所有由thin pool 所分配出来的LV 装置中,总实际使用量绝不能超过thin pool 的最大实际容量啊!如这个案例说的, thin pool 仅有1GB, 那所有的由这个thin pool 建置出来的LV 装置内的实际用量,就绝不能超过1GB 啊!
LVM 的 LV 磁碟快照
现在你知道LVM的好处咯,未来如果你有想要增加某个LVM的容量时,就可以透过这个放大的功能来处理。那么LVM除了这些功能之外,还有什么能力呢?其实他还有一个重要的能力,那就是LV磁碟的快照(snapshot)。什么是LV磁碟快照啊?快照就是将当时的系统资讯记录下来,就好像照相记录一般!未来若有任何资料更动了,则原始资料会被搬移到快照区,没有被更动的区域则由快照区与档案系统共享。 用讲的好像很难懂,我们用图解说明一下好了:
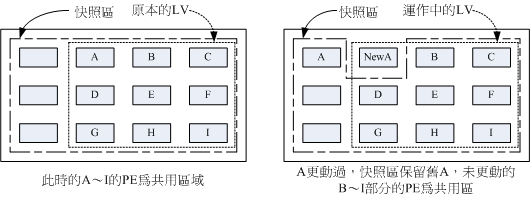
左图为最初建置LV磁碟快照区的状况,LVM会预留一个区域(左图的左侧三个PE区块)作为资料存放处。此时快照区内并没有任何资料,而快照区与系统区共享所有的PE资料,因此你会看到快照区的内容与档案系统是一模一样的。等到系统运作一阵子后,假设A区域的资料被更动了(上面右图所示),则更动前系统会将该区域的资料移动到快照区,所以在右图的快照区被占用了一块PE成为A,而其他B到I的区块则还是与档案系统共用!
照这样的情况来看,LVM 的磁碟快照是非常棒的『备份工具』,因为他只有备份有被更动到的资料, 档案系统内没有被变更的资料依旧保持在原本的区块内,但是LVM 快照功能会知道那些资料放置在哪里, 因此『快照』当时的档案系统就得以『备份』下来,且快照所占用的容量又非常小!所以您说,这不是很棒的工具又是什么?
那么快照区要如何建立与使用呢?首先,由于快照区与原本的LV共用很多PE区块,因此快照区与被快照的LV必须要在同一个VG上头。
另外,或许你跟鸟哥一样,会想到说:『咦!我们能不能使用thin pool 的功能来制作快照』呢?老实说,是可以的!不过使用上面的限制非常的多!包括最好要在同一个thin pool 内的原始LV 磁碟, 如果为非thin pool 内的原始LV 磁碟快照,则该磁碟快照『不可以写入』,亦即LV 磁碟要设定成唯读才行!同时, 使用thin pool 做出来的快照,通常都是不可启动(inactive) 的预设情况,启动又有点麻烦~所以,至少目前(CentOS 7.x) 的环境下, 鸟哥还不是很建议你使用thin pool 快照喔!
CentOS Linux 系统上常见的循环性工作
1、进行登录档的轮替(log rotate):
Linux会主动的将系统所发生的各种资讯都记录下来,这就是登录档(第十八章)。由于系统会一直记录登录资讯,所以登录档将会越来越大!我们知道大型档案不但占容量还会造成读写效能的困扰,因此适时的将登录档资料挪一挪,让旧的资料与新的资料分别存放,则比较可以有效的记录登录资讯。这就是log rotate的任务!这也是系统必要的例行任务;
2、登录档分析logwatch的任务:
如果系统发生了软体问题、硬体错误、资安问题等,绝大部分的错误资讯都会被记录到登录档中,因此系统管理员的重要任务之一就是分析登录档。但你不可能手动透过vim等软体去检视登录档,因为资料太复杂了!我们的CentOS提供了一只程式『 logwatch 』来主动分析登录资讯,所以你会发现,你的root老是会收到标题为logwatch的信件,那是正常的!你最好也能够看看该信件的内容喔!
3、建立locate的资料库:
在第六章我们谈到的locate指令时,我们知道该指令是透过已经存在的档名资料库来进行系统上档名的查询。我们的档名资料库是放置到/var/lib/mlocate/中。问题是,这个资料库怎么会自动更新啊?嘿嘿!这就是系统的例行性工作所产生的效果啦!系统会主动的进行updatedb喔!
4、man page查询资料库的建立:
与locate资料库类似的,可提供快速查询的man page db也是个资料库,但如果要使用man page资料库时,就得要执行mandb才能够建立好啊!而这个man page资料库也是透过系统的例行性工作排程来自动执行的哩!
5、RPM软体登录档的建立:
RPM (第二十二章)是一种软体管理的机制。由于系统可能会常常变更软体,包括软体的新安装、非经常性更新等,都会造成软体档名的差异。为了方便未来追踪,系统也帮我们将档名作个排序的记录呢!有时候系统也会透过排程来帮忙RPM资料库的重新建置喔!
6、移除暂存档:
某些软体在运作中会产生一些暂存档,但是当这个软体关闭时,这些暂存档可能并不会主动的被移除。有些暂存档则有时间性,如果超过一段时间后,这个暂存档就没有效用了,此时移除这些暂存档就是一件重要的工作!否则磁碟容量会被耗光。系统透过例行性工作排程执行名为tmpwatch的指令来删除这些暂存档呢!
7、与网路服务有关的分析行为:
如果你有安装类似WWW伺服器软体(一个名为apache的软体),那么你的Linux系统通常就会主动的分析该软体的登录档。同时某些凭证与认证的网路资讯是否过期的问题,我们的Linux系统也会很亲和的帮你进行自动检查!
at:定时,一次性
at是个可以处理仅执行一次就结束排程的指令,不过要执行at时,必须要有atd这个服务(第十七章)的支援才行。
在某些新版的distributions中,atd可能预设并没有启动,那么at这个指令就会失效呢!
atd 是服务,at 是命令。
atd 服务
先安装命令:yum -y install at
1 | systemctl status atd #===> 查看状态 |
at 工作流程
at 的工作情况其实是这样的:
1、先找寻/etc/at.allow这个档案,写在这个档案中的使用者才能使用at ,没有在这个档案中的使用者则不能使用at (即使没有写在at.deny当中);
2、如果/etc/at.allow不存在,就寻找/etc/at.deny这个档案,若写在这个at.deny的使用者则不能使用at ,而没有在这个at.deny档案中的使用者,就可以使用at咯;
3、如果两个档案都不存在,那么只有root 可以使用at 这个指令。
at 使用方法
1 |
|
at 使用案例
1 | 范例一:再过五分钟后,将/root/.bashrc寄给root自己 |
事实上,当我们使用at时会进入一个at shell的环境来让使用者下达工作指令,此时,建议你最好使用绝对路径来下达你的指令,比较不会有问题喔!由于指令的下达与PATH变数有关,同时与当时的工作目录也有关连(如果有牵涉到档案的话),因此使用绝对路径来下达指令,会是比较一劳永逸的方法。为什么呢?举例来说,你在/tmp下达『 at now 』然后输入『 mail -s “test” root < .bashrc 』,问一下,那个.bashrc的档案会是在哪里?答案是『 /tmp/.bashrc 』!
因为 at在运作时,会跑到当时下达at指令的那个工作目录的缘故啊!
有些朋友会希望『我要在某某时刻,在我的终端机显示出Hello的字样』,然后就在at里面下达这样的资讯『 echo “Hello” 』。等到时间到了,却发现没有任何讯息在萤幕上显示,这是啥原因啊?这是因为at的执行与终端机环境无关,而所有standard output/standard error output都会传送到执行者的mailbox去啦!所以在终端机当然看不到任何资讯。那怎办?没关系,可以透过终端机的装置来处理!假如你在tty1登入,则可以使用『 echo “Hello” > /dev/tty1 』来取代。
由于at工作排程的使用上,系统会将该项at工作独立出你的bash环境中,直接交给系统的atd程式来接管,因此,当你下达了at的工作之后就可以立刻离线了,剩下的工作就完全交给Linux管理即可!
atq,atrm:at 工作管理
1 |
|
batch:系统有空时才进行背景任务
其实batch是利用at来进行指令的下达啦!只是加入一些控制参数而已。
这个batch神奇的地方在于:他会在CPU的工作负载小于0.8(80%)的时候,才进行你所下达的工作任务啦!
因为CPU仅负责一个工作嘛!如果同时执行这样的程式两支呢?CPU的使用率还是100% ,但是工作负载则变成2了!了解乎?
1 | [root@study ~]# uptime |
使用uptime 可以观察到1, 5, 15 分钟的『平均工作负载』量,因为是平均值
crontab:定时,循环
crontab这个指令所设定的工作将会循环的一直进行下去!可循环的时间为分钟、小时、每周、每月或每年等。
crontab除了可以使用指令执行外,亦可编辑/etc/crontab来支援。至于让crontab可以生效的服务则是crond这个服务喔!
crond 是服务,crontab 是命令。
ctond 服务
1 | systemctl status crond #===> 查看状态 |
crontab 工作流程
为了安全性的问题, 与at 同样的,我们可以限制使用crontab 的使用者帐号喔!使用的限制资料有:
/etc/cron.allow
将可以使用crontab的帐号写入其中,若不在这个档案内的使用者则不可使用crontab;
/etc/cron.deny
将不可以使用crontab的帐号写入其中,若未记录到这个档案当中的使用者,就可以使用crontab 。
与at 很像吧!同样的,以优先顺序来说, /etc/cron.allow 比/etc/cron.deny 要优先, 而判断上面,这两个档案只选择一个来限制而已。
因此,建议你只要保留一个即可,免得影响自己在设定上面的判断!一般来说,系统预设是保留/etc/cron.deny , 你可以将不想让他执行crontab 的那个使用者写入/etc/cron.deny 当中,一个帐号一行!
当使用者使用crontab这个指令来建立工作排程之后,该项工作就会被纪录到/var/spool/cron/里面去了,而且是以帐号来作为判别的喔!
举例来说, root 使用crontab后,他的工作会被纪录到/var/spool/cron/root 这个文本文件里头去!但请注意,不要使用vi直接编辑该档案,因为可能由于输入语法错误,会导致无法执行cron喔!另外, cron执行的每一项工作都会被纪录到/var/log/cron这个登录档中,所以啰,如果你的Linux不知道有否被植入木马时,也可以搜寻一下/var/log/ cron这个登录档呢!
crontab 使用方法
1 |
|
预设情况下,任何使用者只要不被列入/etc/cron.deny 当中,那么他就可以直接下达『 crontab -e 』去编辑自己的例行性命令了!整个过程就如同上面提到的,会进入vi 的编辑画面, 然后以一个工作一行来编辑,编辑完毕之后输入『 :wq 』储存后离开vi 就可以了!
而每项工作(每行) 的格式都是具有六个栏位,这六个栏位的意义为:
1 | #项目 含义 范围 |
1 | ---------------------------crontab -e #===> 编辑,等同于【vim /var/spool/cron/$(whoami)】 |
/etc/crontab
基本上,cron这个服务的最低侦测限制是『分钟』,所以『 cron会每分钟去读取一次/etc/crontab与/var/spool/cron里面的资料内容 』,因此,只要你编辑完/ etc/crontab这个档案,并且将他储存之后,那么cron的设定就自动的会来执行了!
注意:
在Linux 底下的crontab 会自动的帮我们每分钟重新读取一次/etc/crontab 的例行工作事项,但是某些原因或者是其他的Unix 系统中,由于crontab 是读到记忆体当中的,所以在你修改完/etc/crontab 之后,可能并不会马上执行, 这个时候请重新启动crond 这个服务吧!『systemctl restart crond』
1 | [root@study ~]# cat /etc/crontab |
MAILTO=root:
这个项目是说,当/etc/crontab这个档案中的例行性工作的指令发生错误时,或者是该工作的执行结果有STDOUT/STDERR时,会将错误讯息或者是萤幕显示的讯息传给谁?预设当然是由系统直接寄发一封mail给root啦!不过,由于root并无法在用户端中以POP3之类的软体收信,因此,鸟哥通常都将这个e-mail改成自己的帐号,好让我随时了解系统的状况!例如: MAILTO=dmtsai@my.host.name
PATH=….:
还记得我们在第十章的BASH当中一直提到的执行档路径问题吧!没错啦!这里就是输入执行档的搜寻路径!使用预设的路径设定就已经很足够了!
『分,时,日,月,周,身份,指令』七个栏位的设定(crontab -e 命令是 6 个栏位喔~!!)
这个/etc/crontab里面可以设定的基本语法与crontab -e不太相同喔!前面同样是分、时、日、月、周五个栏位,但是在五个栏位后面接的并不是指令,而是一个新的栏位,那就是『执行后面那串指令的身份』为何!这与使用者的crontab -e不相同。由于使用者自己的crontab并不需要指定身份,但/etc/crontab里面当然要指定身份啦!以上表的内容来说,系统预设的例行性工作是以root的身份来进行的。
crond 服务读取设定档的位置
一般来说,crond 预设有三个地方会有执行脚本设定档,他们分别是:
1 | /etc/crontab #===> 系统的运作 |
anacron:可唤醒停机期间的工作任务
长时间没执行的任务,可以再次执行。
什么是anacron?
anacron 并不是用来取代crontab 的,anacron 存在的目的就在于我们上头提到的,在处理非24 小时一直启动的Linux 系统的crontab 的执行!以及因为某些原因导致的超过时间而没有被执行的排程工作。
其实anacron 也是每个小时被crond 执行一次,然后anacron 再去检测相关的排程任务有没有被执行,如果有超过期限的工作在, 就执行该排程任务,执行完毕或无须执行任何排程时,anacron 就停止了。
由于anacron 预设会以一天、七天、一个月为期去侦测系统未进行的crontab 任务,因此对于某些特殊的使用环境非常有帮助。举例来说,如果你的Linux 主机是放在公司给同仁使用的,因为周末假日大家都不在所以也没有必要开启, 因此你的Linux 是周末都会关机两天的。但是crontab 大多在每天的凌晨以及周日的早上进行各项任务, 偏偏你又关机了,此时系统很多crontab 的任务就无法进行。anacron 刚好可以解决这个问题!
那么anacron 又是怎么知道我们的系统啥时关机的呢?这就得要使用anacron 读取的时间记录档(timestamps) 了!anacron 会去分析现在的时间与时间记录档所记载的上次执行anacron 的时间,两者比较后若发现有差异, 那就是在某些时刻没有进行crontab 啰!此时anacron 就会开始执行未进行的crontab 任务了!
anacron 与/etc/anacrontab
anacron 其实是一支程式并非一个服务!这支程式在CentOS 当中已经进入crontab 的排程喔!
同时anacron 会每个小时被主动执行一次喔!咦!每个小时?所以anacron 的设定档应该放置在/etc/cron.hourly 吗?嘿嘿!您真内行~赶紧来瞧一瞧:
1 |
|
》》》anacron 使用语法
1 | [root@study ~]# anacron [-sfn] [job].. |
在我们的CentOS 中,anacron 的进行其实是在每个小时都会被抓出来执行一次, 但是为了担心anacron 误判时间参数,因此/etc/cron.hourly/ 里面的anacron 才会在档名之前加个0 (0anacron),让anacron 最先进行!就是为了让时间戳记先更新!以避免anacron 误判crontab 尚未进行任何工作的意思。
接下来我们看一下anacron 的设定档: /etc/anacrontab 的内容好了:
1 |
|
我们拿/etc/cron.daily/ 那一行的设定来说明好了。那四个栏位的意义分别是:
- 天数:anacron 执行当下与时间戳记(/var/spool/anacron/ 内的时间纪录档) 相差的天数,若超过此天数,就准备开始执行,若没有超过此天数,则不予执行后续的指令。
- 延迟时间:若确定超过天数导致要执行排程工作了,那么请延迟执行的时间,因为担心立即启动会有其他资源冲突的问题吧!
- 工作名称定义:这个没啥意义,就只是会在/var/log/cron 里头记载该项任务的名称这样!通常与后续的目录资源名称相同即可。
- 实际要进行的指令串:有没有跟0hourly 很像啊!没错!相同的作法啊!透过run-parts 来处理的!
根据上面的设定档内容,我们大概知道anacron 的执行流程应该是这样的(以cron.daily 为例):
1、由/etc/anacrontab 分析到cron.daily 这项工作名称的天数为1 天;
2、由/var/spool/anacron/cron.daily 取出最近一次执行anacron 的时间戳记;
3、由上个步骤与目前的时间比较,若差异天数为1 天以上(含1 天),就准备进行指令;
4、若准备进行指令,根据/etc/anacrontab 的设定,将延迟5 分钟+ 3 小时(看START_HOURS_RANGE 的设定);
5、延迟时间过后,开始执行后续指令,亦即『 run-parts /etc/cron.daily 』这串指令;
6、执行完毕后, anacron 程式结束。
如此一来,放置在/etc/cron.daily/内的任务就会在一天后一定会被执行的!因为anacron是每个小时被执行一次嘛!所以,现在你知道为什么隔了一阵子才将CentOS开机,开机过后约1小时左右系统会有一小段时间的忙碌!而且硬碟会跑个不停!那就是因为anacron正在执行过去/etc/cron.daily/, /etc/cron.weekly/, /etc/cron.monthly/里头的未进行的各项工作排程啦!这样对anacron有没有概念了呢?^_^
最后,我们来总结一下本章谈到的许多设定档与目录的关系吧!这样我们才能了解crond 与anacron 的关系:
1、crond 会主动去读取/etc/crontab, /var/spool/cron/, /etc/cron.d/ 等设定档,并依据『分、时、日、月、周』的时间设定去各项工作排程;
2、根据/etc/cron.d/0hourly 的设定,主动去/etc/cron.hourly/ 目录下,执行所有在该目录下的执行档;
3、因为/etc/cron.hourly/0anacron 这个指令档的缘故,主动的每小时执行anacron ,并呼叫/etc/anacrontab 的设定档;
4、根据/etc/anacrontab 的设定,依据每天、每周、每月去分析/etc/cron.daily/, /etc/cron.weekly/, /etc/cron.monthly/ 内的执行档,以进行固定周期需要执行的指令。
也就是说,如果你每个周日的需要执行的动作是放置于/etc/crontab 的话,那么该动作只要过期了就过期了,并不会被抓回来重新执行。但如果是放置在/etc/cron.weekly/ 目录下,那么该工作就会定期,几乎一定会在一周内执行一次~如果你关机超过一周,那么一开机后的数个小时内,该工作就会主动的被执行喔!真的吗?对啦!因为/etc/anacrontab 的定义啦!
基本上,crontab 与at 都是『定时』去执行,过了时间就过了!不会重新来一遍~那anacron 则是『定期』去执行,某一段周期的执行~ 因此,两者可以并行,并不会互相冲突啦!
&:后台执行
1 | ------------------------ls |
jobs:后台列表
1 | ------------------------jobs #===> 列出所有后台程序 |
fg,bg:工作恢复
1 | fg(foreground 前台) bf(background)后台 |
kill:杀死进程
1 | 一般使用 kill -9 PID 来杀死进程,也可以使用 kill -9 %n 来杀死后台任务 |
ps:所有 PID
1 | ------------------------ps aux | head | cat -n | sed '2d' |
top:动态观察程序变化
1 | ------------------------top |
- 监控指定 pid:
top -p pid(进程不会占用CPU,只有进程只是占用资源,线程才会占用CPU,进入之后输入H即可查看动单个进程下的所有线程。) - CPU使用排序:输入
top,输入大写字母P - 内存使用排序:输入
top,输入大写字母M
pstree:程序树
1 |
|
nohup:非bash后台执行
1 | nohup 命令 #===> 前台执行 |
uname:系统与核心信息
1 | [root@study ~]# uname [-asrmpi] |
uptime:显示工作负载
和 top 上面显示差不多
1 | ------------------------uptime |
netstat:显示网络,端口
1 | [root@study ~]# netstat -[atunlp] |
fuser:根据文件查进程
1 | [root@study ~]# fuser [-umv] [-k [i] [-signal]] file/dir |
lsof:显示程序所用档案
1 | [root@study ~]# lsof [-aUu] [+d] |
pidof:根据程序找出 PID
1 | [root@study ~]# pidof [-sx] program_name |
SELinux:增强Linux
(Security Enhanced Linux 安全增强Linux)
因为 root 可以为所欲为。所用让某些文件不能访问,即使是 root 也行。
省略。。。详情可以参考SELinux 初探